Block-STM vs. Sealevel: A Comparison of Parallel Execution Engines
Compare Block-STM and Sealevel: two high-performance parallel execution engines powering Sui and Solana. Dive into their design, speed, and trade-offs.

Aptos’ Block-STM and Solana’s Sealevel are antagonistic approaches to parallelizing blockchain execution. Block-STM uses an Optimistic Concurrency Control (OCC) approach, i.e., the Transaction Processing Unit (TPU) (optimistically) assumes that no transactions executed concurrently will conflict and relies on in-built checks and logic to identify and resolve conflicts. Sealevel, on the other hand (pessimistically), assumes that transactions will conflict and relies on lock-based synchronization to prevent conflicts.
The Pessimistic Concurrency Control (PCC) approach has historically been more performant in distributed database systems and for intuitive reasons too—a TPU that schedules transactions in a manner that prevents conflict should perform better than an TPU that has to resolve conflicts after the fact. However, thanks to clever design and engineering, Block-STM performs surprisingly well, with the added benefits of allowing arbitrary logic and, by extension, a greater range of use cases and a superior devex.
This paper will examine and break down how both TPUs approach parallelization at a relatively low level and evaluate their performance and scalability. It will also provide an unbiased evaluation of the strengths and weaknesses of both TPUs.
The paper is written with the assumption that the reader is familiar with blockchain concepts like transactions, blocks, and consensus. Familiarity with distributed databases and computer architecture will help with groking some of the concepts but the glossary explains unfamiliar terms and the main body and appendix contain “primers” on unfamiliar subjects.
Common terms
A few terms will come up often so let’s quickly breakdown what they mean in the context of this paper:
- concurrency and parallelism: concurrency refers to multiple processes using the same resource(s). Parallelism is multiple processes running completely independent of one another. Programs can have any combination, none, or both of the properties.
- transactions: a transaction is an atomic set of instructions that performs a logical operation. The instructions referenced here are analogous to low-level computer instructions but they do far more than a computer instruction.
- conflict: two or more transactions are said to conflict when they modify/access the same portion of state. Specifically, a conflict occurs when at least one transaction tries to write to the contended portion of state; if all the transactions are reading, then they don’t conflict.
- state: state describes the condition of a thing at an instance in time. In the context of blockchains, state is the set of accounts and their associated data (balances and code). When memory access/modification is mentioned, memory refers to state.
- dependencies: transaction B is said to be a dependency of transaction A if and only if:
- transaction B conflicts with A,
- transaction B is of lower priority than A. (If B were of higher priority, A would be a dependency of B.)
- lock: a lock or
mutex, is a mechanism used to prevent concurrent access to a memory location. When a transaction/process wants to access a memory location in lock-based systems, it attempts to grab the lock for the associated location; if the location is already locked, the lock grab fails and the transaction must wait. - locking granularity: refers to how fine memory locks are. Imagine a transaction needs to alter an element in a table; a coarse lock could lock the entire table; a more granular lock could lock the row/column of interest; and a very fine lock could lock only the cell of interest. The more granular a lock is, the more concurrent memory access can be, but highly granular locks are more difficult to manage because they require a larger key-value database to manage portions of memory.
- serializability (of transactions): a set of transactions executed concurrently is said to be serializable if there exists a sequential execution of the same set of transactions that produces the same result.
With all of that out of the way, we can get started.
Introduction
A “blockchain network” is a decentralized, byzantine-fault-tolerant distributed database. The Transaction Processing Unit (TPU) is the component responsible for computing state transitions; it takes transaction data as input and outputs an ordered list of transactions and a (succinct) representation of the execution results (usually the blockhash).
The TPU is usually coupled with, but distinct from the Virtual Machine (VM). Blockchain VMs like the EVM, SVM, and MoveVM are high-level language VMs. That means they convert bytecode (compiled intermediate representations) of the high-level languages (Solidity, Rust, Move) to machine executable code. A blockchain VM is fundamentally the same as the more familiar emulation VMs; it's a sandboxed environment that allows a non-native instruction set (blockchain bytecode) to be executed on actual hardware (x86/ARM) .
The TPU, which is usually the subject of interest, subsumes the VM. It is tasked with the management of the entire transaction execution pipeline, including creating and managing instances of the VM. So, as mentioned earlier, these terms are related but distinct. The TPU, specifically, is the focus of this paper.
There are two types of TPUs: sequential and parallel. A sequential TPU is the easiest to design and implement. Sequential TPUs process transactions first-in-first-out (FIFO). This approach is very simple and incurs no scheduling overhead, but sequential TPUs don't take full advantage of the state and trend of computer hardware design.
Computer hardware has been approaching the limits of single-processor performance since the mid-2000s, and there has been an industry-wide shift towards scaling by increasing the number of cores. If there are no breakthroughs in computing, computers will continue to improve performance by adding more cores as opposed to frequency scaling. And in such a world, sequential TPUs will fail to maximize (even consumer) hardware and execution will quickly become a bottleneck.
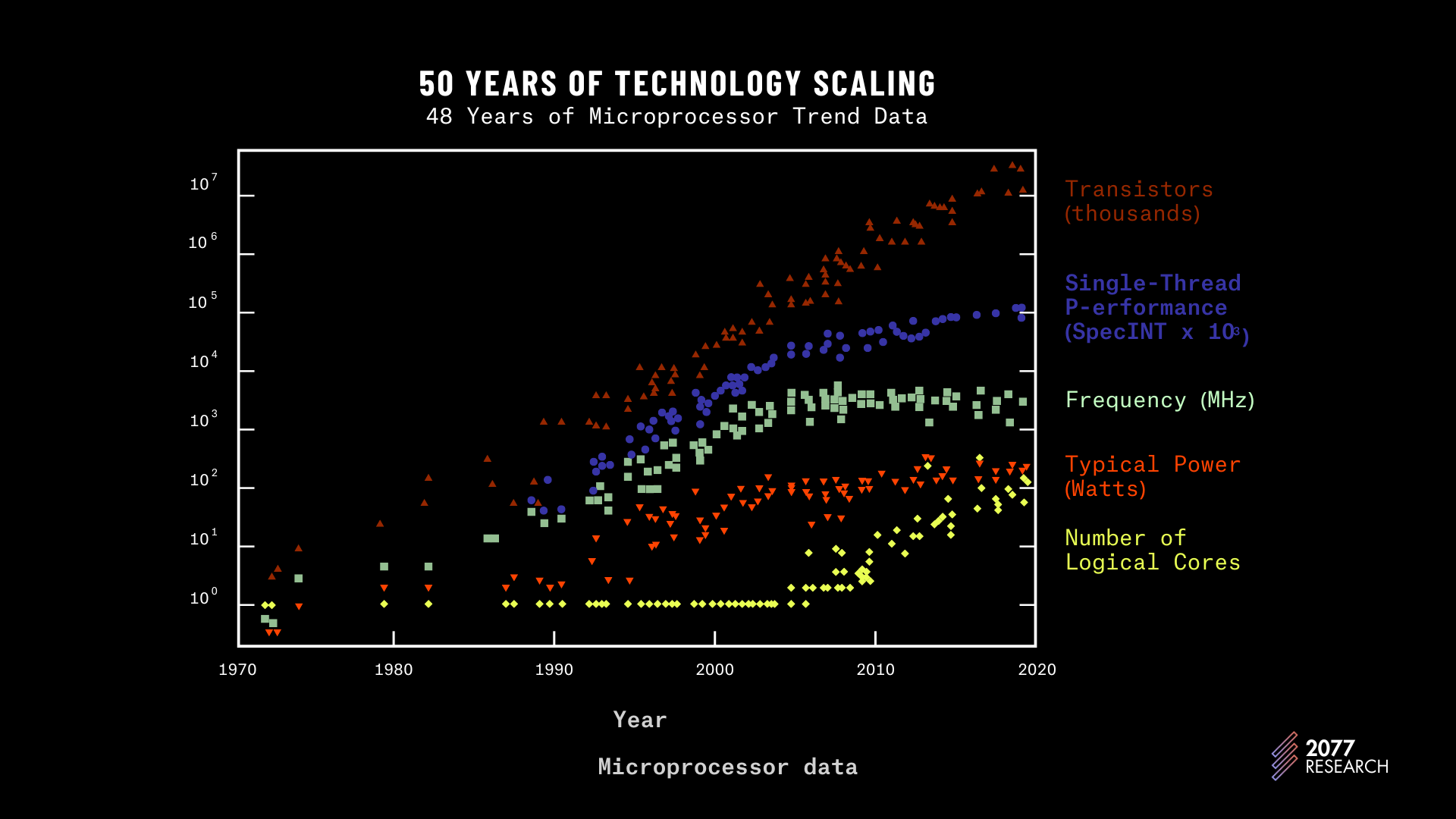
Figure 1 shows the trend of single thread performance (blue dots) and frequency (green squares), both of which have slowed down and are even seeming to trend slightly downward. The yellow diamonds show the number of “logical cores,” and this number has been steadily growing since the mid-200s. Parallel TPUs are designed to make the most of this trend.
Parallel TPUs are designed to execute as many non-conflicting transactions concurrently as is possible. An ideal parallel TPU will execute as many transactions that are not dependent on any higher-priority transactions as is possible. As an example, consider the “priority-ordered” set of transactions {tx1 > tx2 > tx3...tx7 > tx8} with the dependency graph shown below. The arrows indicate dependencies, e.g., tx4 is a dependency of tx1.
tx1 → tx4 → tx5tx2tx3 → tx6
tx7
tx8
Dependency Graph
Assuming each transaction executes within a unit of time, an ideal four-thread parallel TPU would:
- execute transactions
tx1,tx2,tx3,andtx7in parallel. - then transactions
tx4,tx6,andtx8would be executed right after. - finally,
tx5would be executed.
The challenge of designing and implementing a parallel TPU is designing a concurrency control system that ensures only non-conflicting transactions are executed simultaneously while maintaining priority with minimal overhead. Let’s look at how this is accomplished in practice.
How Parallel TPUs are implemented–Concurrency Control–and why it’s necessary.
It’s easy to say, “...just execute the transactions in parallel, bro..” without truly understanding why this is such a difficult problem to solve and so I’ll give a simple example to elaborate why concurrency control is necessary when attempting to parallelize access to shared resources.
Consider the example of a banking database where:
- accountA has $50
- transaction1 wants to send $50 from accountA to accountB and
- transaction2 wants to send $50 from accountA to accountC.
Assuming both transactions are allowed to execute in parallel,
- both transactions will initially read the balance of accountA as $50.
- both transactions will then write zero ($0) to the memory location where the account balance of accountA is stored. Note that it doesn’t matter if one writes before the other; they both read the balance as $50 and will update it to be (original balance - transfer amount) so both accounts will write 0 to the account balance.
- both transactions will read accountB and accountC’s account balances and write an additional $50 to the memory location where the balances are stored, printing $50 out of thin air.
This is a simple example but it suffices to show that when there's concurrent access/modification of shared resources by uncoordinated transactions, the execution results are non-deterministic (subject to race conditions) and unserialize. A few other potential problems that arise due to a lack of concurrency control are:
- The lost update problem: When a batch of transactions is executed in parallel, there’s a possibility that a lower-precedence transaction (say txk) overwrites a memory location that a higher-than-k-precedence transaction (say txj) needs to read. txj should have read the values before txk wrote to the location, without concurrency control, there is no way to enforce this behavior.
- The “dirty read” problem: Sometimes transactions are "aborted,” so all the data they’ve written will be rolled back; however, another transaction might have read these (dirty) values before they’re rolled back, compromising the integrity of the database.
There are more potential problems that can arise from simply parallelizing transactions but they won’t be discussed for the sake of brevity. The important takeaway is that attempting to parallelize execution without additional safety measures compromises the integrity of the execution results. The solution to this problem in distributed Database Management Systems (dDBMSs) is referred to as Concurrency Control (CC).
Concurrency Control and types of Concurrency Control
Concurrency control is the process of ensuring that simultaneously executing operations do not conflict. In DBMSs (and, by extension, blockchains), there are two major paradigms of concurrency control: Optimistic Concurrency Control (OCC) and Pessimistic Concurrency Control (PCC).
- Pessimistic Concurrency Control (PCC): In PCC, the execution of a transaction is blocked if it needs to access a resource that is already in use by another (usually higher priority) transaction. In PCC systems, locks are usually the method of choice to enforce "blocking.” Most PCC systems also require that transactions declare upfront what portions of memory they will read from and/or write to since acquiring locks on the fly will still lead to unserializable execution results.
- Optimistic Concurrency Control (OCC): In OCC, transaction are attempted on as many processing resources as are available. But instead of writing directly to or reading directly from persistent memory, the transactions usually write to a log. After attempted execution, the transaction is validated to make sure that its execution did not violate any of the database integrity rules. If validation fails, the effects of the transaction are rolled back, and the transaction is rescheduled for execution. Otherwise, the transaction commits, i.e., writes to persistent memory.
There are many ways to design and implement OCC and PCC systems, but in the following sections, we’ll look at the leading implementations of both paradigms in the blockchain space, starting with the leading OCC implementation: Block-STM.
Blockchain-Software Transactional Memory (Block-STM)
Block-STM is the result of years of R&D around Transactional Memory (TM) and distributed databases but before we cover Block-STM, it’s beneficial to briefly go over a few concepts, starting with the lifecycle of an Aptos transaction.
Brief description of the life-cycle of an Aptos Transaction
The lifecycle of an Aptos transaction is similar to that of other blockchains but contains a few nuances specific to Aptos to improve the performance of Block-STM.
- A transaction starts out as a request from a client; this request finds its way to a full node or a validator node.
- The full node forwards the transaction to other nodes on the network. The nodes keep these transactions in a mempool.
- The mempools of each node call perform signature verifications, minimum account balance verifications, and replay resistance using the sequence number.
The sequence number of an account is the equivalent of a nonce in Ethereum. It keeps track of the number of transactions that have been submitted from that account. If the sequence number of a transaction does not match the sequence number of the account, the node rejects the transaction. This is Aptos’ approach to preventing replay attacks, a type of attack where a malicious entity stores a signed transaction and repropagates it after it has been executed. - After checks, the leader for the current block fetches a block of transactions from its mempool (the current implementation prioritizes transactions based on fees) and forwards the unexecuted block to other nodes as a proposed ordering of the next set of transactions.
- The leader begins to execute the block concurrently with the forwarding of the block.
- As soon as the leader completes execution, it signs the execution result and forwards it to other validators.
- The validators, who have all received the block, replay it and come to consensus on the execution results.
An illustration below from the Aptos documentation shows the lifecycle of a transaction.
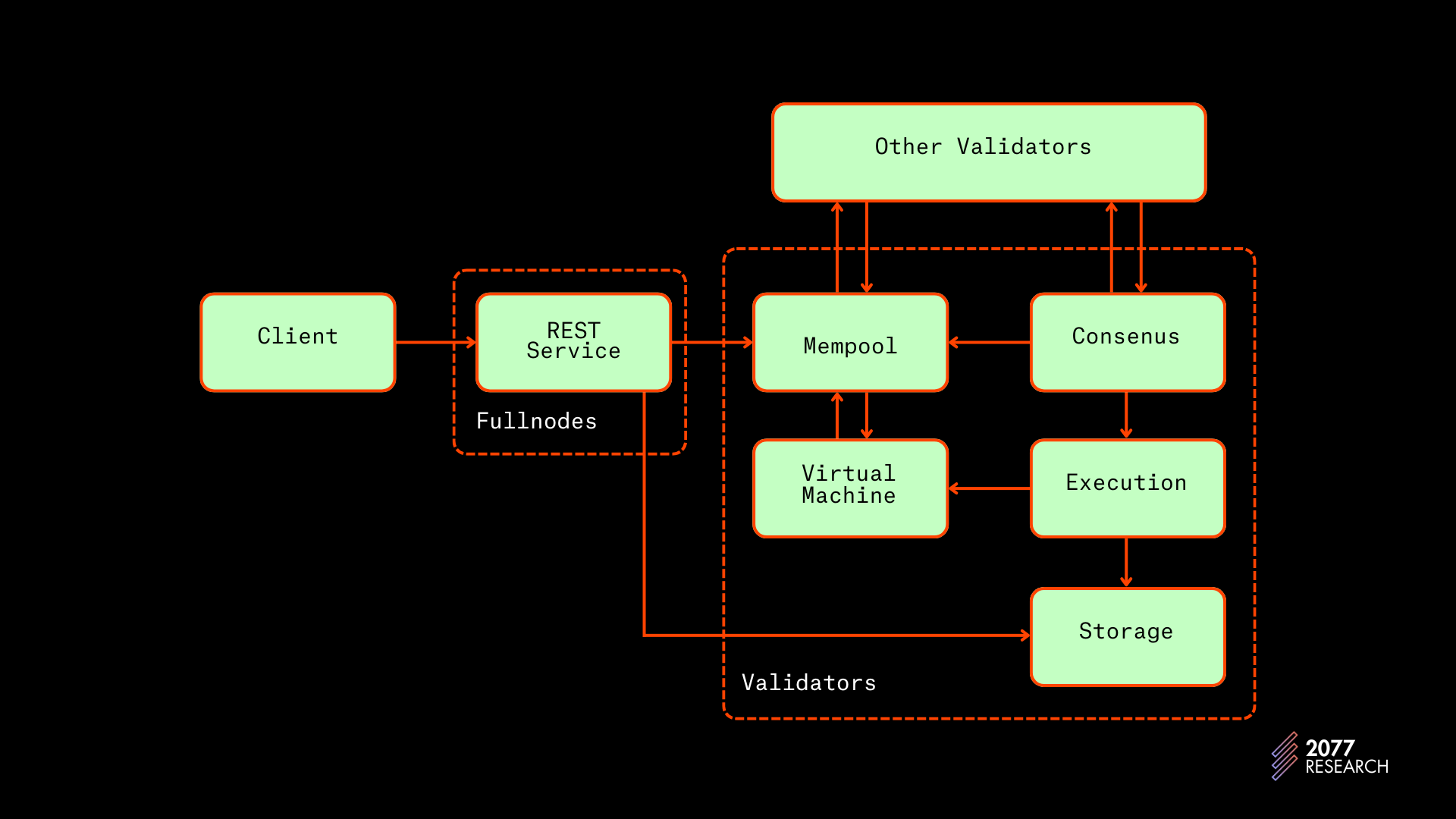
The key difference between Aptos’ transaction lifecycle and that of other blockchains is that Aptos blocks are disseminated before they’re executed. This is very different from other blockchains, where execution results are communicated with the transactions. This design choice has two effects:
- It separates sequencing and execution.
- It adds an extra round of messaging.
Aptos’s decoupling of sequencing and execution lays the groundwork for asynchronous execution, which has been adopted by Monad and is on the roadmap for Solana as well.
Another change that is not immediately evident or, more accurately, considered baked into the cake is that in traditional consensus protocols (including Aptos’), the leader always performs a disproportionate amount of work. To combat this, Aptos now uses Quorum Store, which is an implementation of Narwhal, to spread bandwidth utilization across all the validators. I briefly go over Quorum Store in the Appendix.
With that out of the way, the final stop on the road to covering Block-STM is to provide some background by briefly discussing the major developments that preceded Block-STM.
Transactional Memory (TM), Software-only Transactional Memory (STM), Calvin, and BOHM.
Like I mentioned earlier, Block-STM is built on the back of decades of research. The earliest development came in 1993 in the form of the Transactional Memory (TM) paper, which detailed a hardware-level solution for “transactional memory access.” Software-only Transactional Memory (STM) was formalized in 2005 and it implements the principles of TM using only software. The other two notable developments are the “Calvin” and “BOHM” protocols that address concurrent transactional modifications of distributed databases. We’ll go over a high-level overview of each of them to provide context for Block-STM.
Transactional Memory (TM)
I find it easier to think of Transactional Memory as transactional memory access. The underlying principle of TM is to allow concurrent programs to modify (read and write) shared memory in a way that is analogous to how database transactions modify a database without using locks. More simply put, TM aims to allow concurrent programs to modify shared memory atomically and produce serializable results without locks. The reasoning behind the development of TM was that lock-based synchronization techniques incur overhead from managing locks and must be carefully designed to be resistant to priority inversions, convoying, deadlocks, livelocks, etc. TM would not need to worry about these things and would (in theory) outperform lock-based systems.
The paper proposed a new multiprocessor architecture (not an instruction-set architecture), and the addition of a few instructions that would allow for transactional memory access. The additional instructions allowed programmers to define new read-modify-write operations that performed atomic updates to one or multiple memory locations without needing to lock those memory locations.
A few (less than ten) implementations of TM were developed but TM never had widespread use.
Software (only) Transactional Memory (STM)
STM is a suite of software-only implementations of the principles of Transactional Memory. The goal is the same as TM: to allow concurrent processes to access shared memory without the use of locks.
The way STMs usually implement this functionality is optimistic—threads execute with no regard for what other threads are doing but instead of committing their writes directly to memory, the threads record every read and write in a log (abstract data structure).
