Unpacking The Starknet Bolt Upgrade
A comprehensive overview of Starknet’s 'Bolt' upgrade, which introduces parallel execution and block packing for improved performance. Learn how these changes boost scalability by reducing confirmation times and lowering costs.

Starknet’s latest upgrade (v0.13.2) named Bolt brings two major changes: parallel execution and block-packing. Although independent of one another, both features support the push towards the goal of fast, cheap blockspace cryptographically secured by Ethereum.
Parallel execution allows non-contentious transactions (i.e., transactions that don’t touch the same state) to execute concurrently. By implementing parallel execution, L2s like Starknet can reduce execution time without increasing resource usage. This means lower transaction fees for users and significantly improved transaction confirmation times.
Block packing optimizes Starknet’s usage of blobspace on Ethereum L1: with block packing, sequencers can generate one proof to verify multiple Starknet L2 blocks simultaneously. This decouples usage of blobspace from the frequency of L2 block production and amortizes proof verification costs. Both reduce operating costs for the Starknet sequencer, which means users pay less per transaction.
Like we said, Bolt makes Starknet cheaper and faster! This report will provide a detailed analysis of the Bolt upgrade–focusing on parallel execution and block packing–and explore the implications for Starknet’s performance.
A quick refresher on rollups
Rollups are layer two (L2) scaling solutions that aim to scale the underlying layer one (L1) blockchain by moving computation off-chain. By moving execution off-chain, rollups can optimize for scalability (cheap and fast transactions), while the L1 provides security for L2 transactions.
Rollups are often said to “inherit security from the L1”. What this essentially means is that they inherit the consensus and data availability guarantees provided by the L1. In addition to this, the L1 also provides a security guarantee in the form of secure bridging between it and the rollup.
When sequencers publish L2 blocks to the L1, the L1 provides guarantees of the availability as well as the ordering of this information. From here, L2 nodes can trustlessly compute the canonical L2 chain with this information along with the rollup’s rules around chain derivation and state transition described by the node implementation.
In order to facilitate secure bridging between the L1 and the L2, the L1 requires proof that the L2 chain it is currently following is correct and does not include illegal state changes (e.g. double spend). This need for rollups to prove the validity of state changes, ensures the L1 does not authorize withdrawals from the rollup based on illegal state.
Rollups differ based on how they prove validity of state changes to the L1:
- Validity rollups rely on validity proofs to objectively verify correctness of execution. Proposers are allowed to propose a new rollup state if they submit a validity proof to the rollup contract.
- Optimistic rollups rely on the absence of a fraud proof to subjectively verify correctness of execution. Proposers submit state updates without proofs, but the rollup contract can roll back any state update whose validity is successfully challenged by a fraud proof.
Rollups also provide the base layer with enough data for interested parties to reconstruct the L2 state. While optimistic rollups must publish full transaction data to enable challengers to compute fraud proofs, validity rollups have no such requirements (validity proofs guarantee correct execution). But posting full transaction data on L1 is still useful from a trust-minimization perspective (trustless reconstruction of state and permissionless withdrawals).
Starknet is a validity rollup that uses Scalable, Transparent ARgument of Knowledge (STARKs) to prove the validity of state changes. The latest upgrade to Starknet–codenamed Bolt–adds parallel execution and block packing. In subsequent sections, we’ll explain how the two features work and what improvements they bring for Starknet users.
What did the Starknet Bolt upgrade change?
At a high level, the Bolt upgrade changed Starknet’s execution, proving and data availability mechanisms.
Optimizing execution
Before the Bolt upgrade, Starknet transactions were executed sequentially—one after the other–by the sequencer. Sequential execution is simple but also very inefficient. It’s inefficient because it does not take advantage of the multiple independent processing units that modern day computers offer and the parallelizability of a set of transactions.
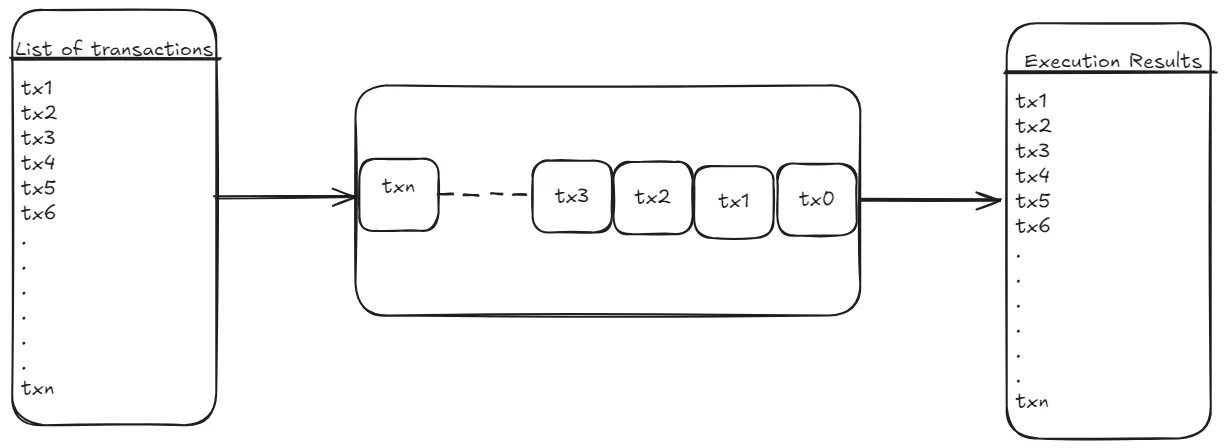
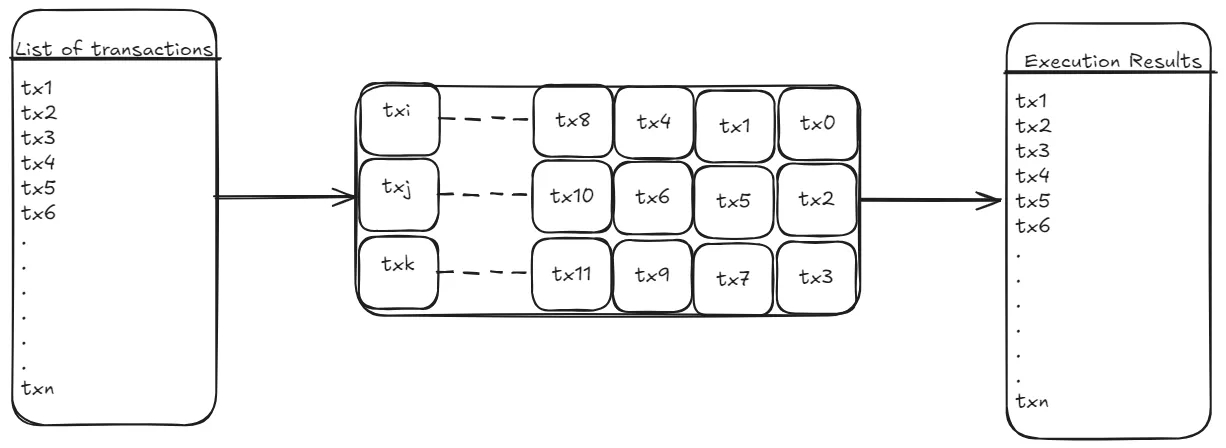
Parallelizability is a measure of how independent the transactions in a given set are. For example, consider the set of three transactions below:
- Transaction 1: Alice wants to send Bob 1 STRK
- Transaction 2: Caitlyn wants to send Danny 100 ETH
- Transaction 3: Caitlyn wants to send Ella 100 ETH
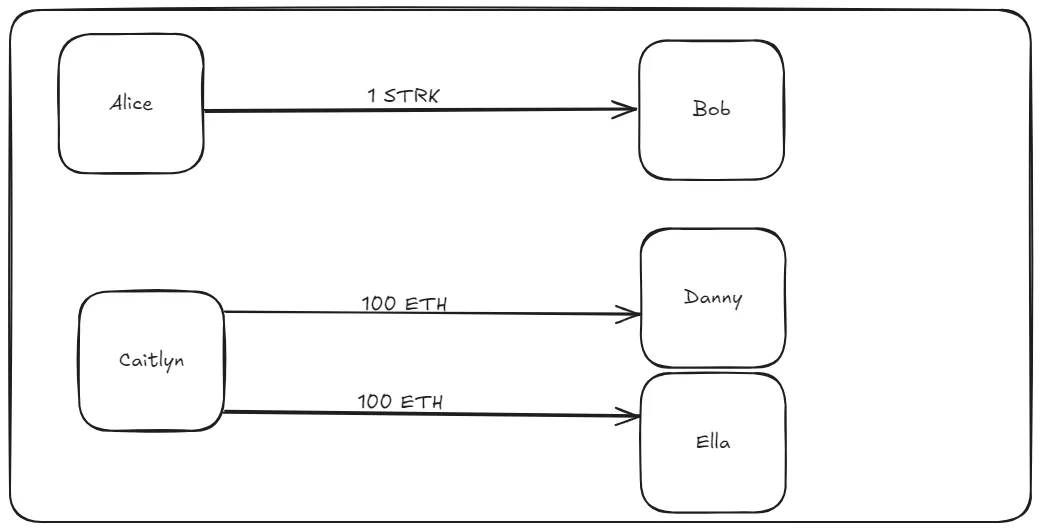
Transaction 1 is completely independent of transactions 2 and 3–because it is accessing a different part of the state (Alice’s balance)–and can be executed concurrently. However, transaction 2 and 3 are conflicting because they want to access the same state—Caitlyn’s ETH balance. These transactions can not be executed concurrently or we’ll end up with conflicting results.
To illustrate:
- Say Caitlyn’s balance is 300 ETH and transactions 2 and 3 start at the same time. Both transactions will read the initial balance of Caitlyn’s account as 300 ETH, deduct the transfer amount from it (300 - 100 = 200), and write 200 ETH to the location in memory where Caitlyn’s account balance is stored.
- Transactions 2 and 3 will then read Danny and Ella’s balances respectively and add 100 ETH to both users’ balances. Caitlyn’s balance would reduce by 100 ETH, but 200 ETH would be credited–effectively printing 100 ETH out of thin air.
Avoiding these types of conflicts (and the complex nature of mitigation mechanisms) is why Ethereum chose sequential execution. However, while sequential execution reduces complexity and improves security, it results in inefficient use of hardware. Worse still, the trend of hardware design suggests sequential execution will become increasingly inefficient in the coming years.