At the end of a thread’s execution, the results are validated, i.e., the values that the process read during its execution are compared against the current values at the same memory locations. If the values are different, then the thread rolls back all its writes because a difference in the read-sets implies that one or more concurrent processes modified the memory areas accessed by the process being validated; hence, the execution results are unserializable. STM implementations will reexecute (and revalidate) transactions that fail validation until they pass. STM maximizes concurrency as threads never have to wait to access resources they need but there’s a great deal of wasted work in high-contention use cases.
Years of research showed that STM implementations perform worse than “fine-grained” lock-based synchronization methods on a small number of processors due to the overhead from managing the log. For these reasons, STM implementations don’t find much use in practice and when they do, it’s for hyper-specific use cases that the implementations are optimized for.
Calvin
The next major development that preceded Block-STM came in the 2012 “Calvin” paper, where the authors proved that, contrary to popular belief, enforcing a preset order of transactions improved the execution throughput of distributed databases. The general sentiment before Calvin was that enforcing a preset order of execution would reduce concurrency but Calvin firmly established that as false.
Calvin, like Sealevel, requires that transactions declare upfront all the memory locations that they will access during execution. The rest of the workflow is fairly straightforward.
Calvin nodes (computers that manage partitions of the distributed database) first decide on the ordering (priority) of a set of transactions {tx1 > tx2…> txn} and after coming to consensus on the ordering, Calvin’s scheduling follows a simple rule:
if two or more transactions request access to the same memory locations, the higher-priority transaction must be allowed to access the memory location first.
A dedicated thread is responsible for lock management and this thread iterates through the serial transaction order and ensures that requests for locks are made in order. When two transactions conflict, they are scheduled sequentially in order of priority but non-conflicting transactions can be scheduled concurrently.
There is a lot more nuance to Calvin’s design but the key takeaway is that Calvin established the idea that enforcing priority improved throughput.
BOHM
The next critical development came in 2014—BOHM. Like Calvin, BOHM is designed for distributed databases but the key insight is also easily extensible to blockchains. BOHM uses a Multi-Version Concurrency Control (MVCC) mechanism, which is an auxiliary form of concurrency control that uses a multi-versioned log to manage reads from and writes to shared memory.
In a nutshell, in MVCC databases, transactions do not directly modify the database; instead, a log holds multiple versions of the database for every transaction, i.e., each memory location is associated with all the values of the transactions that have written to it rather than the most recent write
You can imagine the multi-version data structure as a two-dimensional table with entries in the form (transaction version, value). Each slice of this two-dimensional table is a table that contains the version of state for a particular memory location. An illustration that should help get the idea across is shown in figure 3.

Recording in MVCC is similar to but different from that of TM in that in MVCC, for every write to a memory location, a new version of the location specific to that transaction is created (or updated) rather than overwriting the current value. MVCC databases allow for more concurrency than single-version databases, as transactions can read the values written by any transaction at a memory location regardless of how many transactions have written to that location; the tradeoff is an increase in space (memory) complexity.
BOHM showed that combining multi-version concurrency control with fixed transaction ordering significantly improved the execution throughput of databases while maintaining full serializability. The way BOHM works is briefly explained below:
BOHM is a two-layered protocol—there is a concurrency layer and an execution layer. As a stream of transactions is fed to the concurrency layer, a single thread orders the transactions by timestamp. The "concurrency threads” are individually responsible for a logical partition of the database. BOHM requires that transactions declare their read and write sets upfront and using this information, each concurrency thread cycles through the ordered set and checks if the transaction writes to its partition. For all transactions that do, the concurrency thread creates an uninitialized placeholder in the log for that transaction. Because individual threads are responsible for partitions of the database, BOHM increases concurrency with intra-transaction parallelism when creating the placeholders. After the concurrency control threads complete their tasks, another set of threads, ”execution threads,” execute the transactions and fill in the placeholders.
As mentioned earlier, there’s a priority order, so when a transaction needs to read from a memory location, it checks for values written by the lowest priority transaction that is higher than it. For example, if transactions tx2 and tx6 write to a memory location that tx4 needs to read from, tx4 will read the value written by tx2.
In the event that the placeholder associated with the correct version to read is still uninitialized, i.e., tx2 has not yet written to that location, the execution of the transaction (tx4) is blocked until the transaction that should write to that location (tx2) completes its write. This “reads never block writes” design allows BOHM to be extremely efficient, especially with large workloads, as the greatest cost—constructing the multi-version data structure—is amortized as the workload grows.
Again, some nuance has been left out but the key takeaway from BOHM’s design is that multi-version data structures allow for increased concurrency at the cost of memory.
In addition to the four protocols discussed above, a 2017 paper also did some work on STM for blockchains. In the paper, the authors propose the classic STM design with on-the-fly lock acquisition to attempt to prevent concurrent memory access and post-execution validation to identify conflicts.
The design is uncomplicated: transactions are optimistically attempted, attempting to grab locks as they require them, and validated after. If a conflict is discovered, it is resolved by rolling back the transaction and re-executing it. The design allowed the leader a great deal of freedom in deciding transaction order but the results were non-deterministic so other nodes would likely not arrive at the same execution results unless the leader shared the exact execution path. But the design never saw any adoption, largely because the performance results presented in the paper showed that the protocol was only slightly better than sequential execution and sometimes worse. Block-STM applies the insights from Calvin and BOHM to succeed where the unnamed 2017 protocol failed. With the appropriate background set, we can move on to Block-STM.
Block-STM
Traditional distributed databases view the insights of Calvin and BOHM as constraints since:
- enforcing a priority ordering requires some form of consensus between nodes and
- committing each transaction individually (as opposed to block-level) is the norm in transactional databases.
But both of these properties are inherent in blockchains—blockchain nodes must agree on the ordering of transactions, even if the leader is free to propose as it wishes and commits usually occur at the block level (or at least in batches a la Solana). In essence, what traditional DBs consider constraints are built into Block-STM’s spec and it leverages them to improve its performance.
Below an overview of how Block-STM works:
Similar to Calvin, transactions are ordered by priority: {tx1 > tx2 > tx3 >...txn}. After ordering, the transactions are scheduled for execution. Like in STM, transactions are “attempted” with all available resources with no regard for conflicts. And like in BOHM, the execution threads don’t read from/write to memory directly. Instead, they read from or write to a multi-version data structure (that we’ll refer to as “data structure” going forward).
Continuing in BOHM’s footsteps, when a transaction (say txj) reads from the data structure, it reads the values written by the most recent version of the lowest-priority transaction that is higher than itself (in this example, txj will read from some transaction txi that has written to the memory location). For example, if tx6 wants to read from a memory location that has been written to by tx1 and tx3, tx6 reads the value written by tx3. (Keep this definition of read in mind as it is central to the working principle of Block-STM.)
During the execution of a transaction, its read set is tracked. The read set contains the memory locations and associated values that a transaction read during execution. After a transaction (txj) completes execution, it is verified by comparing its read set with the current values at the memory locations it read from (keeping in mind the definition of read established earlier). If there are any discrepancies between the read set and the current values at the memory locations, it implies that during the transaction’s (txj’s) execution, one or more higher-than-j precedence transactions (say txi) modified one or multiple memory locations that txj read. Based off the preset serialization order, txj should have read the values written by txi so all the values written by txj are considered dirty.
But instead of deleting those values from the data structure, they are marked as estimate and txj is scheduled for reexecution. The values are not deleted because it’s likely that reexecuting txj will write the same locations and any (lower-than-j priority) transactions that read values marked as estimate are delayed until txj is re-executed and revalidated. Because of this heuristic, Block-STM can avoid a cascade of aborts and reexecutions that would occur if the data structure were wiped clean of dirty values.
If there are no discrepancies, i.e., no higher priority transaction than the one currently being validated (txj), write to a memory location in the read set of txj, then txj is marked valid but not safe to commit. The transaction is not safe to commit yet because there’s a chance that a transaction of higher priority, say txi will fail validation. In such an eventuality, all validated lower-than- txj (txk, txl, txm …) priority transactions than need to be revalidated to ensure that they haven’t read from a location written to by txi. Because of this, transactions are not safe to commit until all transactions that come before them in the preset serialization order have been executed and validated.
When all the transactions in the BLOCK have been executed and validated, execution is complete. That’s a basic (and likely confusing) overview of how BlockSTM works; we’ll go over the process in detail next.
Technical details of Block-STM
Before we look at the technical details of Block-STM, a few details need to be concretized.
First, the input to Block-STM is an ordered set called a BLOCK that contains n transactions in the preset serialization order: {tx1 > tx2 > … > txn}. The goal of Block-STM is to take this BLOCK of transactions and execute them with the most concurrency possible, without breaking the serialization.
As I mentioned earlier, each transaction is first executed and then validated. If an executed transaction fails validation, the transaction is scheduled for re-execution. To track the number of times a transaction has been executed, each transaction is associated with an incarnation number in addition to the index number. You can think of a transaction as being of the form txn, i where n is the index number and i is the incarnation number. So the BLOCK is initially equivalent to {tx1, 1 > tx2, 1 > … > txn, 1}. The combination of a transaction's index and its incarnation make up the version of the transaction. For example, the version of tx2, 5 is (2, 5).
Lastly, to support concurrent reads and writes, Block-STM maintains an in-memory multi-version data structure similar to the one discussed in BOHM that stores the latest writes per transaction, and the transaction version for every memory location. Here’s a snippet of the early implementation:
pub struct MVHashMap<K, V>{
DashMap<K, BTreeMap<TxnIndex, CachePadded<WriteCell<V>>>>
The MVHashMap maps each memory location to an internal BTreeMap that maps the indexes of transactions that have written to that memory location to the corresponding values. The DashMap is responsible for concurrency. It allows thread-safe modification of the BTreeMap. Full details on the data structure implementation can be found here.
Next, we’ll look at the actual thread logic.
Thread Logic
The activities of the worker threads (execution and validation threads) are coordinated by a collaborative scheduling thread that tracks and modifies two ordered sets that we’ll call E and V. E contains all transactions that are yet to be executed and V tracks transactions that are yet to be validated. The implementation of the collaborative scheduler tracks these tasks with atomic counters; more details can be found in Appendix A3.
Each of the worker threads cycles through the 3-stage loop outlined below: check done, find next task and perform task.
Check done
If V and E are empty and no other threads are performing a task, then the execution of the BLOCK is complete. Else:
Find next task
If there are tasks in E and V, an available worker thread will select the task with the smallest index between V and E. i.e., if V contains {tx1 and tx3} and E contains {tx2 tx4}, the worker thread will create and perform a validation task for tx1. The atomic counter mentioned above ensures that both sets will not contain the same transaction. As to why the transaction with the smallest index is chosen, it’s because validating or executing the higher-priority tasks as soon as possible helps to identify conflicts early. This is one of the ways a preset order improves performance.
Perform Task
If the next task is:
- an execution task then: execute the next incarnation of
txn, i- If, during the execution of
txn, ian estimate is read, then:- abort execution,
- mark all the data written by
txn, ias estimate and - add
txn, ito E (with an increased incarnation number, i.e.,txn, i+1
- else (if no estimates are read):
- Check if
txn, iwrites to any locations that the previous incarnation (txn, i -1) did not write to.- If there is a write to a new location, add validation tasks for all transactions lower in priority than
txn, ithat have been executed or validated.This step is necessary because if the execution oftxn, iwrites to a new memory location that previous incarnations oftxndid not, there’s a chance that transactions of lower precedence (i.e., transactions with indexes > n) already read from these memory locations so they need to be checked for validity. Transactions of higher precedence don’t need to be validated because they should have read that location beforetxnwrote to it. - Create a validation task for
txn, i
- If there is a write to a new location, add validation tasks for all transactions lower in priority than
- If
txn, idoes not write to any new locations, then create a validation task fortxn, ialone.
- Check if
- Loop back to Check done.
- If, during the execution of
- a validation task, then: validate
txn, i- if validation succeeds, the thread returns back to check done.
- else (if validation fails),
ABORTand:- Mark all the values written by
txn, ias estimate. - Create validation tasks for all transactions lower in priority than
txn, ithat are not currently in E and add the validation tasks to V. Transactions lower in priority thantxn, iwould never read the value written bytxn, ibecause of the definition of a Block-STM read. - Create an execution task for
txn, iwith an incremented incarnation number (txn, i + 1) and add the task to E.
- Mark all the values written by
- Loop back to Check done.
This loop continues until there are no more tasks in V and E, at which point check done returns done and the most recent version of the data structure is safe to commit to persistent storage. After commitment, a garbage collector frees up the data structure and the transaction processing unit awaits the next BLOCK. Below is an example of how this process would play out in practice:
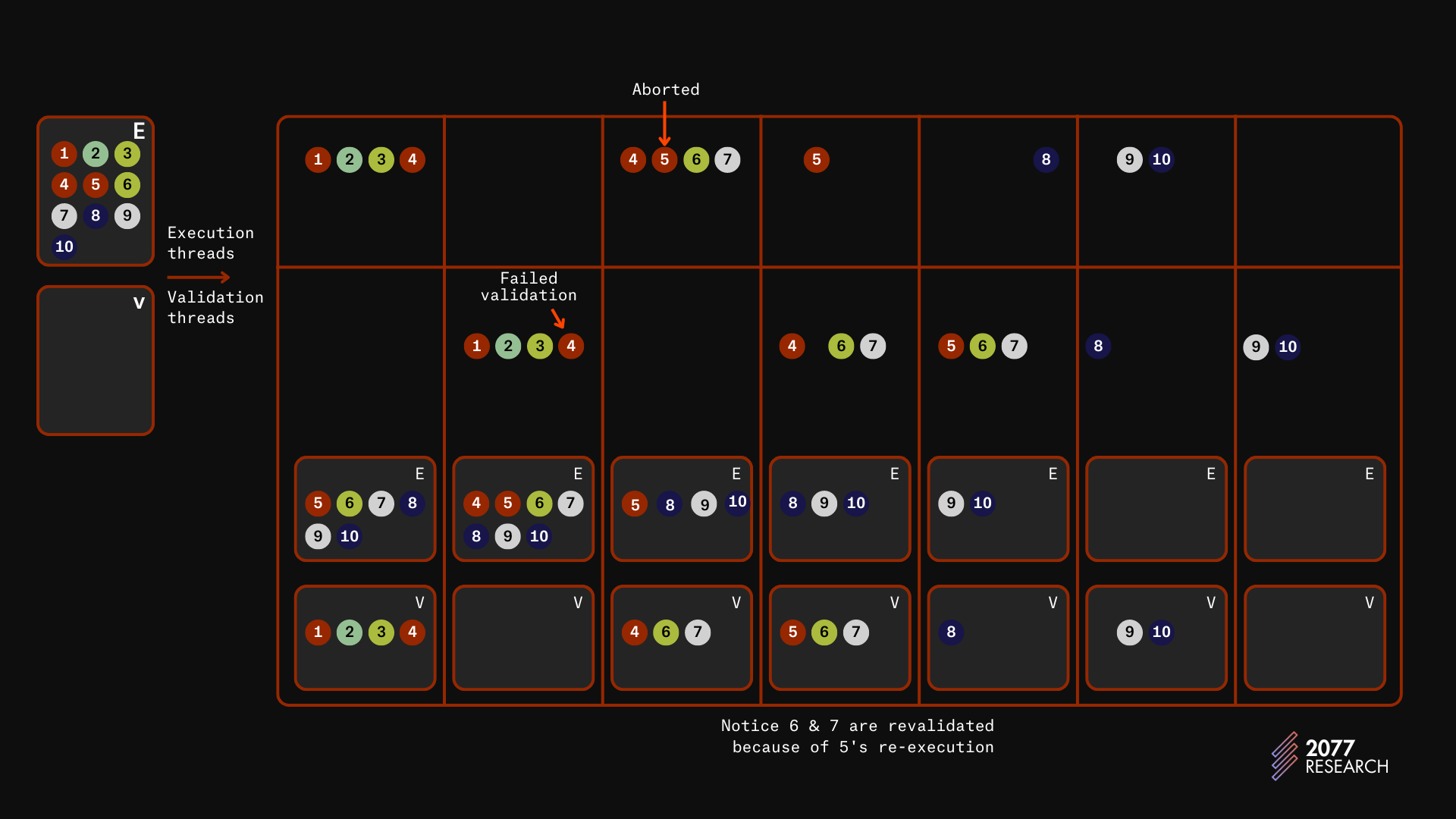
The illustration above is modeled on a four-worker-thread machine. The sets E and V are the execution and validation sets. Nodes (circles) represent transactions and the color of a node helps to identify other transactions that it conflicts with.
The upper level of the main table shows execution threads and the lower levels show the validation threads. The sets E and V in every column represent the execution and validation sets after the completion of the iteration.
- As seen in the illustration, E initially contains all the transactions, and V is empty.
- During the first iteration, the first four transactions are executed optimistically and E and V are updated accordingly.
- During the next iteration, all four transactions that were executed are validated. Transaction 4 fails validation due to a conflict with transaction 1 and must be reexecuted.
- During the third iteration, transactions 4, 5, 6, and 7 are executed. Transaction 5 conflicts with 4 so it will read values marked estimate and it’s execution is paused until transaction 4 completes execution.
- During the fourth iteration, transactions 4, 6, and 7 are validated while the execution of 5 is completed.
- During the fifth iteration, transactions 5, 6, and 7 are validated. 6 and 7 are revalidated because of the reexecution of 5 for reasons explained above. Transaction 8 is also executed.
- During the next iteration, transaction 8 is validated while 9 and 10 are executed.
- And during the final iteration, transactions 9 and 10 are validated and the block is marked safe to commit.
While I’ve described a simplistic workflow, the same process can be applied to any batch of transactions with any dependency structure.
At its core, Block-STM is simple, and that simplicity, in conjunction with specific properties of blockchains—fixed ordering of transactions, block-level commits, and the safety of blockchain VMs—allows Block-STM to achieve relatively high throughput without enforcing the declaration of read/write dependencies up front. The Block-STM paper contains formal proofs of liveness and safety. And an even more detailed breakdown of Block-STM—the full algorithm (with explanatory comments)—can be found in Appendix A3. Lastly, an implementation of the TPU in Rust can be found here.
Next, we’ll look at how Block-STM performs in practice.
Block-STM Performance
To evaluate Block-STM’s performance, we forked aptos core and slightly modified the already existing benchmarks to evaluate its performance. The machine we used for testing is Latitude’s m4.metal.large, which has 384 GBs of RAM and an AMD 9254 CPU with 24 physical cores. The tests evaluate the execution process from the BLOCK being fetched to the completion of execution and validation of all transactions.
The transactions used during this evaluation are simple “P2P” transfers; a simple send between two accounts. The performance metric evaluated was throughput and the independent variable used for presenting the data is threadcount. The parameters used for evaluating performance are block size and number of accounts (a proxy for contention). Highly contentious workloads, like 2 accounts, proxies the type of traffic you’d expect during an NFT mint or when a particular market is “hot.” 2 is the most extreme possibility, as it means all the transactions in the block are between two accounts. Non-contentious workloads like 10000 accounts proxy the type of traffic you’d expect if the blockchain was used for P2P transactions i.e., simple sends between many indviduals. The other loads are proxies for everything in-between.
Figures 5-8 show the performance relative to the number of threads of Block-STM with different “levels of contention” and block sizes.