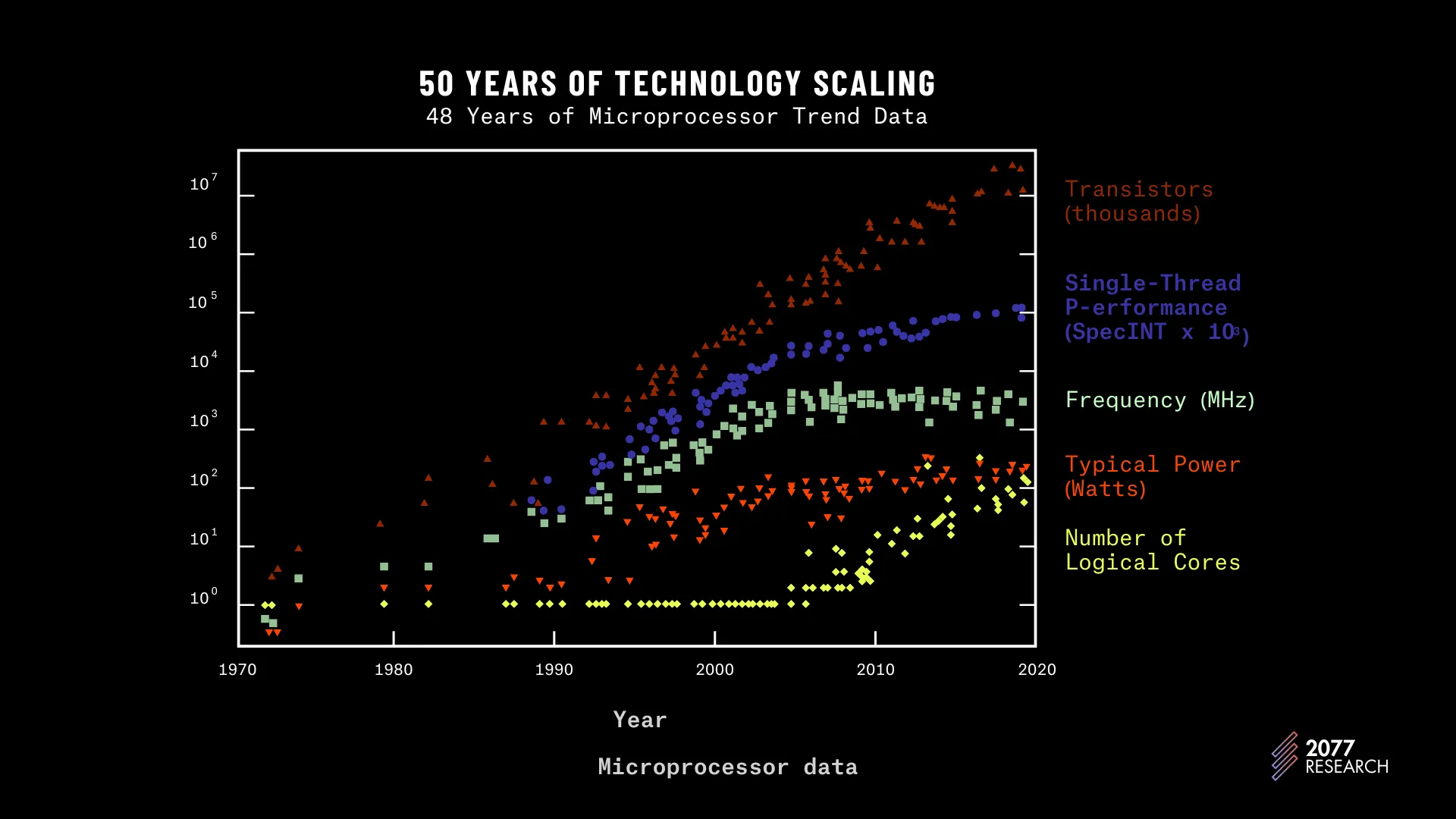
Figure 4 shows the trend of hardware design in the last 50 years. The relevant takeaway? Single-thread performance (purple circles) has been plateauing since the mid 2000s while the number of logical cores has increased around the same time. We can make two conclusions based on this data:
- Hardware designers are scaling computer chips by adding more independent processing units rather than improving the performance of a single unit.
- Any system that continues to rely on increased performance of a single processing unit will experience a stall in performance gains even on newer hardware.
In recent years, sophisticated algorithms for managing transaction conflicts and ensuring correctness of parallel execution have appeared. Block-STM (based on a paper by Fikunmi et al*) is one such algorithm and forms the core part of Starknet’s new parallel execution engine. We analyze the Block-STM algorithm in later sections.
Optimizing proving and data availability
Starknet’s SHARP (short for Shared Prover) has always taken advantage of recursive proofs to reduce verification costs as much as possible. A recursive proof is essentially a “proof of proof” where one proof verifies that one or more proofs are correct. Below is a sketch of how SHARP generates a recursive proof:
- The SHARP system takes a set of programs to be executed (a “job”) as input and generates a proof of execution for the job.These “programs” are L2 blocks and the proof attests to correctness of transactions.
- The proof is sent to another program that verifies the proof and converts the proof verification program into a job. SHARP takes the new job as input and generates another proof (this proof confirms the validity of the previous proof).
- The process (proof → job → proof) restarts and continues until a target is reached at which point the final proof (which is now a highly compressed version of the original proof) is posted to the L1
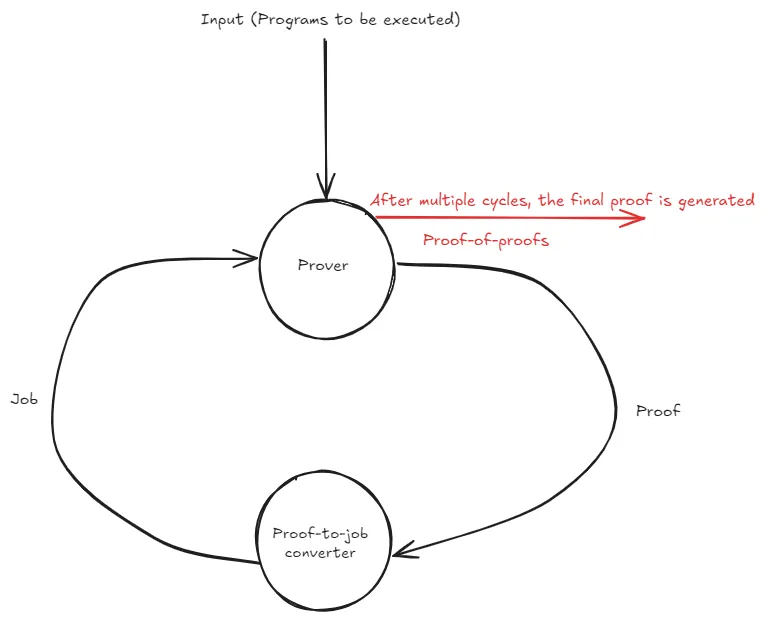
This design greatly amortizes costs for two major reasons:
- The subsequent jobs* are not individual programs or transactions and proving costs grow sub-linearly. This means the larger the number of programs/transactions within a job, the greater the savings. By creating proofs per block instead of per transaction, transaction fees can be much cheaper.
- Recursion greatly compresses the proofs resulting in a “proof of proof” that is significantly cheaper to verify on the L1 than the initial proof or any of the intermediate proofs.
While the proving system was good, there were missed chances to further save costs. For example, each job was a single Starknet block and each of these blocks were designed to take up one blob on the L1. This resulted in certain inefficiencies as described below:
Prior to Bolt, Starknet did (and still does) not have regular blocktimes; instead an L2 block was published to the L1 under two conditions: (1) One blob’s worth of data was executed (2) Six minutes had elapsed from the previous block. Unfortunately, due to demand, most of the blocks were sent to the L1 because of the six minute limit (not DA limits).
The above meant that blobs (not blocks) were often (severely) underutilized, resulting in unnecessarily high gas costs. Starknet blocks also had a fixed cost, which could theoretically be reduced by applying the same recursion techniques discussed above to produce proofs of multiple blocks.
Block packing tackles these problems by using a binary tree of recursive proofs. We discuss block packing in a later section of the article.
Bolt Part 1: Parallel Execution
As discussed earlier, sequential execution is inefficient (and will only be more inefficient as time goes on) and naive parallel execution produces invalid results. Production parallel execution engines take care to prevent inconsistent results, however.
There are two approaches to tackling parallel execution: Pessimistic Concurrency Control (PCC) and Optimistic Concurrency Control (OCC). PCC and OCC are transaction processing units (TPUs). Below is a definition of a transaction processing unit from Block-STM vs. SVM: A Comparison of Parallel Execution Engines:
The TPU is usually coupled with, but distinct from the Virtual Machine (VM). Blockchain VMs like the EVM, SVM, and MoveVM are high-level language VMs…The TPU, which is usually the subject of interest, subsumes the VM. It is tasked with the management of the entire transaction execution pipeline, including creating and managing instances of the VM.
Pessimistic concurrency control is designed based on the assumption that many of the transactions within the set of transactions to be executed will conflict, i.e., they will touch the same state. PCC prevents these conflicts.
To prevent conflicts, PCC requires that a transaction declare upfront what portions of state it will access during read/write operations. The transaction processing unit can use this information to schedule transactions in a way that ensures that conflicting transactions are executed sequentially (instead of concurrently). Some TPUs also use locks to enforce this behavior (a lock (a.k.a., mutex) is a mechanism used to prevent concurrent access to a memory location)
That said, PCC-based execution incurs certain tradeoffs. First, the requirement to provide access lists (which identify the memory slot a transaction touches) degrades the developer experience and reduces the range of possible applications. Second, scheduling transactions can incur unnecessary overhead–especially when there are no conflicts.
Optimistic concurrency control is designed with the assumption that many of the transactions within the given set will not conflict, i.e. they will not write to the same state. As such, OCC TPUs execute the set of transactions with all the available resources and only try to detect conflicts. If a conflict is detected the transactions that conflict are executed and reverified until the entire set passes and can be committed.
OCC TPUs don’t incur overhead from scheduling, so they tend to perform better when there are few conflicts. OCC-based transaction processing units also have better developer experience and a wider range of use cases because state dependencies don’t need to be known upfront.
However, when the setof transactions are highly contentious, OCC performs worse than PCC. We cover TPU designs (in far more detail) and compare the OCC and PCC approaches in our article on parallel execution.
Starknet’s new TPU uses the OCC approach. More specifically, it is an implementation of the Block-STM algorithm. Block-STM executes transactions optimistically with all the available resources assuming none of them will conflict and verifies after execution that no conflicting transactions executed concurrently. Before we dive into Starknet’s new architecture, it’s important to go over some key definitions:
- State: State is the condition of an object at an instance in time. In the blockchain context it usually refers to the value of a portion of memory, e.g., the balance of an address is (part of) its state.
- Serializability: Parallel execution is said to have preserved the property of serializability if executing a set of transactions serially and concurrently produces the same results.
- Conflict: Two transactions are said to conflict if and only if at least one of them wants to write to a portion of state that both want to access (can be read or write). If both transactions are only reading from a portion of state, then there’s no conflict but if at least one of them is writing to that portion of state, then the transactions can not be executed concurrently without breaking serializability. We covered a sample case above in the Caitlyn, Danny and Ella example.