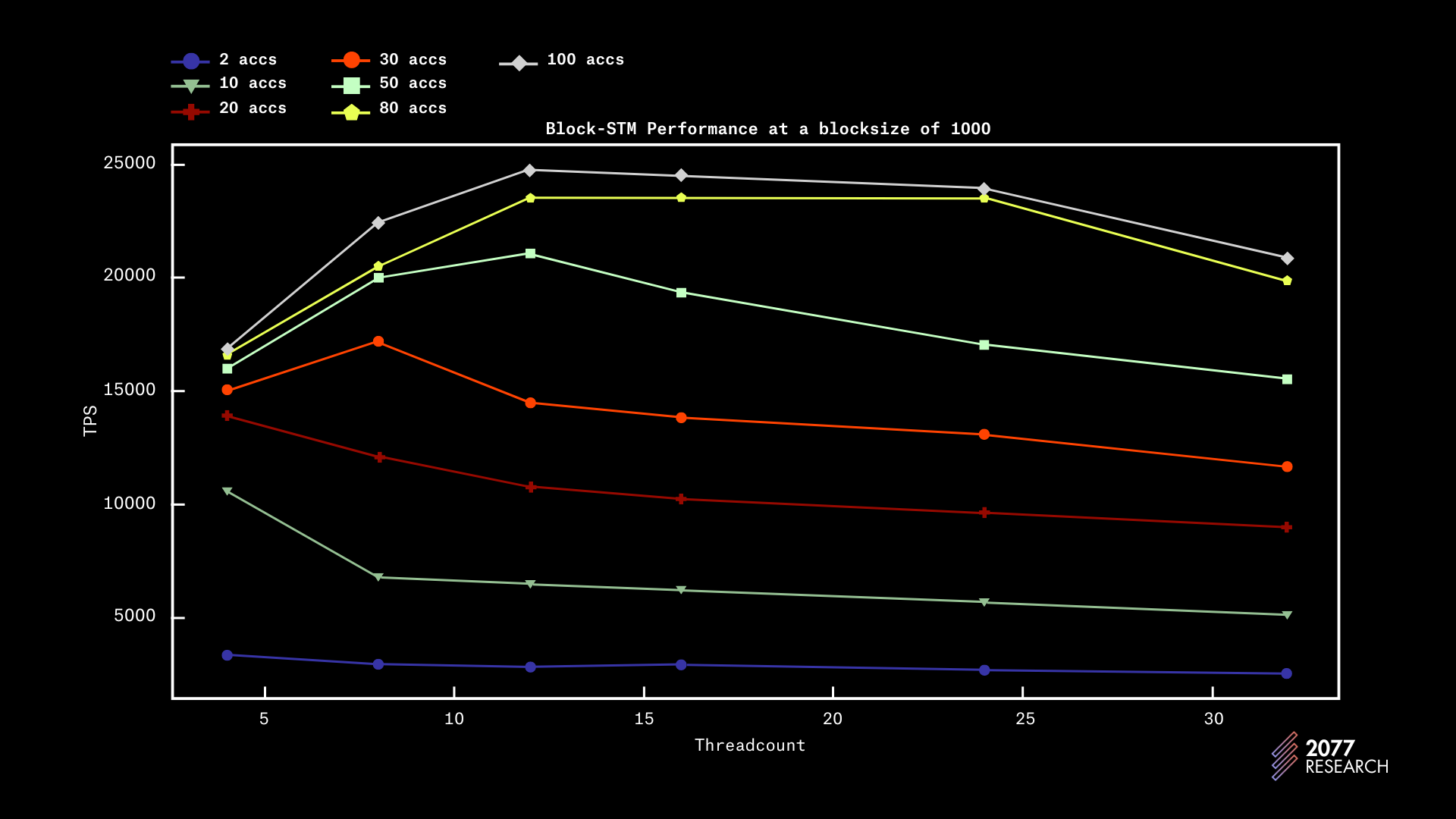
From the data, it is evident that (as expected), Block-STM performs better in low contention scenarios. However, throughput is only slightly better than sequential execution in high contention scenarios ( <10 accounts). And in completely sequential situations (2 accounts), Block-STM’s performance is significantly worse than sequential execution, (which is also to be expected.)
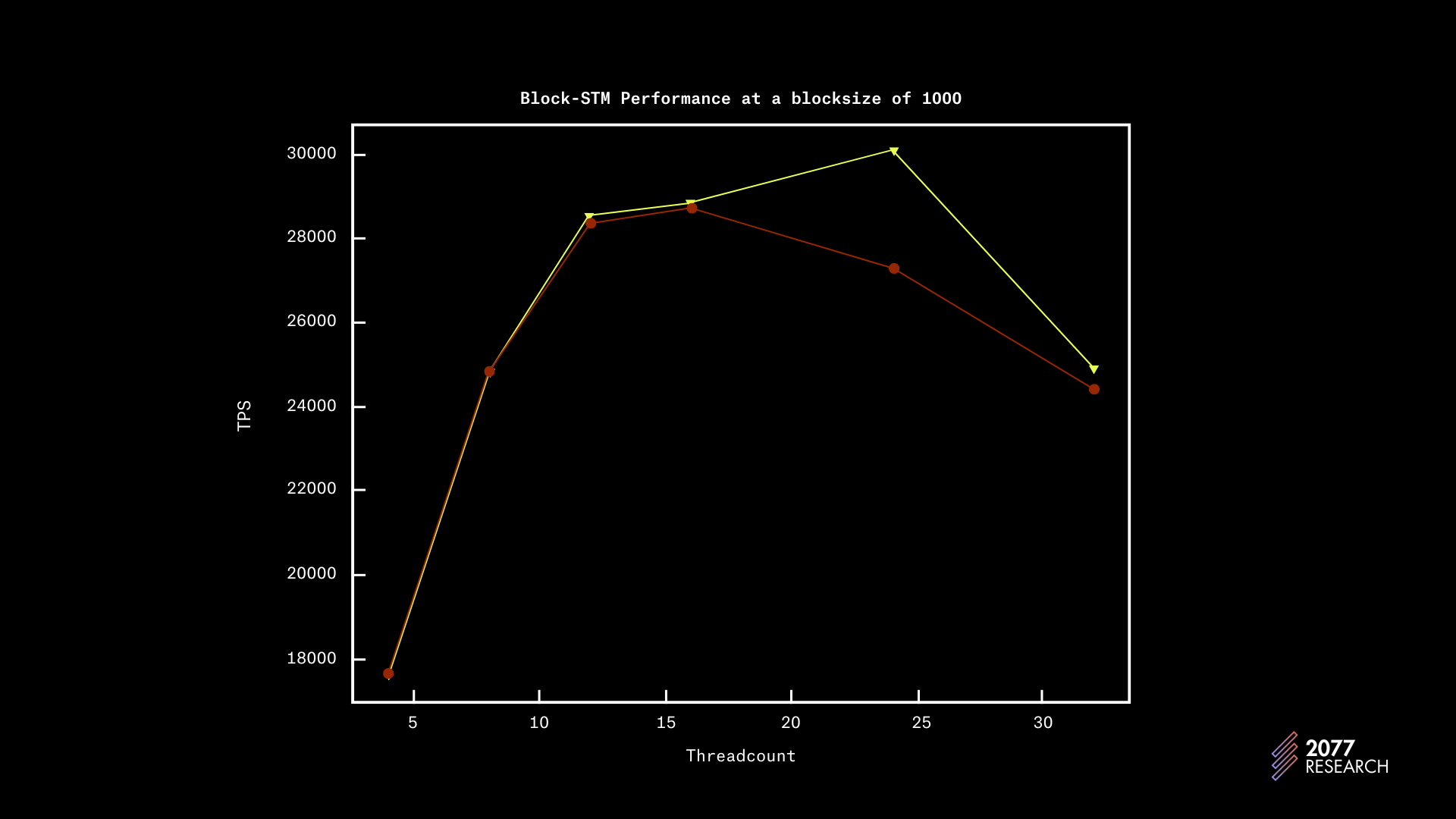
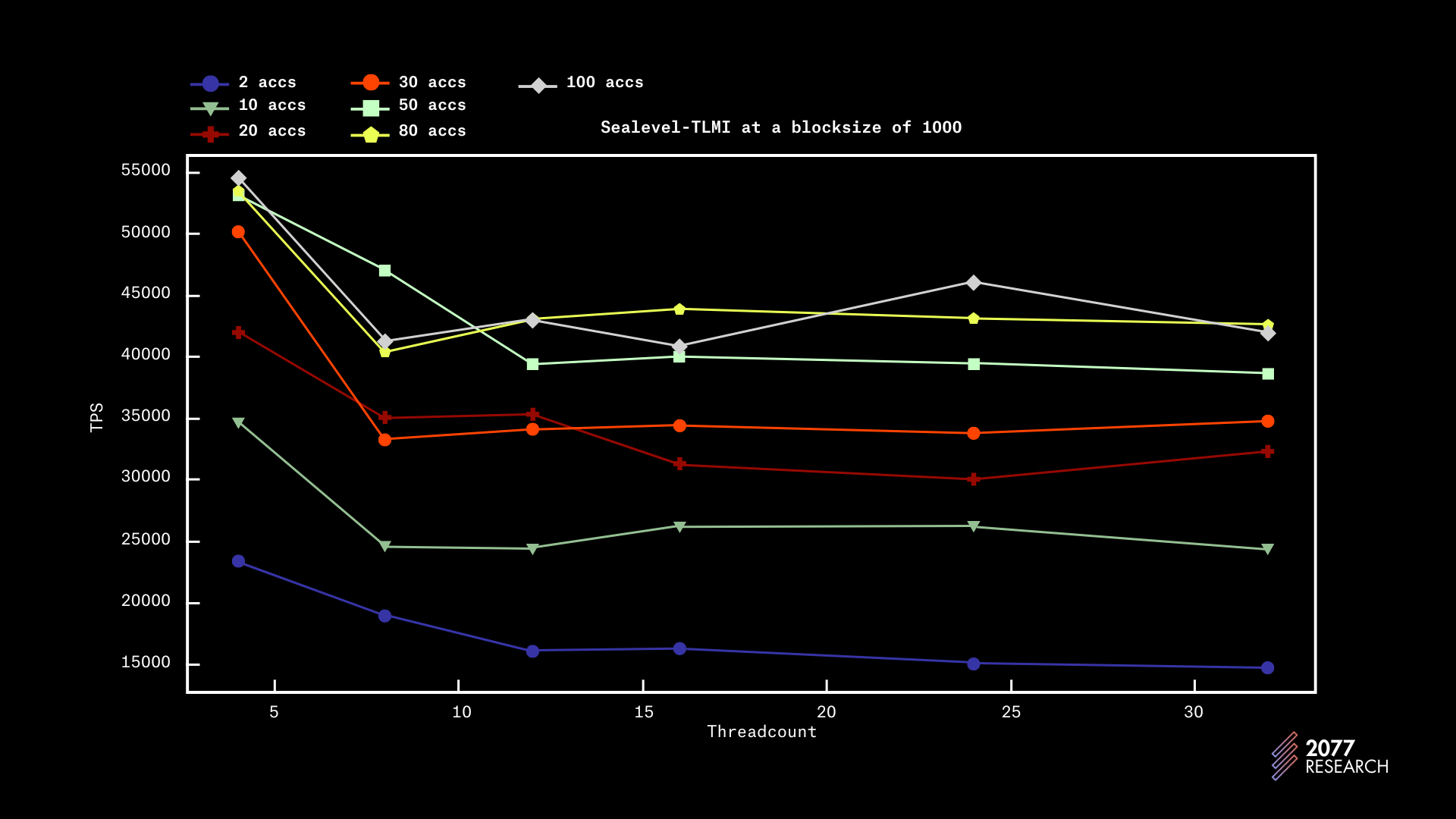
Figure 6 provides more context for performance at 1k blocksize and the data suggests that throughput peaks at 12 threads with non-contentious workloads. In high contention scenarios, performance trends slightly downward as the number of cores increases, plateauing around 8 physical cores. In very high contention scenarios, performance peaks at 4 cores (the lower limits of our tests, suggesting that performance would be better with even fewer cores). This behavior is understandable since more threads in a highly contentious environment increase the chance of the account being concurrently written to and the chance of a validation failure.
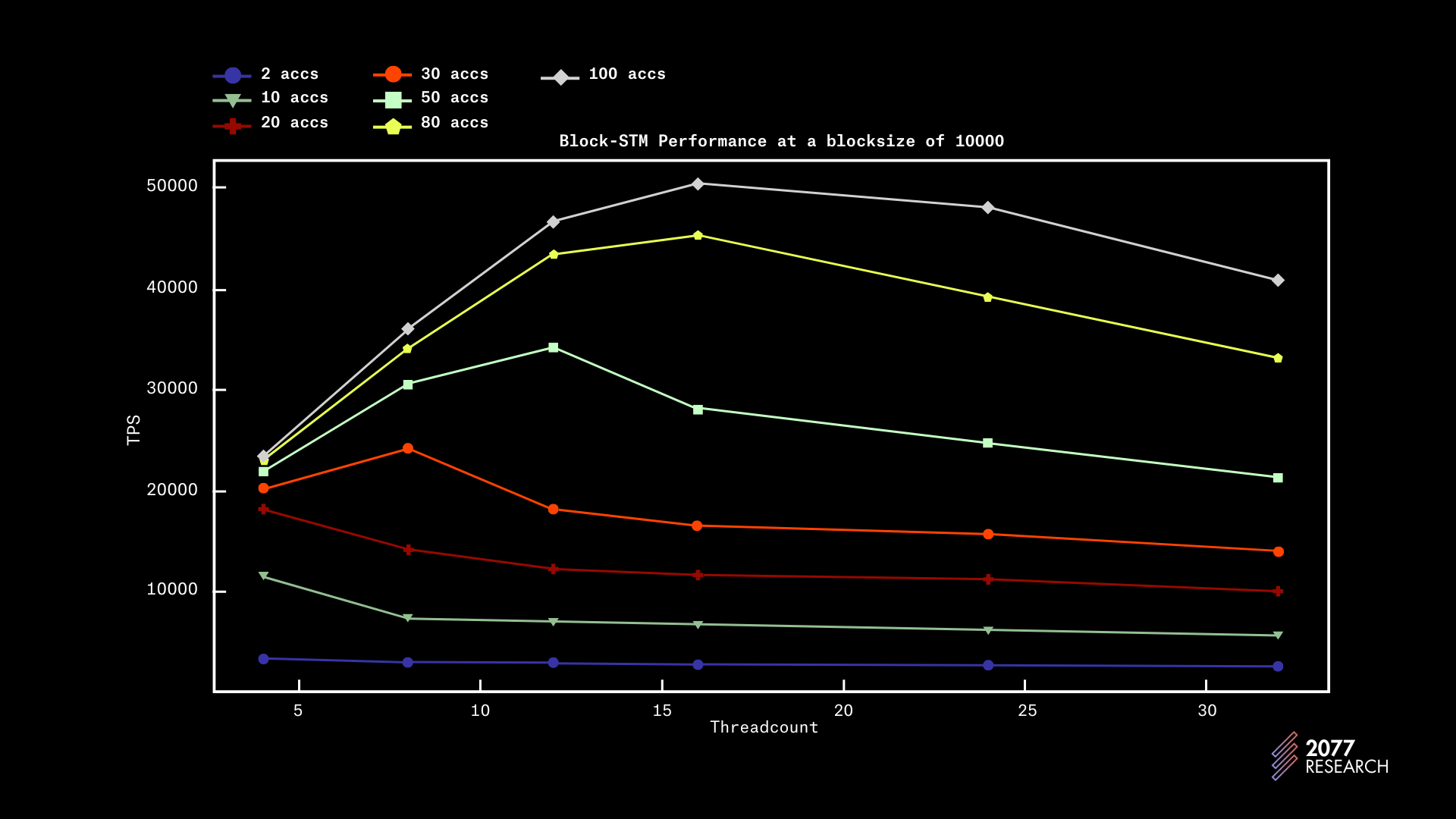
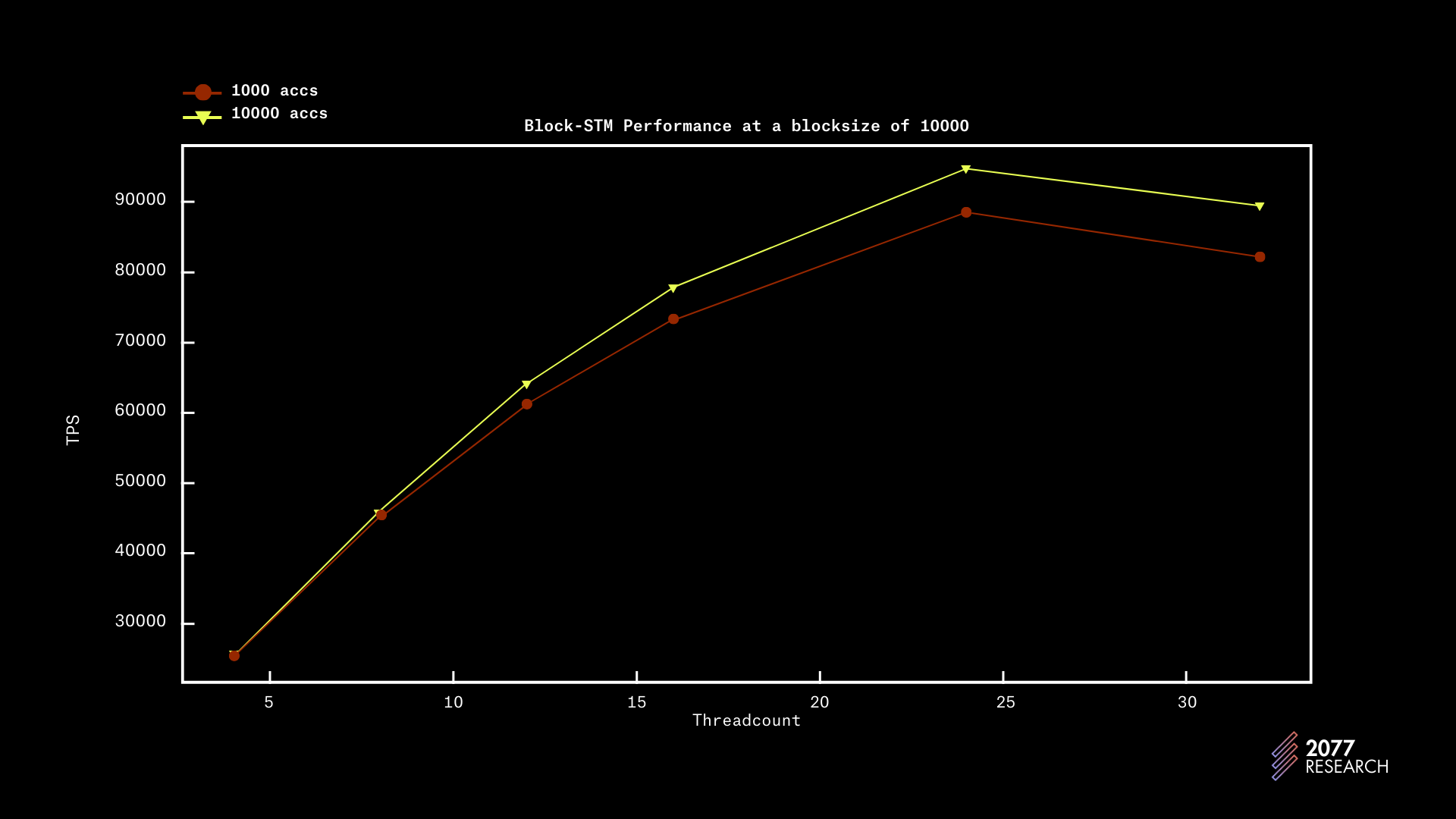
The graphs above provide more insight on how performance scales relative to block sizes and the data is quite similar to the 1k blocksize data. Although with a larger blocksize, performance grows more linearly.
For the sake of brevity, we left out additional data but the data collected implies that Block-STM performs better with larger blocks. The improvement in performance with larger blocks is likely due to the amortization of the initial failures. As the runs get longer, more and more transactions ABORT earlier than their predecessors amortizing the initial costs.
We also found that there are no significant improvements beyond a 20k block size and that reduction in contention beyond a certain point does not improve performance. A good indicator of this is that there are infinitesimal performance differences between 1000 accounts and 10,000 accounts. In essence, if thread count >> contention, then performance peaks.
It's important to note that the performance for threadcounts 24 and 32 are not reliable measures of Block-STM's perforance at those threadcounts. As mentioned earlier, the machine used for the tests has only 24 physical cores. To expose 48 logical cores, the CPU utilizes hyper threading which could be responsible for the performance.
The Block-STM paper contains the results of more tests, including one where Block-STM is compared to and slightly outperforms an implementation of BOHM. This is surprising considering BOHM has complete read and write sets of all transactions beforehand but the outperformance is likely due to the overhead of building the multi-version data structure in BOHM.
Overall, the data gives a reliable indication of BlockSTM’s limits and it’s not a stretch to say that in low contention situations, Block-STM massively outperforms any sequentially executed runtime and also scales almost linearly, making it suitable for large-scale applications like rollups.
That concludes the analysis of Block-STM, next we'll consider the leading PCC-execution runtime—Sealevel—a “marketing term” for Solana’s parallel execution TPU.
Sealevel
Sealevel is completely antagonistic in design to Block-STM. Sealevel uses lock-based synchronization for concurrency control, but most notably, it requires that all transactions declare upfront what portion of state they’ll be reading from and/or writing to during execution.
The Solana execution pipeline is further optimized by the use of Single Instruction Multiple Data (SIMD) instructions. SIMD instructions are a parallel (not concurrent) processing technique that performs a single operation over multiple data points.
Discussions about runtime optimizations are beyond the scope of this paper but the idea is that transaction instructions can be sorted based on what programs they call and all instructions that call the same instruction within a program can be batched and executed in parallel with SIMD instructions (again, not concurrently). A quote from Toly might provide some more insight.
“So, if the incoming transactions that are loaded by Sealevel all call the same program instructions, such as CryptoKitties::BreedCats, Solana can execute all the transactions concurrently in parallel over all the available CUDA cores.”
In short, Sealevel is designed for maximum speed. The following section will cover how Sealevel works and its performance. But first, a few primers, starting with a brief description of the lifecycle and structure of a Solana transaction.
Primer #3: The Structure and Lifecycle of a Solana Transaction
Transaction Structure
As mentioned earlier, Solana transactions must declare upfront what portions of state they will access. They do this by listing the accounts that they will use during execution and specifying if they will read from or write to these accounts. A basic Solana transaction is of the form:
"transaction": {
"message": {
"header": {
"numReadonlySignedAccounts": ,
"numReadonlyUnsignedAccounts": ,
"numRequiredSignatures":
},
"accountKeys": [], //a list of accounts that the transaction will use
"recentBlockhash": , //a recent blockhash
"instructions": [//list of the instructions within the transaction
{
"accounts": [], //expanded below
"data": "3Bxs4NN8M2Yn4TLb", //eBPF bytecode that contains the //instruction logic
"programIdIndex": 2, //index of program being called in the //"accountKeys" array
"stackHeight": null
}
],
"indexToProgramIds": {}
},
"signatures": [] //an array of signatures
}
The ”accounts” list within the instructions list of the transaction is the main focus here. This list contains all the accounts an instruction will use during its execution. The list is populated based on the AccountMeta struct.
The AccountMeta struct has a list of accounts with three fields.
Pubkey: The public key (an ed25519 key that identifies accounts) of the program being invoked. is_signer: A bool that determines if the account will sign the message is_writable: A bool that marks if the account will be written during execution.
Here is a sample AccountMeta struct named keys.
"keys": [
{
"pubkey": "3z9vL1zjN6qyAFHhHQdWYRTFAcy69pJydkZmSFBKHg1R",
"isSigner": true,
"isWritable": true
},
{
"pubkey": "BpvxsLYKQZTH42jjtWHZpsVSa7s6JVwLKwBptPSHXuZc",
"isSigner": false,
"isWritable": true
}
],
The key takeaway here is that from the AccountMeta struct, the TPU can identify what accounts will be written by a transaction and use that information to schedule non-conflicting transactions.
Lifecycle of a transaction
The lifecycle of a Solana transaction is largely the same as that of most other blockchains, with some differences, primary of which is that Solana does not have a mempool. Let’s briefly go over how transactions go from creation to commit.
- After a transaction is created, the transaction is serialized, signed and forwarded to an RPC node.
- When an RPC node receives the packets, they go through SigVerify, which checks that the signature matches the message.
- After SigVerify, the packets enter the BankingStage, which is where they are either processed or forwarded.
- On Solana, nodes are aware of the leader schedule—a pre-generated roster that dictates what validators will be leaders for what slots. A leader is assigned a set of 4 consecutive slots. Based on this information, nodes that are not leader forward transactions directly to the current leader and the next X (two (2) in the agave implementation) leaders. Note that since this is not a consensus-breaking change, some nodes forward transactions to more or less leaders.
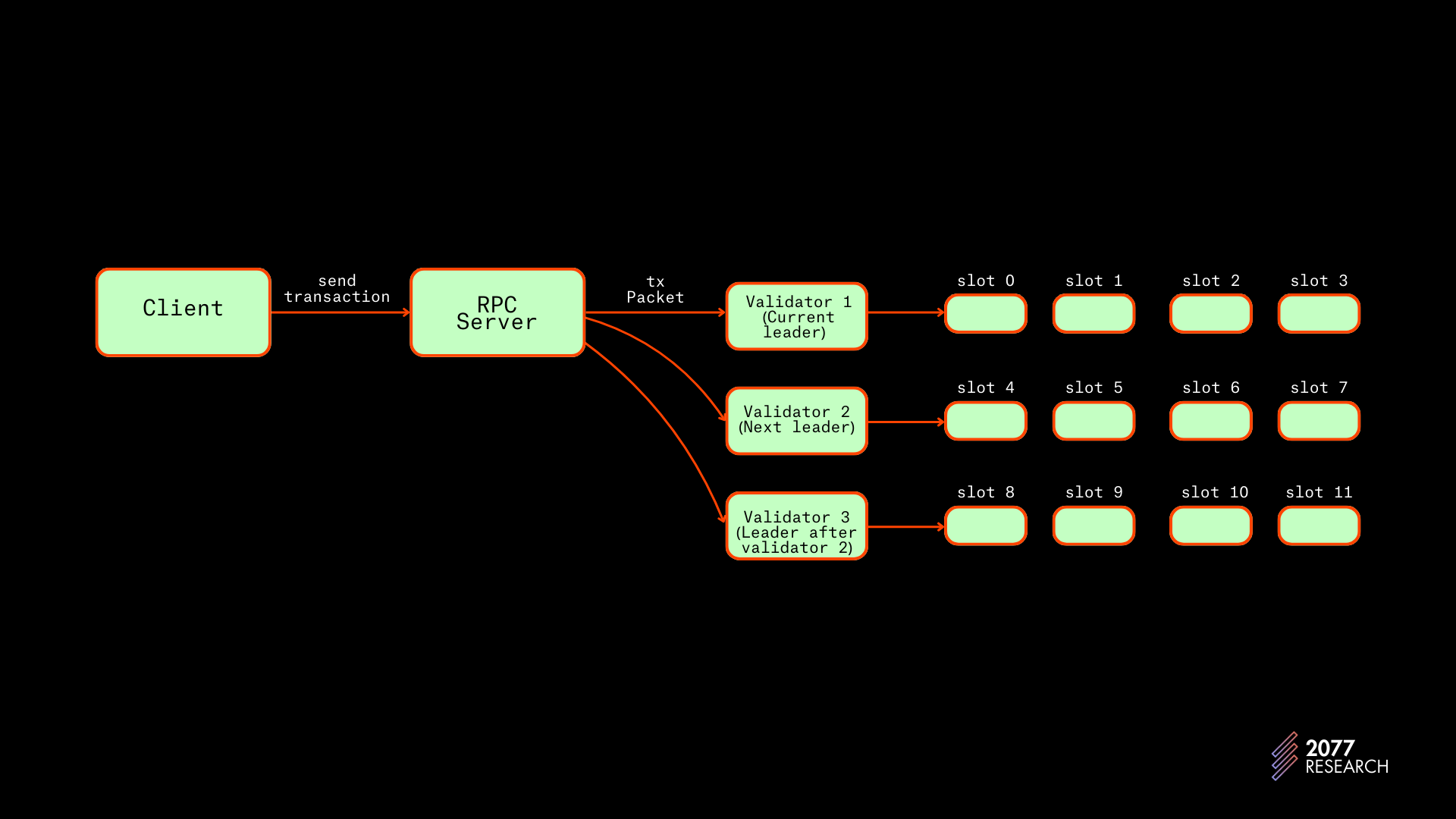
- When the leader receives the packets from other nodes, it runs them through SigVerify and sends the packets to the BankingStage.
- In the BankingStage, transactions are deserialized, scheduled, and executed.
- The banking stage also communicates with the Proof-of-History) component to timestamp batches of transactions. More on this later.
- By design, Solana blocks are continuously built and forwarded in small portions called shreds.
- When other nodes receive the shreds, they replay them, and when all the shreds that make up a block have been received, validators compare the execution results to the one proposed by the leader.
- Then validators sign a message that contains the hash of the block they’re voting for and send out their votes. Votes can be disseminated as transactions or through gossip but Solana favors treating votes as transactions in a bid to speed up consensus.
- When the quorum of validators is reached on a fork, the block at the tip of that fork is confirmed.
- When a block has 31+ confirmed blocks built on it, the block is rooted and practically impossible to reorg.
The major difference between the lifecycle of a Solana transaction and that of an Aptos transaction is that in Aptos, transactions are not executed before nodes receive the ordering of the block. Solana and Monad are moving towards an advanced form of this type of execution called asynchronous execution, with the final destination being “stateless validator nodes,” but that discussion is outside the scope of this paper.
Before we discuss the meat of transaction execution, it’s helpful to do a refresher on Proof-of-History concepts since PoH is heavily intertwined with the banking stage process.
Primer #4: Proof of History and the Banking Stage
Solana’s Proof of History is a “decentralized clock.” PoH’s working principle is basef on recursive SHA-256 hashes. It uses the cycle to proxy the passage of time.
The basic idea is that a SHA-256 hash:
- is pre-image resistant, i.e., the only way to compute a hash (h) of a message (m) is to apply the hash function H to m, and
- takes exactly the same amount of time on any high-performance computer.
Because of these two properties, nodes recursively performing SHA-256 hashes can agree that an amount of time has passed based on the number of hashes computed. Additionally, verification is highly parallelizable because each hash can be checked against the next one without relying on the results of the previous hashes. Because of these properties, PoH allows Solana nodes to agree on the passage of time without the need for synchronization or communication. The PoH hash calculation snippet is shown below:
self.hash = hashv(&[self.hash.as_ref(), mixin.as_ref()]);
mix_in is an arbitrary piece of information (in this context, transaction hashes) that is appended to the previous hash to assert that the event represented by mix_in occurred before the hash was computed, essentially timestamping the event.
The other PoH-specific concepts relevant to understanding the BankingStage are:
- ticks: a tick is a measure of time defined by X (currently 12,500) hashes. The tick hash is the 12500th hash in the chain.
- entry: an entry is a timestamped batch of transactions. Entries are called entries because they’re how Solana transactions are committed to the ledger. An entry is composed of three components:There are two types of entries: tick entries and transaction entries. A tick entry contains no transactions and is made at every tick. Transaction entries contain a batch of non-conflicting transactions.
num_hashes: the number of hashes performed since the previous entry.hash: is the result of hashing the hash of the previous entry num_hashes times.
Entry Constraints
There are quite a number of rules that determine if a block is valid, even if all the transactions it contains are valid. You can find some of those rules here, but the rule relevant to this report is the entry constraint. This rule dictates that all the transactions within an entry must be non-conflicting. And if an entry contains conflicting transactions, the entire block is invalid and rejected by validators. By enforcing that all the transactions in an entry be non-conflicting, validators can replay all the transactions within an entry in parallel without the overhead of scheduling.
However, SIMD-0083 proposes the removal of this constraint, as it constrains block production and prevents asynchronous execution on Solana. Andrew Fitzgerald discusses this constraint and a few others in this post on what he thinks are the next steps Solana needs to take on its journey to asynchronous execution.
To be clear, this constraint does not completely dictate how transactions are scheduled because executed transactions don’t have to be included within the next entry, but it is an important consideration for current scheduler designs.
With all that out of the way, we can discuss the meat of transaction execution—Solana’s BankingStage.
The Banking Stage
The BankingStage module houses Solana’s TPU and a lot of other logic for processing transactions. The focus of this report is on the scheduler but a brief overview of the BankingStage will be discussed to provide some necessary context.
Overview of the Banking Stage
The banking stage sits between the SigVerify module and the BroadcastStage, with the PoH module running in parallel to it. As discussed earlier, SigVerify is where transaction signatures are verified. The BroadcastStage is where processed transaction data is disseminated (via Turbine) to other nodes on the network and the TPU_Forwarding module is responsible for disseminating sanitized transaction packets to leader nodes.
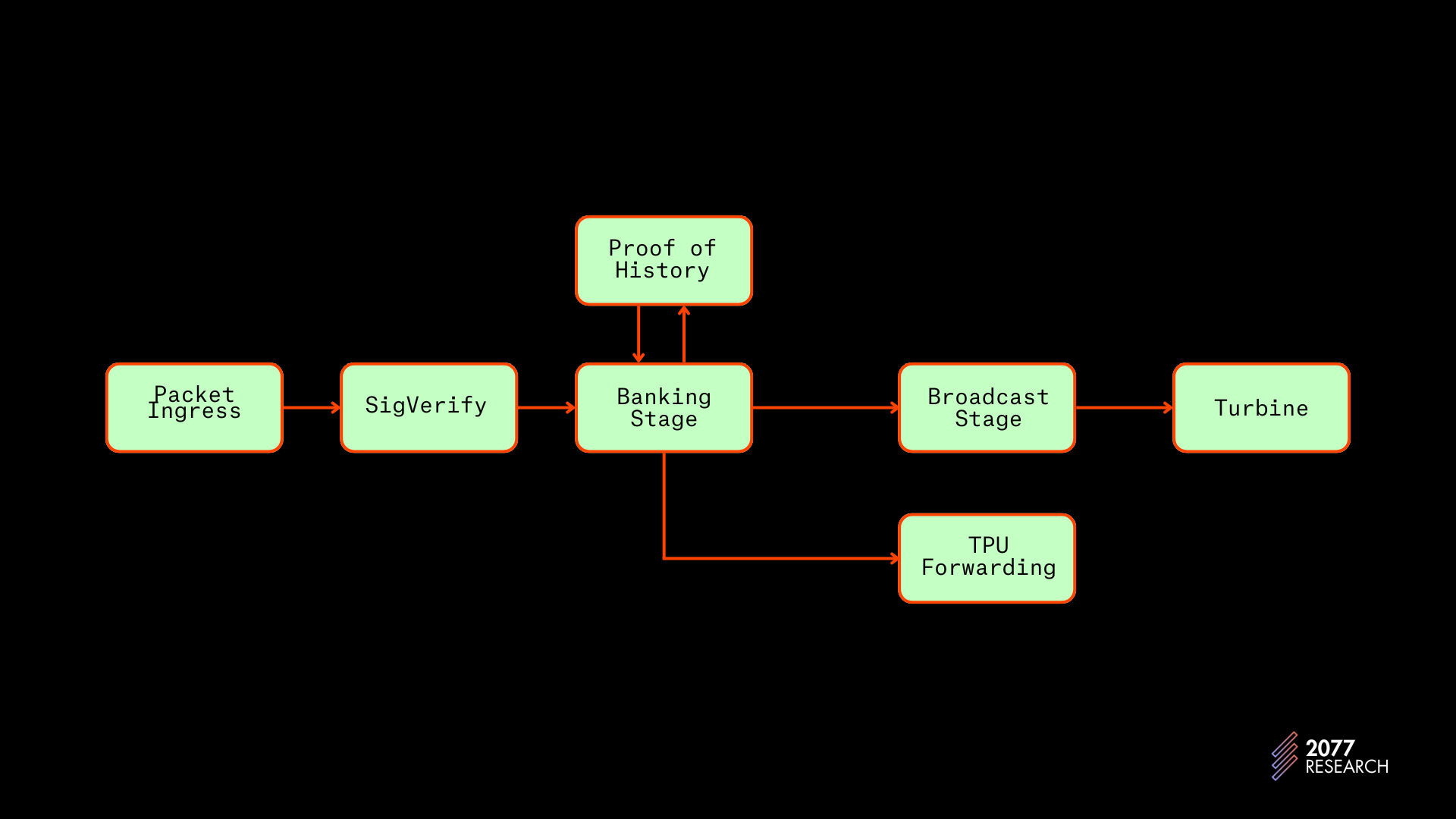
In the BankingStage, transaction packets from SigVerify are buffered and received by the appropriate channels. Voting transactions are received at the end of two channels, the Tpu_vote_receiver, and gossip_vote_receiver while non-votes are received by the non_vote_receiver. After buffering the packets are forwarded or “consumed” depending on the leader schedule. If the node is not the leader or due to be leader shortly, the sanitized packets are forwarded to the appropriate nodes. When the node is leader, it “consumes” the transaction packets, i.e., the packets are deserialized, scheduled, and executed.
Scheduling is the main focus of this paper and it will be expanded on later. The execution stage is relatively straightforward; after a batch of transactions is scheduled, the TPU will:
- run checks: the worker thread checks that the transaction:
- hasn’t expired; by checking that the blockhash it references is not too old.
- hasn’t been included in a previous block.
- grab locks: the worker thread attempts to acquire the appropriate read and write locks for all the transactions in the batch. If a lock grab fails, retry the transaction later.
- load accounts and verify that signers can pay fees: the thread checks that the programs being loaded are valid, loads the accounts necessary for execution and checks that the signer can pay the fees specified in the transaction.
- execute: the worker threads create VM instances and executes the transactions.
- record: the execution results and the transaction ids sent to the PoH thread, which generates an entry; entries are also sent to the BroadcastStage during this step.
- commit: If recording succeeds, the results are committed, updating the state.
- unlock: Remove locks from accounts.
That’s a complete overview of the BankingStage. Next, we’ll dive deep into how scheduling works in the Solana TPU. This portion has had many significant changes, but for the sake of brevity, we’ll discuss only the two most recent implementations: the Thread-Local Multi-Iterator and the Central Scheduler.
Thread-Local Multi-Iterator
In the Thread-Local Multi-Iterator implementation, consumed transactions packets sit in the non_vote_receiver channel mentioned earlier. Each of the non-vote threads pulls transactions from the shared channel, sorts them based on priority and stores the ordered transactions in a local buffer.
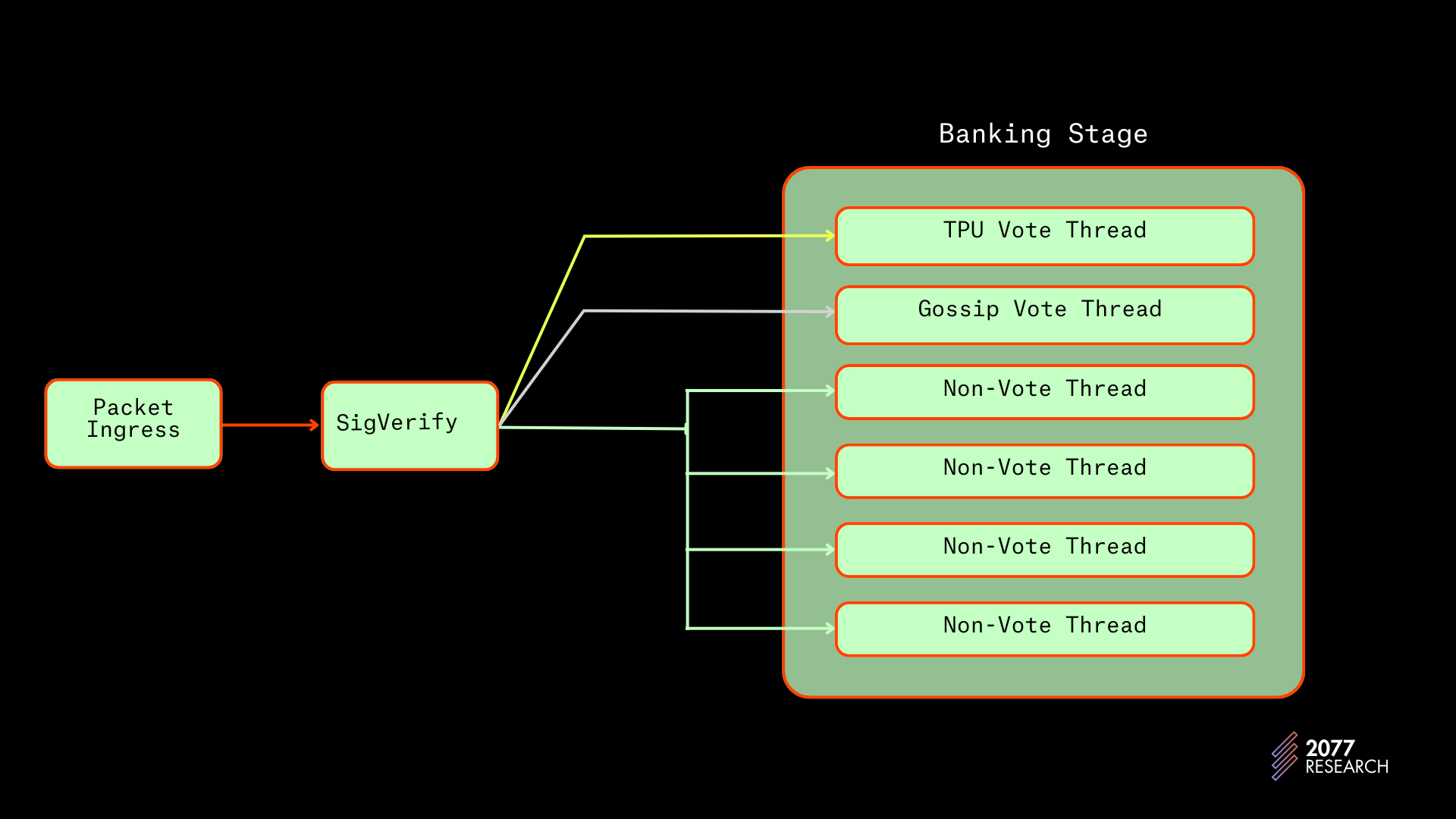
The local buffers in the TLMI are double-ended priority queues to allow for adding new high-priority transactions while removing the low-priority ones with minimal time complexity. Each thread then “marches” a multi-iterator through its buffer to create a batch of (128) non-conflicting transactions.
A multi-iterator is a programming pattern that runs multiple iterator objects through an array; the iterators “select” items from the array based on a decision function. The multi-iterator concept can be abstract so instead of explaining it, here is an example that shows how Solana’s TLMI works:
Imagine a set of ten transactions [tx1 > tx2 > tx3 >...tx10] with the dependency graph below:
tx1 → tx4 → tx5tx2tx3 → tx6
tx7→ tx9
Tx8 → tx10
Assuming the TLMI created batches of four, with this set of transactions, the TLMI would:
- select tx1, then tx2, then tx3, and finally tx7 for the first batch. tx4, tx5 and tx6 would be skipped because they conflict with already selected transactions.