- Dependency: A transaction
txjis said to be dependent on (or a dependency of) a transactiontxiif and only if both transactions write to the same memory location andtxjcomes aftertxiin the serial ordering. Iftxicame aftertxj,txiwould be dependent ontxj. - Multi-version data structure: A multi-version data structure is one where a new version of the data structure is created for each write to the data structure. Instead of changing the value in place, a new write-specific version of the location to be changed is created. The value prop of multi-version data structures is that they allow highly concurrent reads from and writes to the same region in memory. We’ll explore how this is useful later.
With the definitions out of the way we can move on to cover how Block-STM works.
How Block-STM works
The input to Block-STM is a queue (an ordered list) of transactions, this list is often called a BLOCK. This list can be ordered in any manner; the only requirement is that there is a clearly defined order. So given a set of transactions T containing transactions {t0…tn}, the transactions are sorted such that {t0 > t1 > t2 … > tn} (read as t0 is of higher priority than t1, t1 is of higher priority than t2 etc.)
At the beginning of the execution process, two sets are created—an execution set E, and a validation set V. E tracks transactions that are yet to be executed while V tracks transactions that have been executed but are yet to be validated.
Each transaction is also associated with an incarnation number n to track how many times it has been executed (and re-executed). The initial state of the sets is that E contains all the transactions and V is empty, i.e., E = {t0,1 > t1,1 > t2,1 > … > tn,1} and V = {}
With these ordered sets of transactions, each thread used for execution cycles through a three stage loop:
- Check Done
- Find Next Task
- Perform Task
Check Done
During this step, the thread checks both V and E. If both are empty and no transaction is being executed then the current batch of transactions has been executed completely and the results can be committed to storage.
Find Next task
If either V or E contains transactions, Block-STM selects the transaction with the lowest index (not incarnation number) from both set of transactions, i.e., if E contains {t1,3 , t3,1 and t5,2} and V contains {t0,1, t2,4, t4,3}, the validation task for transaction t0 would be selected as the next task.
Perform Task
Once the next task has been identified and selected, it is performed. At the end of this step, the algorithm loops back to Check Done. This process continues until both sets of transactions are empty.
Let’s look at what happens during execution and validation.
During execution of a transaction, the Block-STM algorithm populates two sets (per transaction); a read set (Ri,n) and a write set (Wn,i). The read set contains all the memory locations that a transaction read from during its execution while the write set contains all the memory locations it wrote to. During execution, the transactions apply their writes to the multi-version data structure, but reading is a little nuanced.
In Block-STM when a transaction wants to read from the data structure, it checks for the value written by the lowest priority transaction that has higher priority. For example if tx1, tx2, and tx7 have all written to a memory location and tx5 wants to read from this location, it reads the version of the data structure corresponding to tx2.
This is done to enforce serializability; since tx5 should be executed after tx2 and before tx7, it should use the values written by tx2 not tx7. In this example, tx7 will have to be re-executed because it should have read the values written by tx5, not tx2 or any higher priority transactions. If a single-version data structure was used, the value written by tx2 would be unavailable and a conflict is sure to occur.
For a validation task, the transaction’s read set is compared to the current values at the memory locations it read from during execution. For example, if tx2 reads account B during execution, during validation, the memory location for account B is read (keeping the definition of read we established earlier in mind). If the two values are the same then it means that no higher priority transaction (say tx0 or tx1) has written to that location during the execution of tx2. This results in tx2 marked as validated but not safe to commit.
The transaction is not considered safe to commit because a lower priority transaction could, for any number of reasons, be executed after the transaction had been validated. In our running example if tx1 touches account B and only touches it after, tx2 passes validation then tx2 needs to be re-executed.
To provision for this, anytime a transaction completes execution all lower priority transactions that had passed validation are revalidated to ensure they do not conflict with the transaction. For example, if tx1, tx3 and tx4 have been validated and tx2 completes execution, tx3 and tx4 must be revalidated to ensure that they do not conflict with (and so are dependencies of) tx2.
If a transaction fails validation, i.e., a higher priority transaction that writes to the same state was executed concurrently with it, then the writes that the transaction made are dirty (because the values are wrong.) But instead of deleting these values from the database completely, they are flagged ESTIMATE.
The ESTIMATE flag tells any transaction reading that memory location that the values there are not correct and the transactions pause their execution. This is done in place of deletion because re-execution of the transaction that failed validation would likely result in writing to the same memory locations as the previous execution.
By marking the memory location as an estimate instead of deleting it, dependencies (of the transaction that failed validation) can be caught even before re-execution, preventing unnecessary re-executions. This heuristic greatly reduces wasted work.
Putting it all together
A complete overview of how Block-STM approaches parallelization can be summarized as:
- A BLOCK of transactions start out as an ordered list with a clearly defined serial order. These transactions are executed on all the available resources in priority order.
- During execution, the read and write sets of the transactions are tracked and reads and writes are performed from/to a multi-version data structure. When a transaction finishes execution, it is validated to ensure that it did not execute concurrently with any conflicting transactions.
- If a transaction passes validation, then it is removed from E and V. And when a transaction is validated, all transactions lower in priority than it that had passed validation are rescheduled for validation.
- If a transaction fails validation then it is rescheduled for execution. When the entire set of transactions have been executed and validated then the entire BLOCK is safe to commit and the results can be written to permanent storage.
An example is shown below:
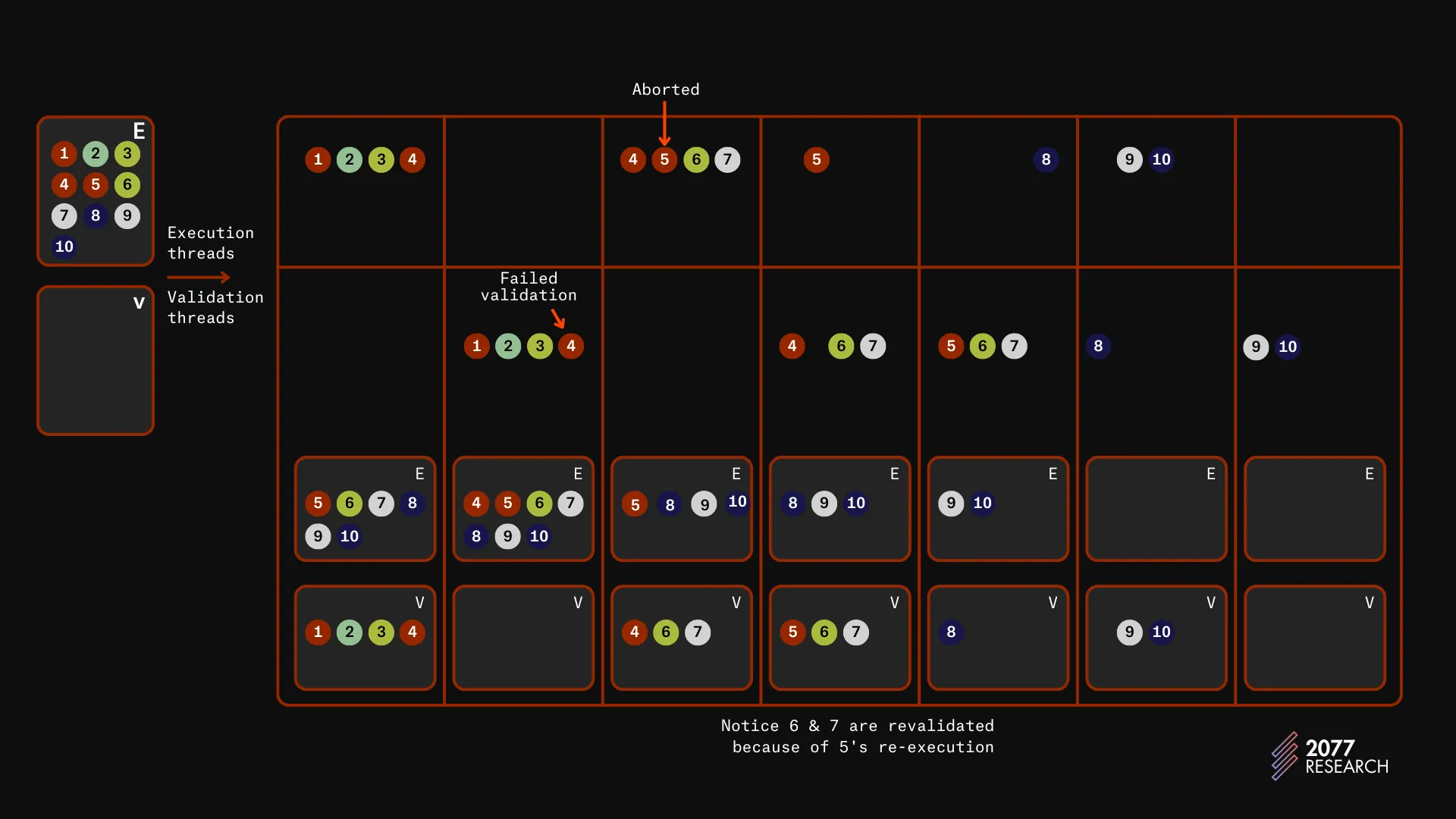
That is an overview of how Block-STM works, more details can be found in our report here and the original Block-STM paper here.
How does Block-STM improve Starknet performance?
To quantify the significance of adding Block-STM, we performed a few benchmarks to evaluate the performance improvements it provides over sequential execution and the results are shown below.
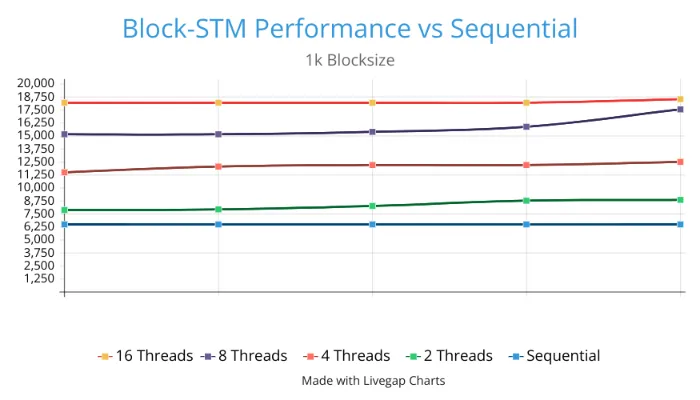
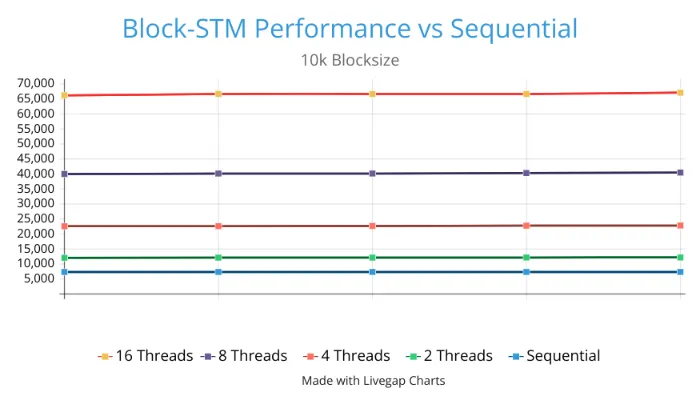
The results show that as the number of threads (analogous to independent processing units) used increases, performance also increases. The improvements are more pronounced with larger blocks giving as high as 9X performance improvements over sequential execution with just 16 threads. We found that the results are more pronounced with larger blocks.