- the next iterator would select tx4, tx6, tx8, and tx9 and
- the third iterator would select tx5 and tx10.
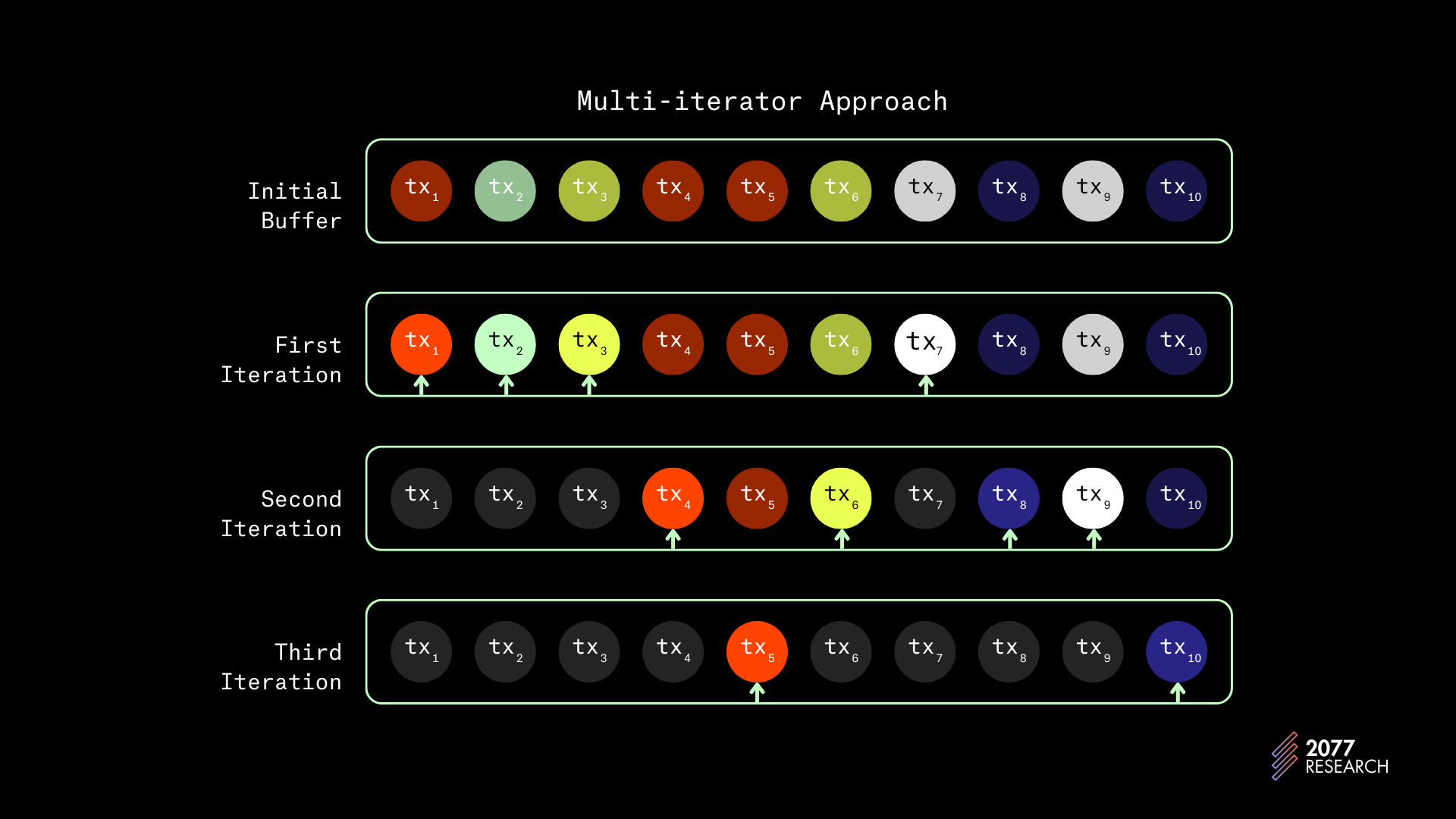
Each iterator would follow this process to create a batch of non-conflicting transactions and because of the use of locks during execution, transactions are guaranteed to execute safely regardless of what other threads are doing.
However, this design led to a lot of problems.
The problems with the TLMI implementation
The major problem with the TLMI approach is that each thread is isolated from the others.
Because each of the worker threads independently pulled transactions from the shared channel, the distribution of transactions between threads was roughly the same. So even if the threads create a batch of transactions with no intra-thread conflicts, there could still (and likely would) be inter-thread conflicts, with the problem becoming worse as contention increases.
In addition, because of the TLMI’s design, there is a high tendency for priority inversion—since two conflicting transactions cannot be in a batch, high-priority transactions that happen to conflict with a higher-priority transaction will not be scheduled until the next batch at the very least and lower-priority transactions would.
These problems could be approached by reducing the batch size (from 128) but that would create bottlenecks elsewhere, like increased context switching by threads. Instead, the scheduling algorithm was redesigned completely, leading to the Central Scheduler implementation.
The Central Scheduler
The Agave 1.18 client addresses the “central” problem of Solana’s BankingStage by introducing a “Central Scheduler” very similar in spirit to Block-STM’s Collaborative Scheduler. The Central Scheduler uses a new thread (in addition to the previous six) that performs the task of global scheduling. The way it works is relatively straightforward:
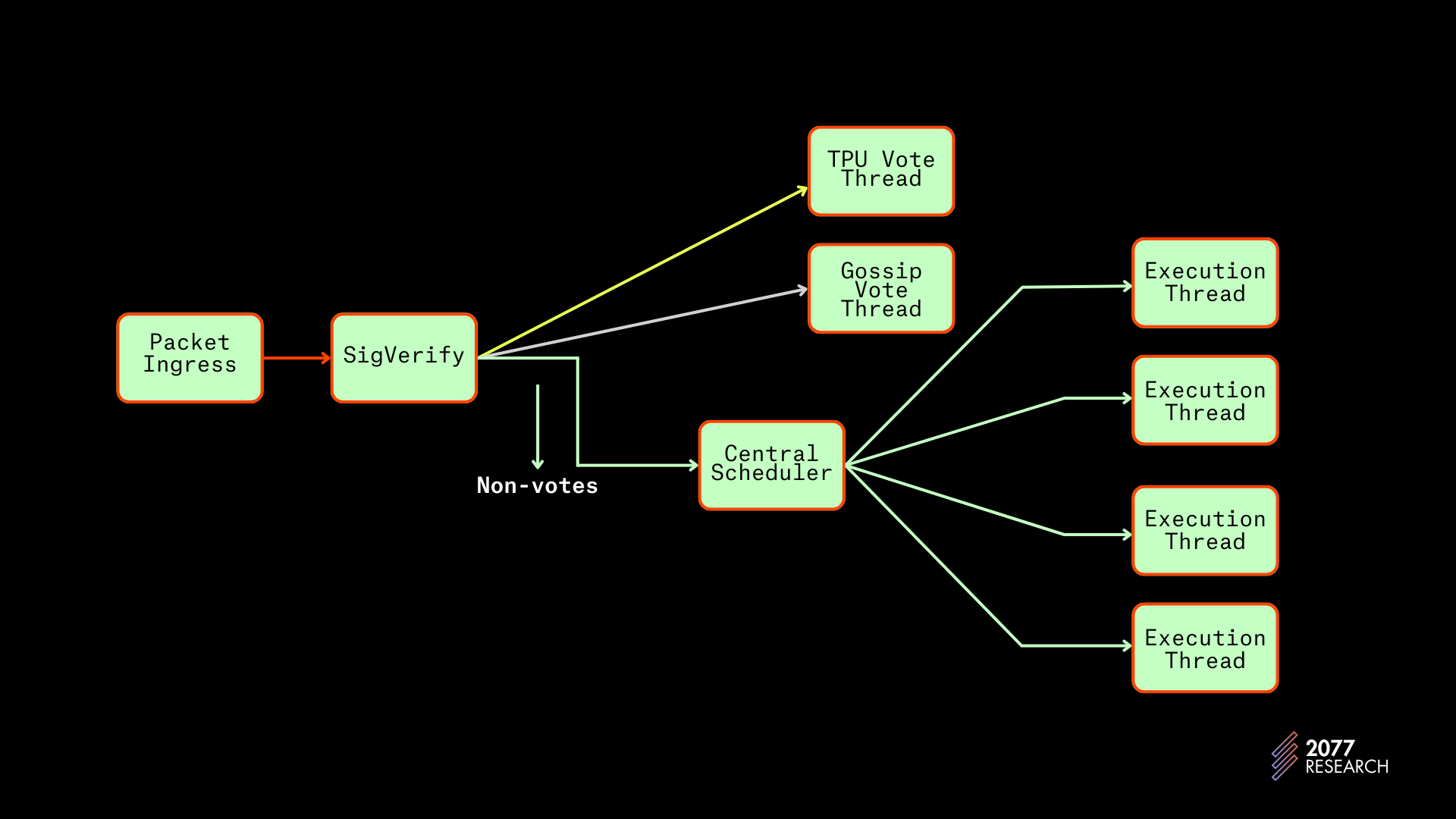
Just like before, voting transactions are handled by voting threads but now all none vote transactions go to a dynamically updated buffer. Since this buffer is fed directly from SigVerify, it has a global view of priority as opposed to the local buffers in the TLMI design.
The second major change in the Central Scheduler update is the addition of a priority graph. The “prio-graph” is a lazily populated Directed Acyclic Graph (DAG) that allows efficient identification (and visualization) of transaction dependencies. The Central Scheduler scans through a batch of transactions and populates the prio-graph by representing transactions as nodes and using edges (graph-theory term for a directed line) to represent dependencies.
Figure 15 below shows a sample prio-graph. The nodes (circles) represent transactions, the alphabets represent priority (A is of higher priority than B), numbers represent the accounts used by the transactions and arrows represent dependencies.
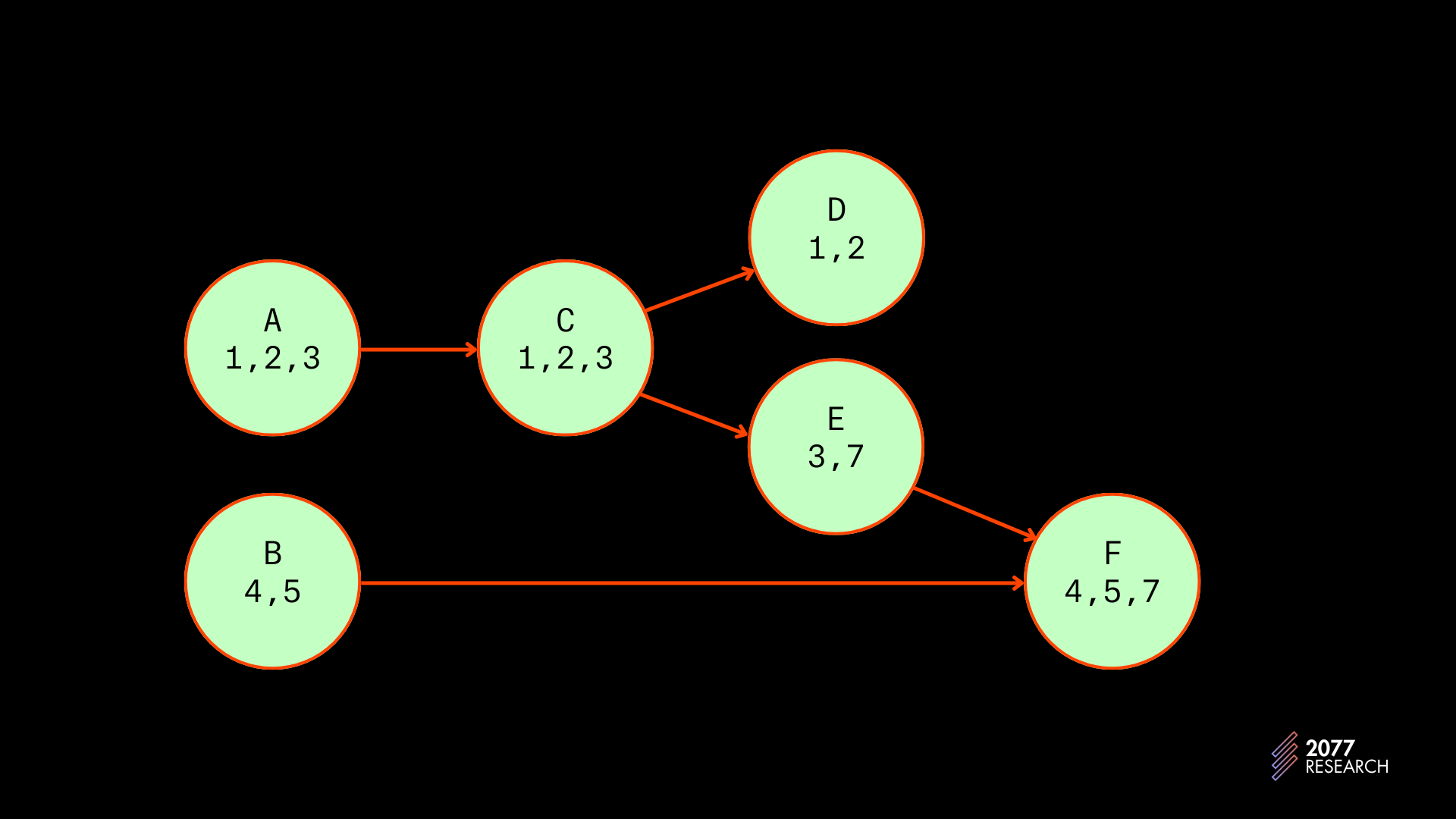
The prio-graph is necessary because Sealevel executes transactions in batches. If transactions were executed ad hoc, there’d be no need for a prio-graph, but since transactions are executed in batches[1], a prio-graph is necessary to prevent unschedulable transactions. An example that shows the problem is explored below.
Using the prio-graph in Figure 15 as an example, if the Central Scheduler wanted to schedule transactions A through F, it would schedule all of them on one thread. This might seem counterproductive because, at the very least, A and B do not conflict, but naively scheduling the transactions on different threads will lead to unschedulable transactions down the line. The reason is explained below:
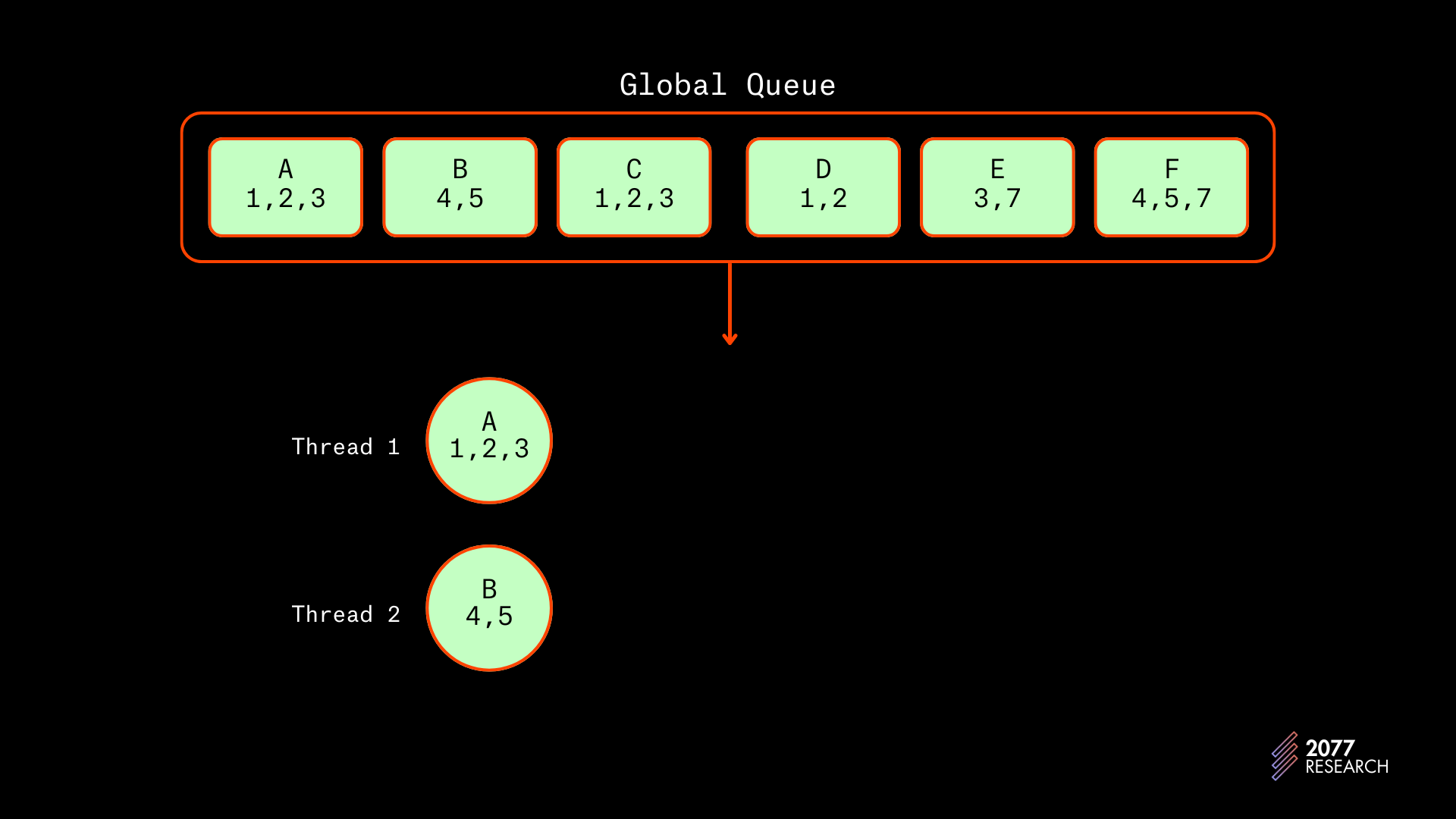
If the transactions are scheduled without a prio-graph (we’ll speed through this by moving in batches of two, but it suffices to show the problem):
- A and B would be scheduled first and on independent threads since they don’t conflict.
Then C and D would be scheduled behind A since they both conflict with A and only A.
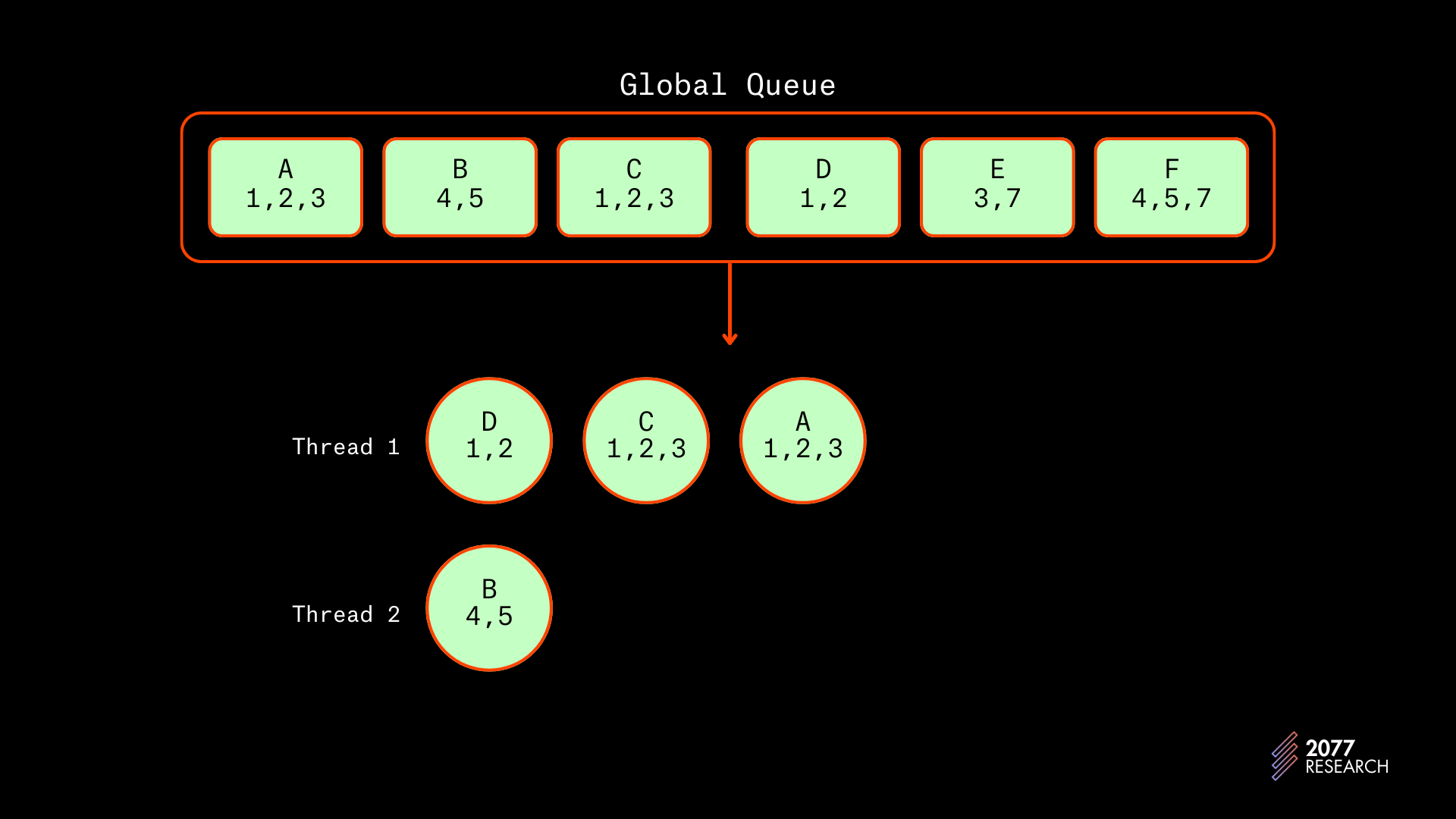
- E will be perfectly schedulable on thread 1 but F will be unschedulable as it will conflict with both threads. Thread 1 holds the locks for account 3 and thread 2 holds the locks for account 7 so F can only be scheduled after both threads have completed execution.