Our tests show that Block-STM performance does significantly degrade under highly contentious load but industry-standard practice is to fall back to sequential execution during such periods. We recommend the same mechanic to Starknet to preserve throughput under highly contentious workloads. But, by and large, the addition of Block-STM will significantly improve and futureproof Starknet.
The second major change bundled in the v0.13.2 upgrade is block packing and we’ll cover that next.
Bolt Part 2: Block Packing
As discussed earlier, prior to Bolt, each Starknet block was its own job resulting in a fixed per-block cost for every block. In addition, the system was designed such that each block required its own blob regardless of how much data was actually consumed by the block.
In a world where there was always high demand, this wouldn’t be a problem, but Starknet currently offers more blockspace than there is demand for and so there are a lot of wasted resources that could result in hundreds of ETH lost over the course of a month. To further put into context the severity of the situation before Bolt, these are the costs associated with posting a block to L1.
- 23K gas per fact registration – part of Verify Proof and Register
- 56K gas per register SHARP memory page
- 136K gas per State Update
- 50K gas for the KZG precompile to sample a blob,
- 86K gas for running the state update function.
This totals out to 215k gas per block and this cost is flat, i.e., it’s the same regardless of how much data each block contains and related to the number of blocks by $Cost = num blocks * 215000$. The ideal solution to this problem would be for costs to be related to the amount of data posted instead of the amount of blocks. And that’s exactly what block packing achieves via SNAR trees.
SNAR Tries
Starknet Applicative Recursive (SNAR) trees are a new type of binary tree introduced in Bolt to address the problems highlighted above. A SNAR Tree has the following structure: each leaf is a Starknet block and the nodes in all other levels are recursive proofs of their children. The root node which is a recursive proof of all other proofs is the final job that is sent to the SHARed Prover (SHARP).
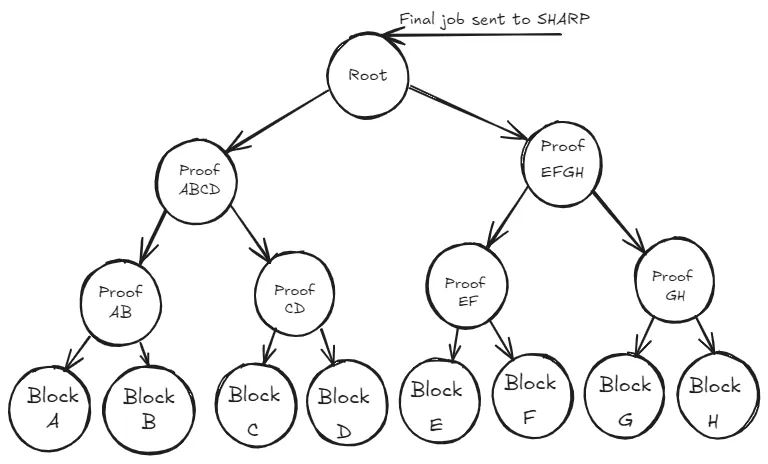
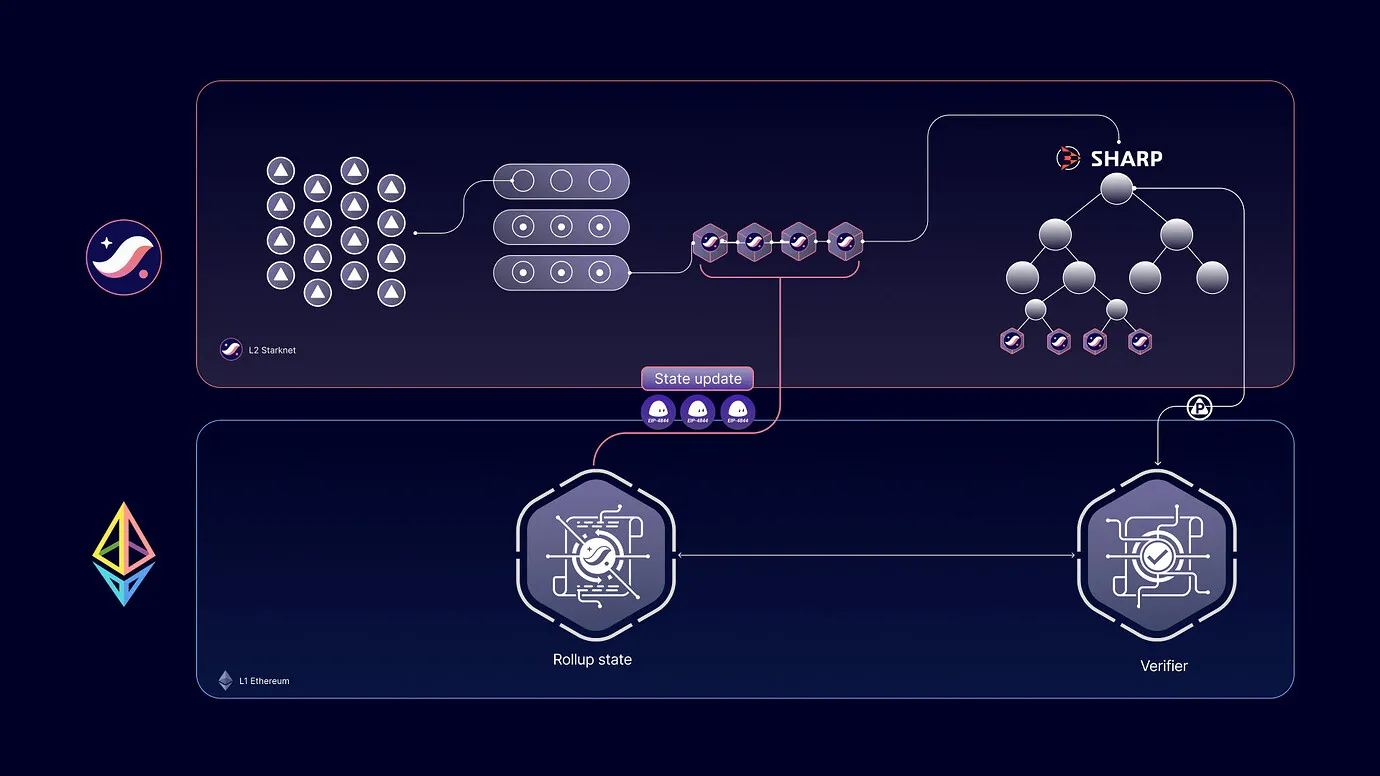
What does the SNAR Tree do?