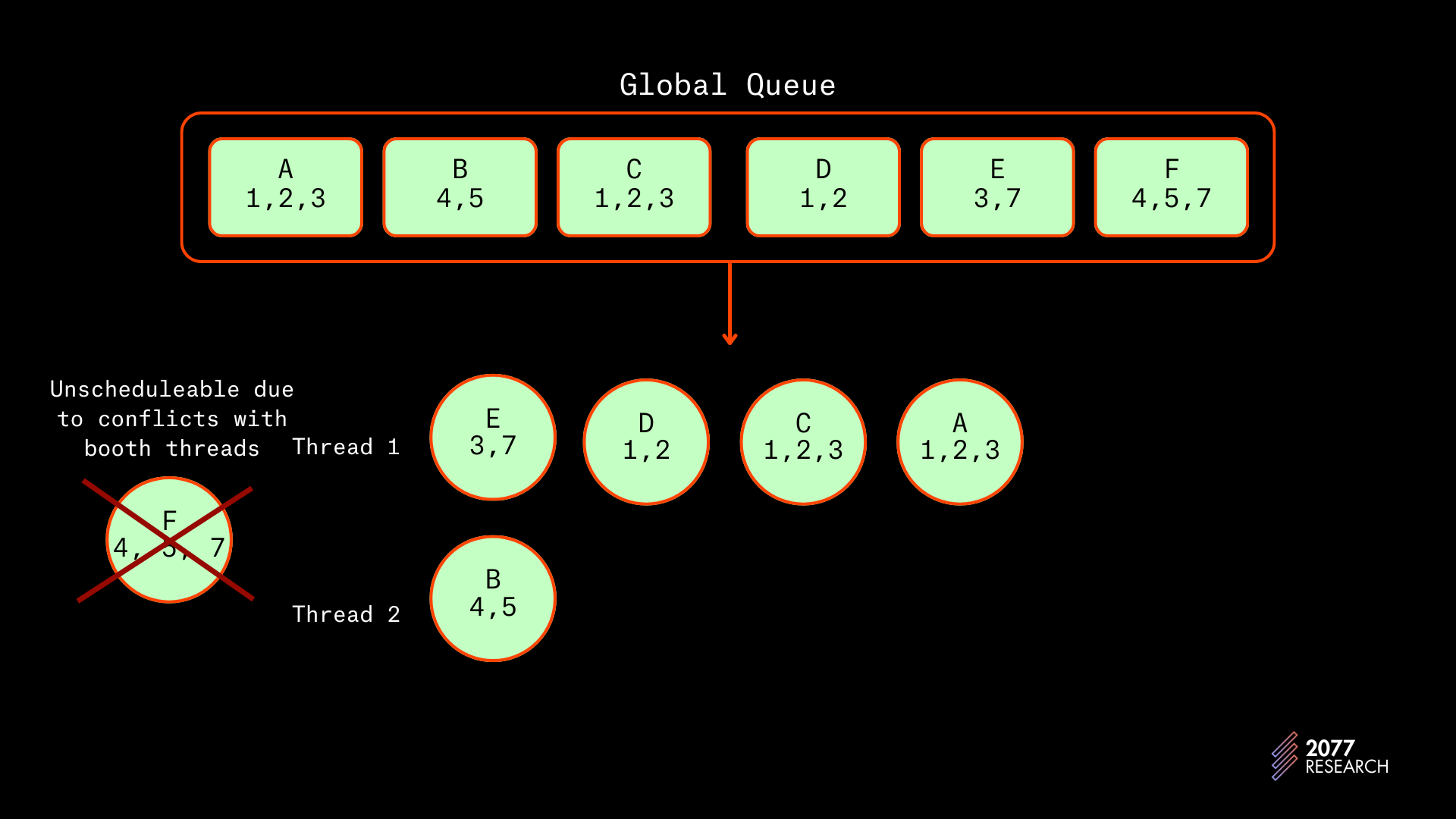
It is because of these types of conflicts that the scheduler needs a prio-graph when scheduling transactions. The combination of the global priority queue and prio-graph allows the Central Scheduler to schedule transactions in a manner that ensures that there are no inter-thread conflicts and avoids priority inversions.
How the Central Scheduler works
- Transactions arrive from the SigVerify channel and are split depending on whether or not they are vote transactions.
- The non-vote transactions move to a buffer, where they are sorted based on priority.
- The Central Scheduler scans the highest priority transactions and filters them before “inserting” them into the prio-graph in batches.
- When the target size is reached or the global queue is empty, the central scheduling thread begins to schedule transactions to the worker threads in a manner that avoids inter-thread conflicts.
- The batches of scheduled transactions are executed just as before.
The above is a basic overview of what the Central Scheduler does. Now for the details.
Just like in the TLMI implementation, transaction packets coming from SigVerify sit in the same 700,000 capacity buffer. However, in the Central Scheduler, when the node is leader, the packets are fed into another buffer called the TransationStateContainer. The TransactionStateContainer has two components:
- a double-ended priority queue, specifically a MinMaxHeap with a bubble-up feature that sorts transactions based on priority.
- a HashMap that maps the transaction ids to a “transaction state.” There are two possible states that a transaction can be in:
- unprocessed: transaction can be scheduled.
- pending: transaction is available for scheduling and processing.
To create a batch of transactions, the Central Scheduler takes the top 2048 transactions from the TransactionStateContainer, 128 at a time and applies a PreGraphFilter to each transaction in the batch of transactions.
The PreGraphFilter:
- sends the transaction to the bank to check if the transaction has been processed and
- checks that the transaction can pay the transaction fees, and deducts them from the fee-paying account.
Transactions that pass the checks are inserted into the prio-graph. The prio-graph is created by checking for dependencies between a transaction and the next highest priority transaction per account i.e, the graph builder checks for conflicts on every single account that the transaction touches. This is implemented by tracking in a HashMap what transactions last touched what accounts. This allows the graph builder to quickly identify dependencies.
Once the prio-graph has been completely built, transactions go through a pre_lock_filter. The pre-lock filter is currently unimplemented so it currently does nothing. But the ideal logic flow is to allow transactions that pass the pre_lock_filter to be scheduled one by one on the appropriate threads. A small optimization is that if a transaction does not conflict with any thread or any other transactions that could necessitate executing a chain in sequence, the transaction is assigned to the thread with the least amount of work (in terms of CUs). Transactions are scheduled until the prio-graph is empty or every thread either:
- reaches the max compute units assigned to it (currently 12 million CUs), or
- has a batch of 64 transactions assigned to it.
If any of these conditions is met, the worker thread(s) begins executing the batch. When it finishes, it communicates with the central scheduler thread and work is scheduled for it. This process is repeated until the node is no longer leader, at which point the BankingStage is said to be over.
I’ve left out the details of committing and forwarding as they’re not relevant to this discourse but the core idea has already been discussed.
That is a complete overview of how the Central Scheduler approaches parallelization. It is, in some aspects, a significant improvement over previous Sealevel iterations as it prevents intra- and inter-thread conflicts. In the CS (ceteris paribus), there should never be a failed lock grab, which was the main cause of non-linear performance degradation with the other iterations. In addition, since there are no more inter-thread conflicts, the Central Scheduler allows the use of as many non-vote threads as are available for execution.
The biggest trade-off of the Central Scheduler is the overhead incurred during scheduling. Compared to Block-STM or even the TLMI, it spends a decent amount of time scheduling transactions and has less to spend on execution. Another trade-off is that unlike the TLMI that had all the available threads deserializing and parsing transactions, only one thread (the CS) is responsible for these tasks now.
That wraps up the discussion of the design of the CS and, by extension, Solana’s TPUs. Next, we’ll examine their performance.
Sealevel Performance
There are quite a number of Solana benchmarks in the wild. But for the purpose of this report, we modified the agave client codebase and ran the “banking-bench” tests. Links to the repo as used and instructions to reproduce the results can be found in the appendix. The tests were run on the exact same machine used to evaluate Block-STM—Latitude’s m4-metal-large, which has 384 GB of RAM and an AMD EPYC 9254 CPU with 24 physical and 48 logical cores. The tests are the exact same as those used to evaluate Block-STM as well. The results are shown below.
TLMI
The data for the TLMI runs are shown in figures 18-21 below. The TLMI has a maximum throughput of 137k TPS observed on 8 threads at a block size of 10k and account contention of 10k (essentially embarrassingly parallel). The TLMI also performs relatively well in very contentious scenarios, processing over 15k TPS for completely sequential workloads.
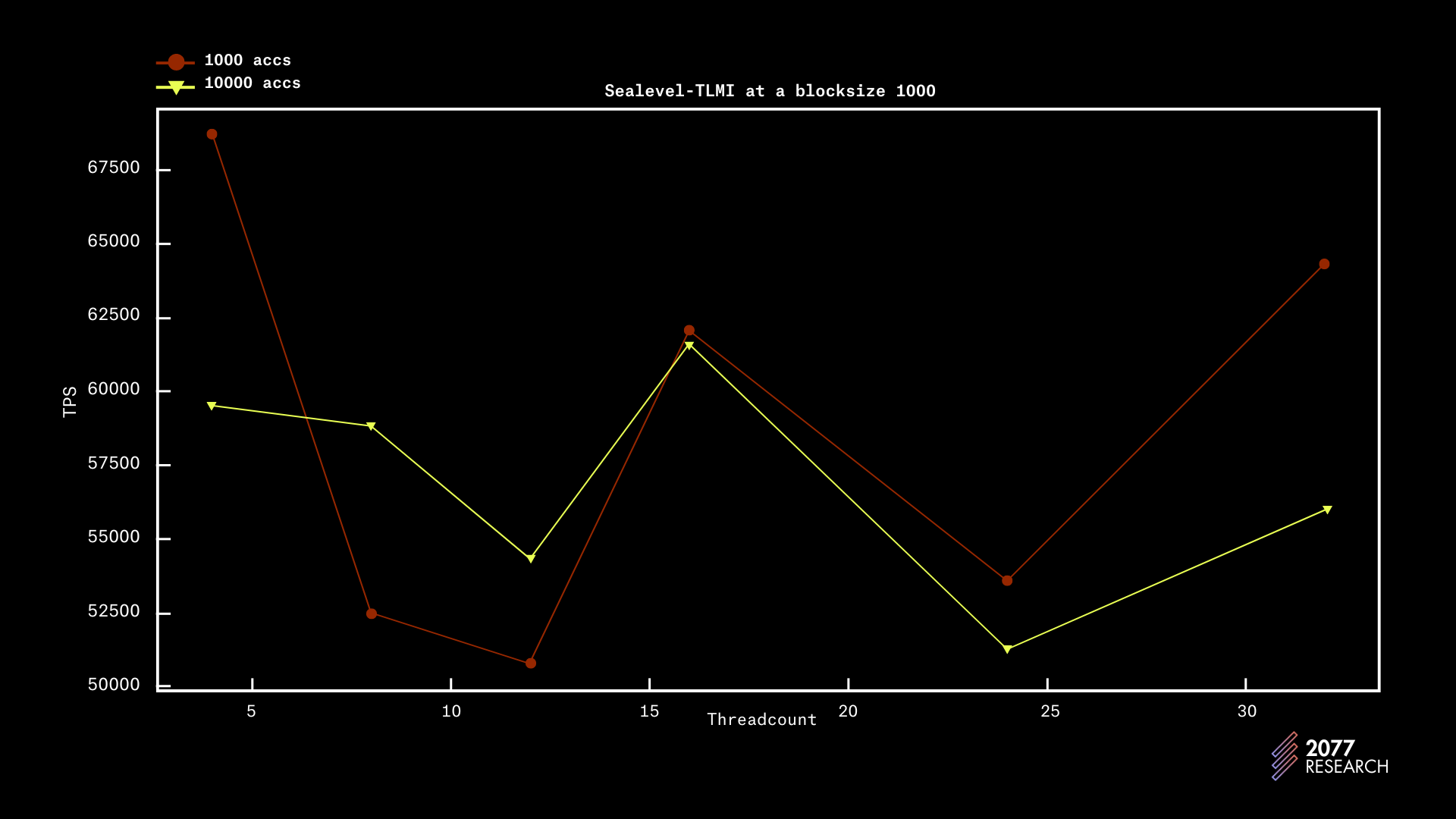
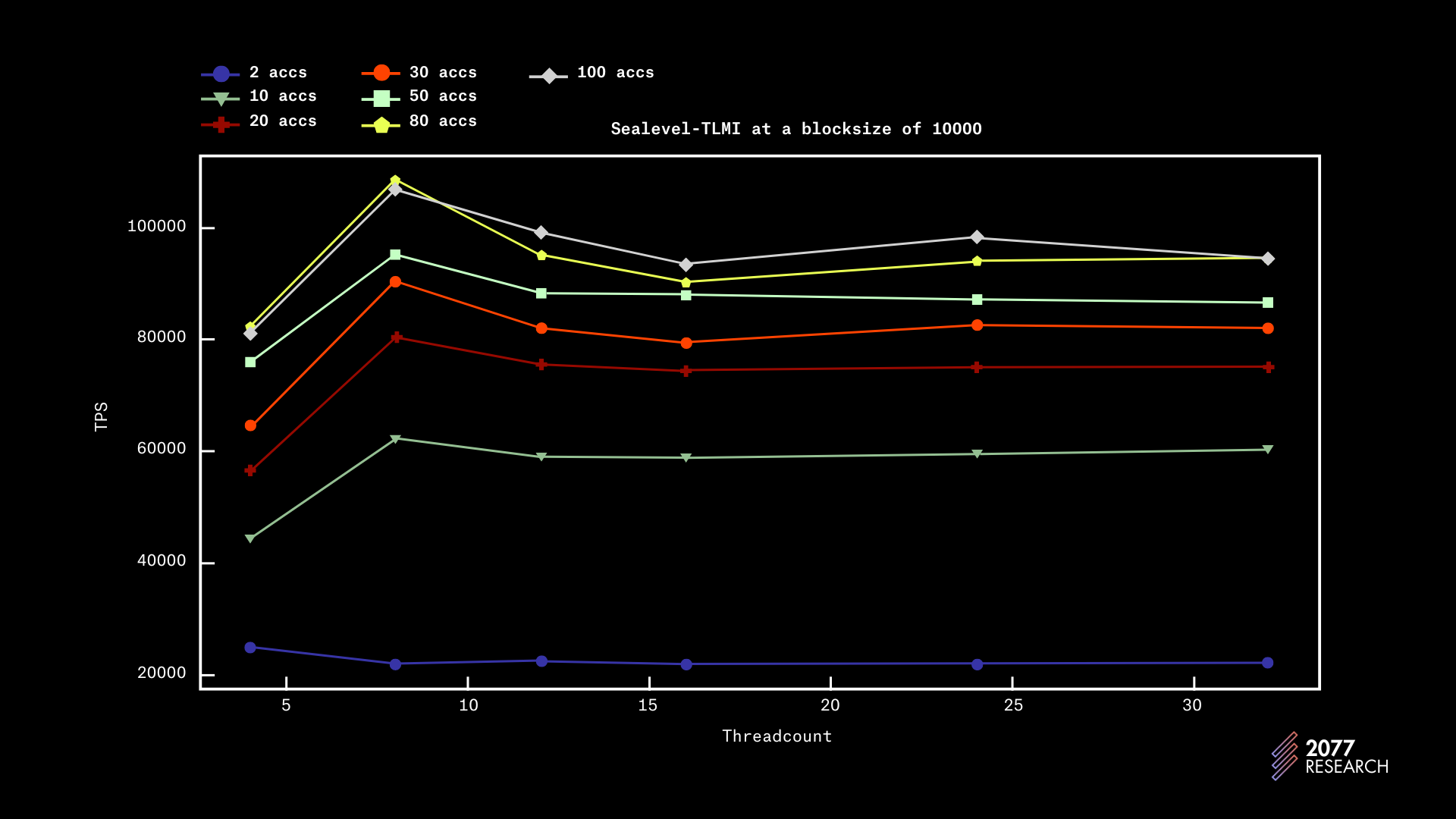
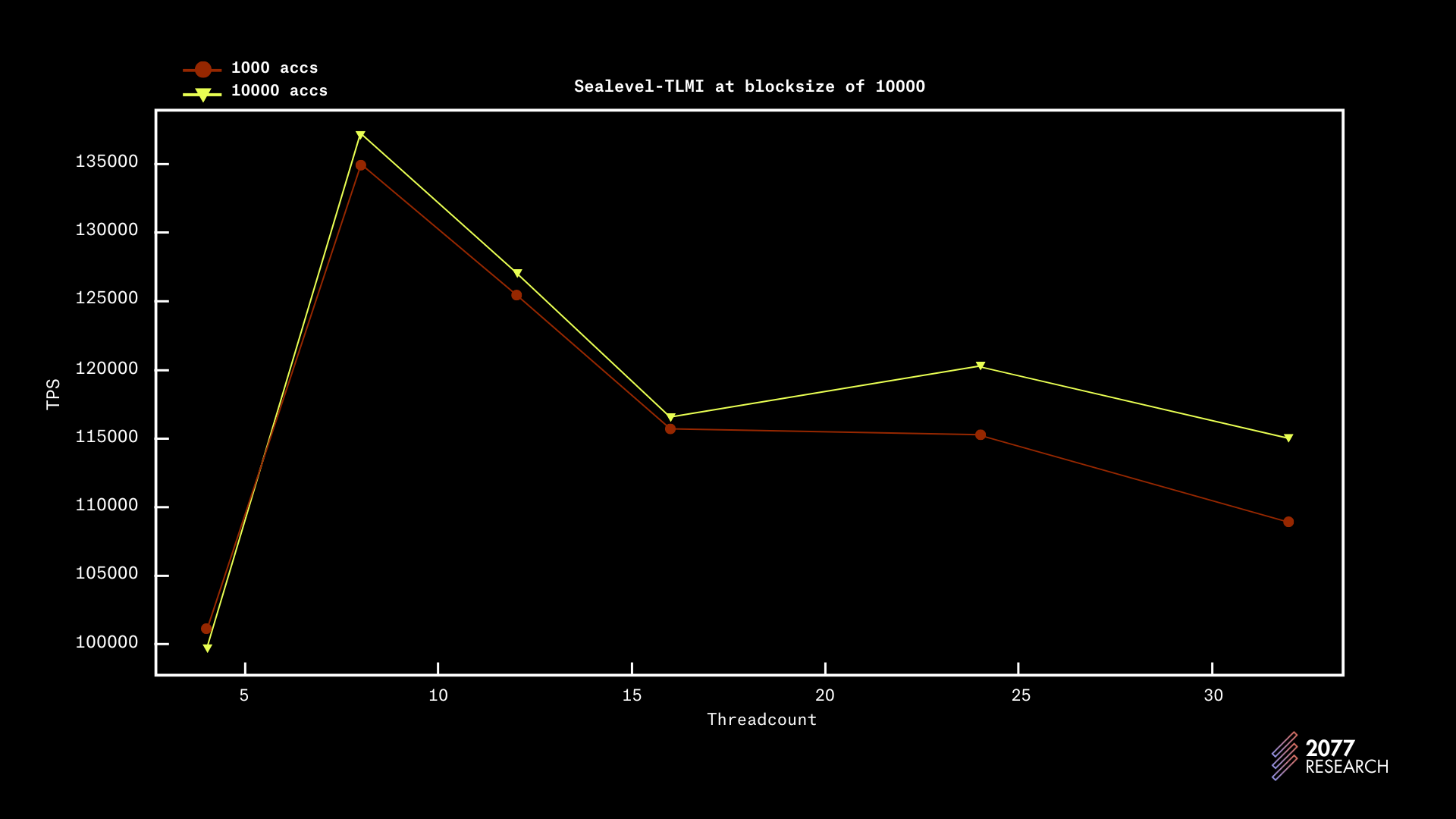
The performance trend of the TLMI is relatively less steep (it reaches about half of its maximum throughput with an account contention of 10), i.e., the performance in contentious and non-contentious situations is similar. This implies that the TLMI will not experience significant performance degradation in contentious situations.