The primary benefit of the SNAR Tree is that rather than posting one block per proof, many Starknet blocks can be amortized into the same L1 update. SNAR tree roots are now posted to the L1 only when one of two configurable limits is hit: either the DA limit (6 blobs worth of data) or after a certain number of leaves are added to the tree (where a leaf is a block).
This design decouples the cost for transactions from the number of blocks. Now, there is still some fixed cost for each block that arises from running the StarkNet OS (SNOS) in every block–but by and large the costs are decoupled. These are the numbers now:
- SHARP memory registration per-job: 23K gas, (same as before)
- SHARP memory page per-job: 36K gas (reduced from 56K thanks to SHARP optimization),
- State update per-job equal to:
- 86K gas (same as before) +
- 50K gas × number of blob used. (When one blob was used per block this was 50K x 1 resulting in the 136 K gas number quoted above).
The plot in Figure 11 below shows how gas costs vary with block number in the previous design and now (under Bolt):
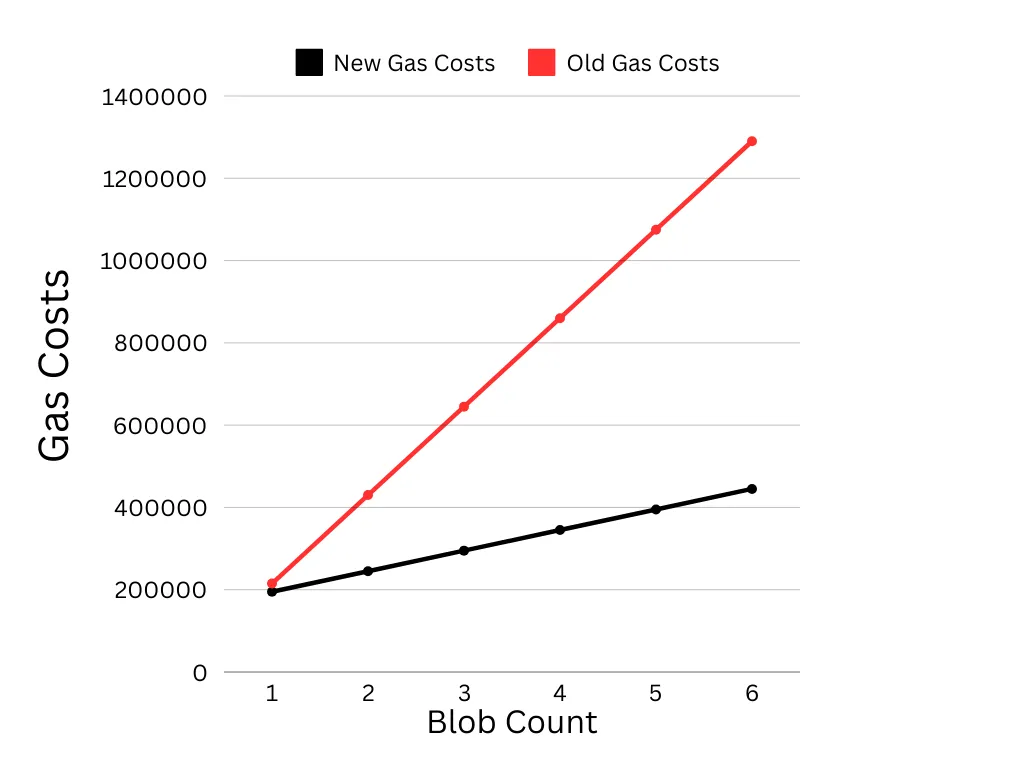
It’s fairly obvious that block packing greatly reduces the costs of verification on the L1 which will undoubtedly result in lower gas prices for Starknet users.
Conclusion
The effect of the changes made in Bolt: optimistic parallel execution via Block-STM and block-packing through the proprietary SNAR can be summarized as: faster and cheaper.

Parallel execution reduces execution time and by extension congestion which will reduce gas fees during periods of high traffic, while SNAR trees tackle the associated DA and proving costs. Interestingly, this upgrade makes Starknet the first L2 with parallel execution and sets it up to be a major contender in the L2 space. It’s important to note that it’s unlikely that the effect of these changes will be immediately evident, especially that of parallel execution, but they are crucial to future-proofing Starknet and the entire Ethereum ecosystem as a whole.
You can find more information about Bolt and Starknet here.