The data contains a few surprising facts. One of which is that with a block size of 1k, performance peaks with 4 threads regardless of contention. With a block size of 10k, performance consistently peaked at 8 threads and even slightly degraded as core count increased.
This behavior is understandable for threadcounts 24 and 32, as the machine used during testing only has 24 physical cores and there are some other processes running in the background, e.g., PoH. But the behavior is unexpected for threadcounts 12, and 16 and seems uncorelated to contention. There’s not enough data to assert a trend but it would seem the TLMI’s peak throughput is correlated to block size. This suggests that there’s still room for growth in regards to optimizing the performance of the TLMI.
But overall, the TLMI is a highly performant TPU that performs well in both contentious and non-contentious environments.
Central Scheduler
The decision was made to exclude the performance of the central scheduler because it was found to be inconsistent. Our tests saw it peak around 107k TPS with 10k account contention and as high as 70k TPS on a completely sequential workload. In another implementation of the tests, we get 30k TPS on completely sequential workloads and ~90k TPS with an embarrassingly parallel workload.
These results are consistent “within” the tests and rerunning the tests will produce the same results. But the inconsistency across tests suggests that there are still bugs in the implementation that need attention. Because of that, we decided to leave the evaluation and presentation of the results to a future study.
A few conclusions that we can draw regardless are that relative to the TLMI, the performance will be better in highly contentious scenarios and (slightly) worse in low-contention scenarios.
With Sealevel thoroughly discussed, we can move on to the highlight of the report.
Block-STM vs. Sealevel
Both TPUs have been thoroughly discussed and evaluated; it’s time to compare them. We’ll start with the fee market structures that both TPUs enable and move on to performance.
Fee-Markets
Appropriately pricing blockspace is a difficult challenge to solve. To put it more eloquently:
“One of the most challenging issues in blockchain protocol design is how to limit and price the submission of transactions that get included into the chain.”
A proper discussion on fee markets would fill up its own paper. But on the subject of comparing Block-STM and the Sealevel it is relevant to mention that due to the designs of both TPUs, the fee market structures are completely different. Specifically, Sealevel has pseudolocal fee markets, while Block-STM’s fee markets are global.
In local fee markets, contention for a portion of state does not affect other portions of state, while in global fee markets, the cost of blockspace depends on general demand for blockspace, irrespective of what portion of state a transaction is accessing.
Local fee markets are clearly more ideal from every point of view:
- for users, the UX is superior because users are not forced to compete with transactions accessing portions of state they are not accessing.
- for validators and the network (ceteris paribus), local fee markets make for more efficient use of block space as there will be fewer failed transactions.
In short, local fee markets are superior but they are very hard to implement. I’ll explain next the fee-market structure of each TPU.
Block-STM Fee-Markets
As mentioned above, Block-STM’s fee markets are global. Ironically, this is a consequence of the design choice that is responsible for Block-STM’s performance boost—the predefined ordering of transactions.
As discussed when analyzing Block-STM’s design, when Block-STM wants to execute a BLOCK of transactions, it pulls an already-ordered set of transactions from its mempool (or Quorum Store in the new design) and executes the BLOCK. Because the BLOCK had already been constructed prior to execution and inclusion in the block was based on gas fees, securing inclusion in the block is solely dependent on gas fees.
For example, in the event of a highly contested NFT mint where the highest priority transactions are competing for the same account, most, (if not all) the transactions packed into the BLOCK will compete for the same state. This will:
- significantly degrade the performance of Block-STM (since it performs poorly in high contention situations).
- prevent the inclusion of non-conflicting transactions and unnecessarily drive up the price of blockspace, as seen on networks with single-threaded TPUs like Ethereum and other EVM-compatible chains.
We’re more focused on the latter point in this section and what it implies—that all users on Block-STM networks will be forced to compete with each other for blockspace. Considering historical data on networks like Ethereum, blockspace could become unnecessarily expensive during times of high activity. And during sustained activity, fees will be higher for all users. This is a problem, as it suggests that blockspace on BSTM networks must be cheaper and more abundant than on a Sealevel network for users to pay similar amounts in fees.
Sealevel Fee-Markets
All iterations of Sealevel have always had some form of fee market locality but the fee markets were barely functional for the reasons discussed above (local view on priority). Post-Central Scheduler, Sealevel’s fee markets are functional and "pseudolocal." Transactions bidding for inclusion and priority only have to bid against other transactions contesting the accounts they want to access.
For example, if transactions tx1 through tx4 are all bidding for the same portion of state, tx5 doesn’t have to bid against all the previous transactions. In the current scheduler design, it will be scheduled second, while transactions tx2 through tx4 are all queued behind tx1. This is a very simple example but it holds true for any batch of transactions with any type of transaction dependency.
It's important to understand that there is (and will always be) some global pricing of blockpace because of block size limits (currently 48 Million Compute Units (CUs)). Transactions that don’t conflict with other transactions in the block may never make it into the block simply because their absolute priority is not high enough. But once a transaction can pay some “minimum inclusion fee (𝚽),” fee-markets are local.
Solana further improves its fee-market locality by constraining the maximum number of CUs that can be taken up by a single account in a block (the current implementation is 12 million CUs). This ensures that transactions competing for highly contested accounts cannot prevent the inclusion of other transactions, even if the former set of transactions, for some reason, executes much faster.
The data collected during this study suggests that there might be benefits to lowering the limits relative to blockspace but that’s a discussion for another day.
To summarize, Sealevel implicitly enables local fee-markets and locality is reinforced by the account limits.
Next we’ll move on to actual throughput from both TPUs.
Performance
With all the necessary background discussed, the time has come to answer the question of which TPU performs better. The two figures below show the performance of both TPUs for different at blocksizes 1k and 10k. The results show that Sealevel is significantly more performant across the board. For the sake of reading convenience, only the data for 2, 10, 50, and 10000 accounts were shown, as they suffice to represent most of the landscape.
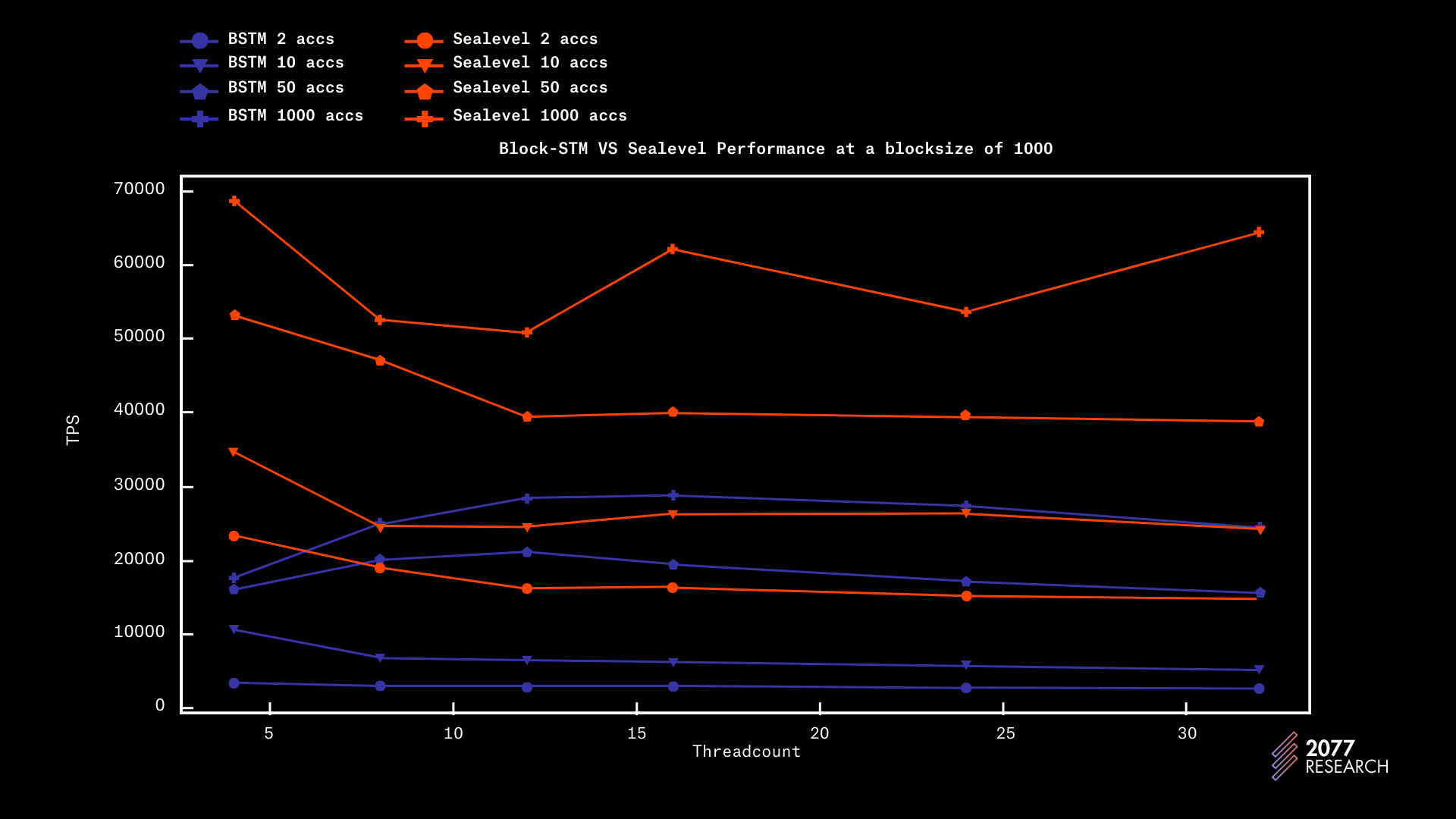
Figure below shows performance at a blocksize of 1k and Sealevel completely outperforms Block-STM. With a completely sequential workload, there’s a roughly 7x difference in performance and with a highly parallelizable workload (10k accs), there’s a 2.4x difference in performance.
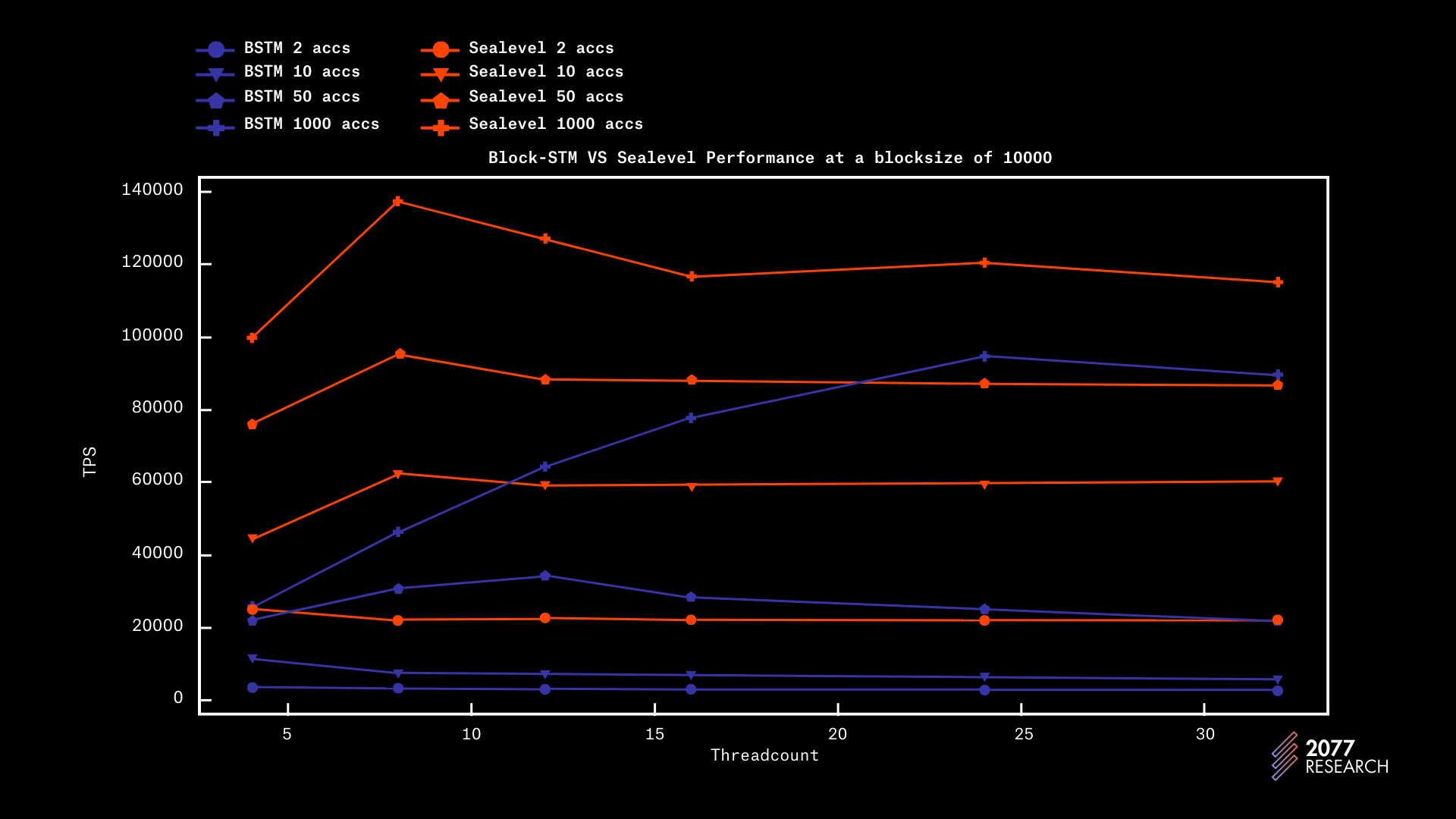
With a blocksize of 10k, Sealevel has a 45%, 53, and 118% performance boost over Block-STM, with account contention 100, 1k, and 10k respectively. These results are better than the 1k tests and are attributable to the reasons discussed earlier.
The results are surprising, as years of research on concurrency control have concluded that OCC is highly suited for low contention workloads and PCC for high contention workloads[2].
In isolation, Block-STM conforms to this standard, with performance improving significantly as contention is reduced. However, regardless of contention, when compared to Sealevel, Block-STM falls behind significantly.
We investigated this and spoke to members of Aptos Labs and found some potential explanations. We provide some context and our findings below.
During testing, we had benchmarked Block-STM with a much earlier iteration of the MoveVM and the observed throughput is more than double the results presented (we got throughput as high as 193k TPS with blocksize: 10k, account-contention: 10k) and overall, Block-STM was much more competitive in contentious scenarios and outperformed Sealevel in non-contentious situations.
While the performance of Block-STM from those tests is legitimate, those numbers cannot be used for a fair comparison as the execution VM and parts of the underlying program used to obtain them were not production-ready. After discussing this with the Aptos Labs team, we understood that this degradation occured because of the additional checks added to the MoveVM.
This suggests that Block-STM’s true potential might be handicapped by the complexity of the MoveVM. We say might as benchmarking Block-STM with Diem Move produces similar results as the ones presented, suggesting that the presented results might be the true limit of Block-STM’s ability with a production-ready VM.
Another factor that can explain the performance gap is that Sealevel executes transactions in batches as opposed to Block-STM’s ad hoc execution. The increased context switching from ad hoc execution likely adds some overhead.
As to the question of what TPU will perform better in real-world situations, it is true that it’s impossible to describe real-world contention with a single number. But Block-STM is too far behind, regardless of contention. However, just to be thorough, we’ll briefly attempt to estimate real-world contention by looking at historical blockchain data and how contentious it is.
Visualization of blockchain contention
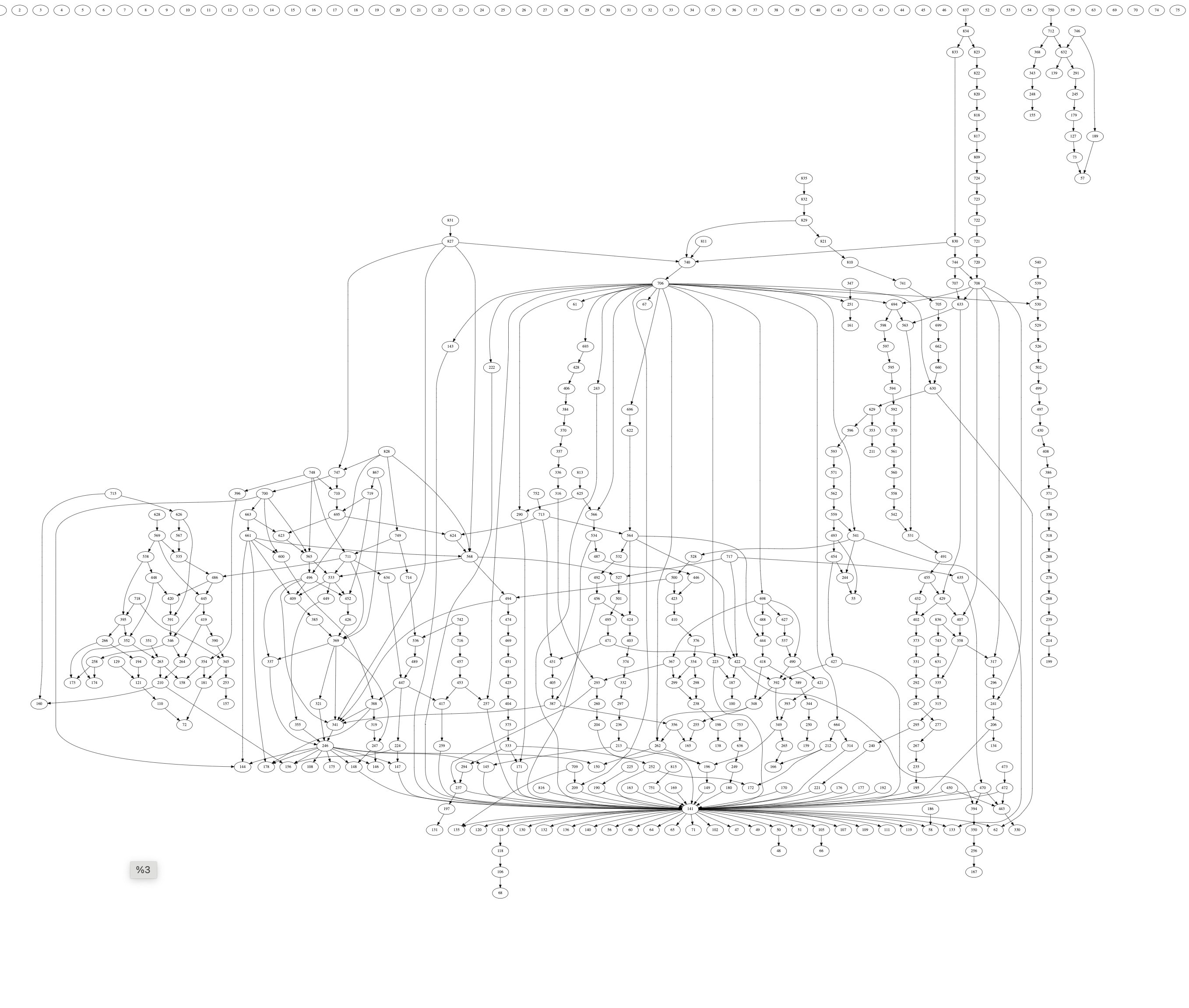
Contention can be visualized using the same prio-graphs that the Central Scheduler uses to identify transaction dependencies. The prio-graphs shown when describing the Central Scheduler were fairly simple. Real priority graphs, shown in the figures below are much, much more complex. The following prio-graphs are prio-graphs for both Ethereum and Solana blocks, as these are the only two networks with enough data to accurately model contention.

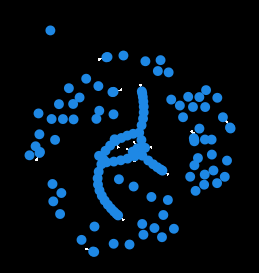
The figure above shows the prio-graph for Solana slot 229666043. The graph has 89 components (distinct subgraphs of transactions.) Most of these components have simple structures, with many having zero-dependent transactions or simple sequential dependencies. However, a large number of transactions are part of very complex trees.
Zoom in to see dependencies, keeping in mind that the priority of a transaction is indicated by the color of the node. Also remember that the further out a transaction is from the center of a component, the fewer dependencies it has. Nodes in the center of a component depend on all the transactions outward from them; in all directions.
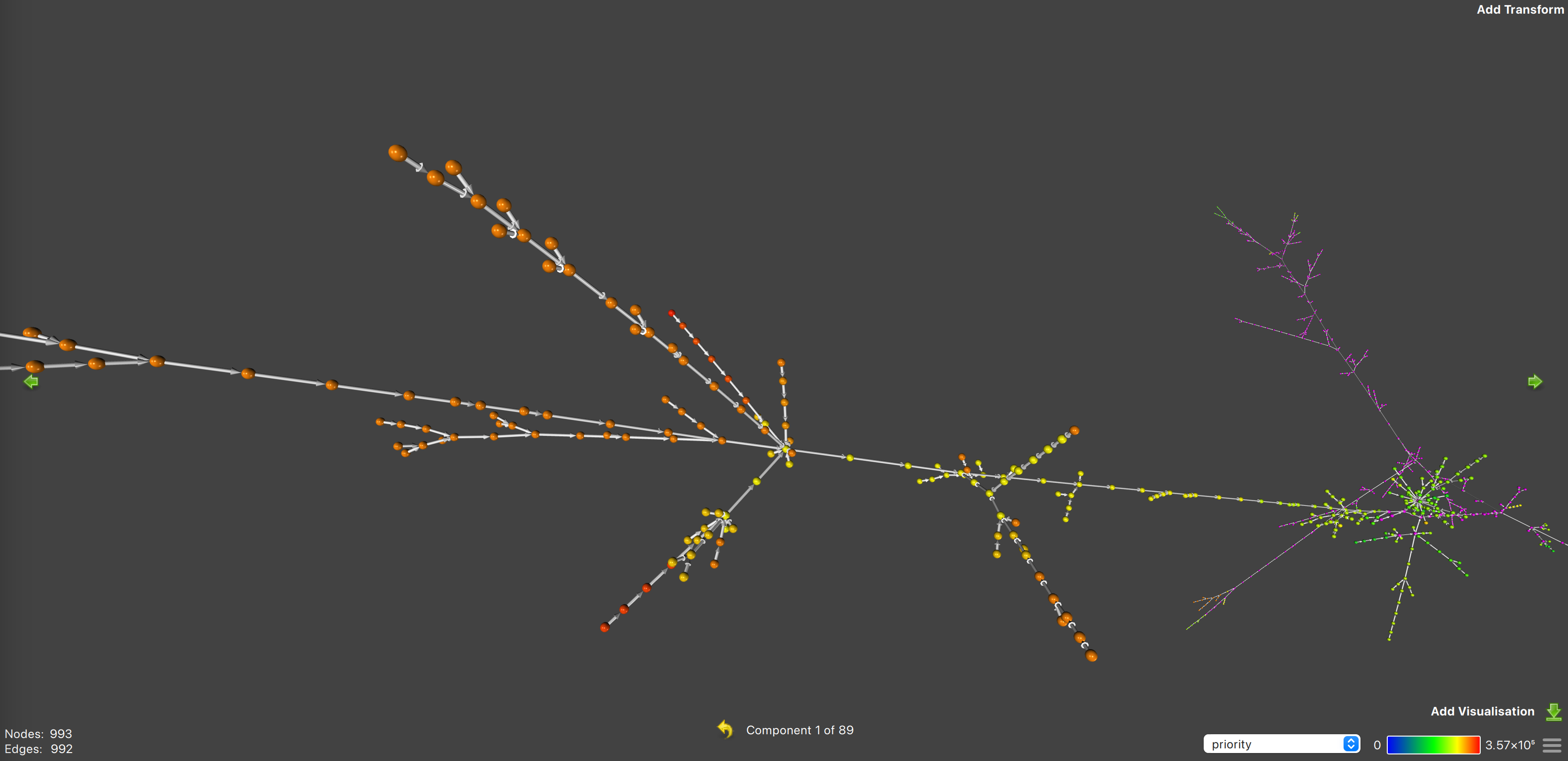
The figure above shows a closer shot of the largest tree and the structure is fairly complex.
The data above show that blockchain transactions are very contentious—a fairly large set of accounts have very low contention but the vast majority of transactions are in straight, long branches of very large trees. The straight, long branches suggest that the transactions contend over the same accounts and the size of the trees relative to the smaller clusters suggests that most transactions are contentious. But most interestingly, the number of branches suggests that many accounts are contentious, not just a small set.
More prio graphs tell the same story:
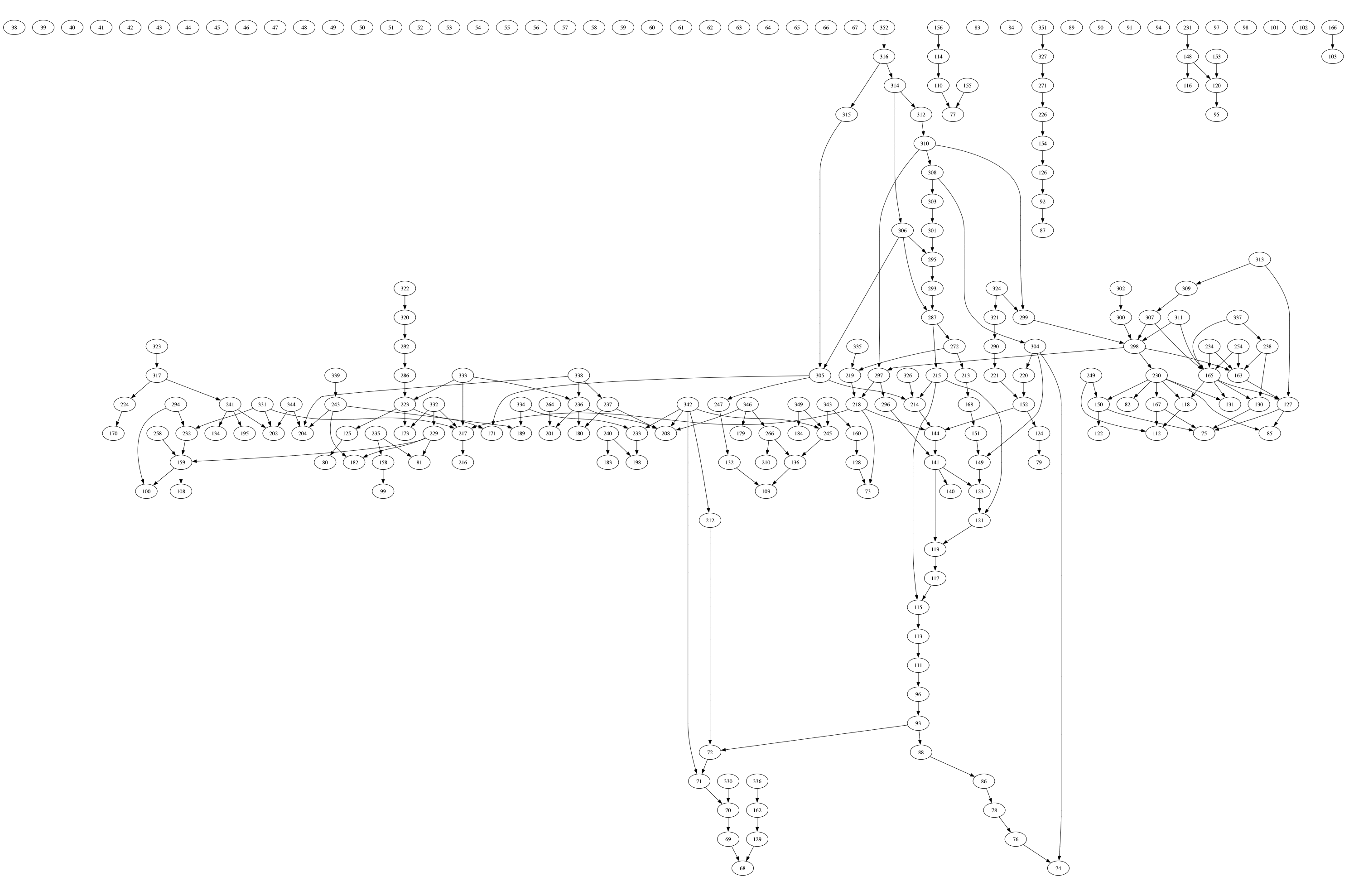

In summary, state access on blockchains is very contentious. The more nuanced conclusions that can be drawn from looking at the data are:
- most high-priority transactions are for highly contested portions of state
- state access is contentious but also highly parallelizable—there are many hotspots (of varying “temperature”) as opposed to one large hostpot.
- a reasonably large set of transactions do not contend with any others. This set is small relative to the set of transactions that do (as small as 10%), but not infinitesimal.
So what does this mean for Block-STM and Sealevel? Well, it strengthens the argument that Sealevel will perform better in real-world scenarios. The extent of “better” is a question that can only be answered by more involved simulations but the current data strongly indicates that Sealevel will perform significantly better in real world use.
All said, it’s important to note that because of Block-STM’s primitive dependency identification and other optimizations2, 3, Block-STM will perform much better than traditional OCC TPUs. But it’s performance will likely never match that of Sealevel.
The case for OCC and Block-STM
As we approach the end of this paper, it’s easy to walk away with the impression that OCC (and, by extension, Block-STM) is pointless—years of research and test data suggest that it’s practically guaranteed to be slower than PCC in an environment like blockchains, where state access is fairly contentious. In addition, Block-STM seems like a step backwards in the context of Transaction Fee Markets (TFMs) as it lacks one of the major benefits of concurrent execution—local fee markets. However, Block-STM has made many improvements to the traditional OCC design and will perform much better than previous OCC TPUs. In addition, there are three more benefits of Block-STM’s design that are worth noting.
Wider Range of Supported Applications
The primary advantage of an OCC-TPU is that it allows for arbitrary transaction logic. Since PCC-TPUs require that transactions declare upfront the portions of memory they will access, it is impossible to write transactional logic where a transaction decides to read or write certain memory locations based on information discovered during execution.
A good example is on-chain orderbook design. Orderbooks on PCC-TPUs usually cannot offer atomic settlement (or permissionless market making) and limit orders since transactions must specify upfront what accounts will be accessed during the transaction. To work around this, most orderbooks on Solana required the aid of an additional entity—the cranker—to finalize limit orders. Phoenix on Solana has managed to overcome this by holding all the balances in one account but this approach faces its own struggles. OCC TPU orderbooks like Aptos.
Portability
The final argument for Block-STM is that it can integrate with any blockchain without breaking compatibility with existing transactions. There have been attempts to have transactions optionally specify upfront what portion of state they’ll be accessing on Ethereum in a bid to increase the efficiency of the EVM but they never saw the light of day. Because of Block-STM’s nature, it can be (permissionlessly) integrated into any blockchain without breaking consensus. Even Solana clients can implement Block-STM with modifications to ensure that the blocks meet all the constraints without a formal proposal. It is specifically for this reason that Monad and all other parallel EVMs use Block-STM to achieve functional parallelization of the EVM.
For these reasons—arbitrary transaction logic, improved developer experience, and portability—OCC-execution engines are at least worth exploring.
Conclusion
Over the course of this paper, we’ve considered two opposing paradigms to improving blockchain execution: Optimistic Concurrency Control (OCC) and Pessimistic Concurrency Control (PCC) by looking at the leading implementations of both paradigms. Both designs (Block-STM and Sealevel) are extremely innovative and undoubtedly a much more efficient use of hardware than sequential TPUs.
Block-STM uses OCC and insights from dDB design to improve concurrency without sacrificing developer experience. While Sealevel relies on established lock-based techniques and hardware-maximizing design to increase performance at the cost of some use cases and a more difficult developer experience.
Overall, both Block-STM and Sealevel are great leaps from sequential TPUs and have set new standards for blockchain TPUs. In the current landscape, it’s hard to appreciate them as there are other bottlenecks but as the other components of blockchain pipelines continue to improve, the importance of the TPUs will only become more apparent.
References
- Concurrency control
- Concurrency Control in DBMS - GeeksforGeeks
- Multiversion concurrency control
- Database transaction
- Database transaction schedule
- Lock (computer science)
- Two-phase locking
- Conservative two-phase locking
- Deterministic transaction execution in distributed database systems | Guide books
- Deadlock
- Solana Account Model | Solana
- Solana Validator Educational - Transaction Lifecycle
- Programs | Solana
- Transactions and Instructions | Solana
- Solana Instruction Source Code
- Solana Transactions in Depth
- Lollipop: SVM Rollups on Solana Version: 0.1.0
- Transaction Confirmation & Expiration | Solana
- Solana Validator Educational - Transaction Lifecycle
- Lifecycle of a Solana Transaction | Umbra Research
- Sealevel — Parallel Processing Thousands of Smart Contracts
- Spotlight: Solana's Scheduler
- Introducing the Central Scheduler: An Optional Feature of Agave v1.18 - Anza
- What’s new with Solana’s transaction scheduler?
- Solana Scheduler
- All You Need to Know About Solana's v1.18 Update
- Solana Core Banking Stage Source Code
- Transaction confirmation
- Spotlight: Solana's Scheduler
- Introducing the Central Scheduler: An Optional Feature of Agave v1.18 - Anza
- What’s new with Solana’s transaction scheduler?
- Solana Scheduler
- All You Need to Know About Solana's v1.18 Update
- Solana Core Banking Stage Source Code
- Transaction confirmation
- The Aptos Advantage: Moving at Scale | Blockworks Research
- Orders | Econia Docs
- Seats | Phoenix DEX
- Aptos Ecosystem Leading the Way with Parallelism
- Ethereum Improvement Proposal (EIP) Issue #648
- Designing Multidimensional Blockchain Fee Markets
- Multidimensional Blockchain Fees are (Essentially) Optimal
- Parallel Virtual Machine
- Avalanche Dev Docs: Create Without Limits
- Execution - Solana Virtual Machine (SVM) | Eclipse Documentation
- Introduction to Virtual Machines - Part 1 Zoom recording of online class on April 13th 2020
- Building a VM Instruction Set in Rust
- JVM (java virtual machine) architecture - tutorial
- arxiv.org
- The Agave Runtime
- edgar on Twitter / X
- What is eBPF? (Extended Berkeley Packet Filter)
- eBPF Explained: Why it's Important for Observability
- What is eBPF? An Introduction and Deep Dive into the eBPF Technology
- In Rust We Trust - Berkeley Packet Filter and Rust
- Distributed database
- Partition (database)
- What are ACID Transactions?
- Embarrassingly parallel
- IPv6 packet
- Branching instructions in 8085 microprocessor - GeeksforGeeks
- Single instruction, multiple data
- Basics of SIMD Programming
- Types of Instructions in Computer Architecture | GATE Notes
- Thread (computing)
- The Difference Between CPU Cores and Threads
- Defining Multithreading Terms (Multithreaded Programming Guide)
- Assembly language
- Optimizing Scheduler Performance: Accelerating Packet to Transaction Conversion
- Serialization
- Min-max heap
- Directed acyclic graph
- Channel (programming)
- Frequency scaling
- Work stealing
- Terminology | Solana
- What do “State” and “State Change” Mean in Blockchain?
- Threads and Locks (PDF)
- Deferred Execution | Monad
Paper References
- Maurice Herlihy and J. Eliot B. Moss. Transactional memory: architectural support for lock-free data structures. Proceedings of the 20th annual international symposium on Computer architecture (ISCA '93). Volume 21, Issue 2, May 1993.
- Optimistic versus pessimistic concurrency control mechanisms in database management systems
Repos for tests
Glossary
CPU Architecture
This section will provide concrete definitions for computer hardware terms that showed up during the report:
- A CPU core is essentially a CPU in and of itself. It has all the necessary components to qualify as a full CPU and is capable of executing tasks by itself. Most modern CPU chips have multiple cores that share memory and I/O hardware.
- A thread is an abstraction that roughly refers to a series of instructions executed by a CPU core.
- Multithreading is executing a program (not a transaction) across multiple threads.
- Hyperthreading allows CPU cores to execute two threads pseudo-simultaneously. The core shares its resources between two threads in a way that improves parallelism but it’s not the 2x performance that’s often implied.
- Parallel vs. Concurrent
- A parallel program uses multiple CPU cores, each core performing a task independently. On the other hand, concurrency enables a program to deal with multiple tasks even on a single CPU core; the core switches between tasks (i.e. threads) without necessarily completing each one. A program can have both, neither of or a combination of parallelism and concurrency characteristics.
- Concurrency focuses on managing multiple tasks efficiently with one resource, parallelism utilizes multiple resources to execute tasks simultaneously, making processes faster.
- Concurrency is when two or more tasks can start, run, and complete in overlapping time periods. It doesn't necessarily mean they'll ever both be running at the same instant. For example, multitasking on a single-core machine. Parallelism is when tasks literally run at the same time, e.g., on a multicore processor.It should be clear now why transaction processing in blockchains is more analogous to concurrent processing than parallel processing.
- Other Terms
- Instruction: An instruction is the most granular operation that a processor can perform. They can vary in complexity based on the computer’s instruction set architecture, but the idea is that an instruction is guaranteed to be atomic by the hardware design.
- Bytecode: Bytecode is an assembly code-like intermediate representation. In this context, it refers to a VM’s instruction set.
- Assembly language: Assembly language is a low-level language with constructs that map 1:1 with the underlying CPU’s instruction set.
- locking granularity: refers to how precise locks are. Imagine a transaction needs to alter an element in a table; a coarse lock could lock the entire table; a more granular lock could lock the row/column of interest; and a very fine lock could lock only the cell of interest. The more granular a lock is, the more concurrent memory access can be, but highly granular locks are more difficult to manage because they require a larger key-value database to manage portions of memory.
- Priority inversion: Is when a lower priority process (read: transaction) prevents the execution of a higher priority process.
- Convoying: A lock convoy occurs when threads of equal priority compete for access to a shared resource. Each time a thread relinquishes access to the resource and pauses or stops the process, there is some overhead incurred.
- Deadlocks: A phenomenon where two or more processes cannot advance because each one requires resources held by the other.
- Slots: A slot is Solana’s term for block time, currently around 400ms. Nodes are allotted four consecutive slots every time they are leader.
- Epoch: An epoch in Solana is a distinct block of 432,000 consecutive slots. Not any 432,000 slots, but rather distinct blocks like days of the week.
- Serialization: Is the process of converting data (data structures and objects) to a string of bits that can be stored, transmitted, and reconstructed according to the format.
- Deserialization: Is the process of reconstructing serialized data from the string of bits to the original data structures or objects.
- Buffer: A buffer is a temporary storage element. It’s usually used when data cannot or should not be processed at the same rate at which it is being fed to the next block of a process.
- Packets: A packet is a fixed-size unit of data carried by a packet-switched network. Packets are relevant to Solana because each transaction is constrained to the maximum size of an IPv6 packet.
- Double-ended queue: Also called dequeue, is an abstract data structure that supports the addition of data to one end and removal from the other.
- Channel: High-performance I/O gadget.
- B-tree: Self-balancing data structure.
- Hashmap: Is an efficient associative array data structure.
- Race conditions: Occur when uncontrollable processes can lead to incorrect or inconsistent results. In the context of this paper, race conditions occur in OCC systems.
Appendix
A1: Distributed Databases
Distributed databases are a lot like blockchains, in fact, it’s not a stretch to say that they’re fundamentally the same thing. A distributed database is a collection of multiple, interconnected databases spread across different physical locations connected via a network. These databases appear as a single database to the user but function on multiple servers.
The topic of distributed databases is expansive so I’ll (briefly) cover only the areas relevant to this report: data distribution methods and database transactions.
Data Distribution Methods
- Horizontal Partitioning: Each site stores a different (subset) of the rows of a table. For example, a customer table might be divided so that the first X entries are stored on one database and the others are stored elsewhere.
- Vertical Partitioning: Each site stores different columns of a table. For example, one site might store the customer names and addresses, while another site stores their purchase histories.
- Replication: Copies of the entire database (or subsets) are stored at multiple sites. This improves data availability and reliability but may introduce consistency challenges.
Transactions
Transactions in DBMSs are defined as a single unit of operations that perform a logical action, usually accessing and/or modifying the database. For most databases, especially those keeping track of financial records, transactions are required to have ACID properties i.e., the transactions are:
- Atomic: all or nothing, if one operation fails, the entire transaction reverts
- Consistent: transactions modify the database in predictable and repeatable ways
- Isolated: when multiple transactions are executed concurrently, they execute without affecting each other, as if they were executed sequentially, and
- Durable: changes made by completed transactions are permanent even in the event of system failure.
If it’s not already obvious, blockchains are just replicated databases with adversarial operators. So it’s not surprising that distributed database research forms the foundation for most blockchain designs today.

A2: Narwhal and Quorum Store TLDR
The value proposition of Narwhal (and by extension Quorum Store) is that “leader-based consensus” i.e. a consensus system where the leader for a slot is responsible for transmitting most of the information during that slot (a-la-Solana) is bottlenecked by the performance of the leader as opposed to the entire validator set. Narwhal (and Quorum Store) resolve this bottleneck by decoupling data dissemination and consensus down to the hardware level. The implementation of this idea spreads the work equally across all validators, as opposed to having the leader alone bear the brunt.
Figure A2.1: Bandwidth utilization in leader-based consensus and Quorum Store Source
There’s perhaps no better proof of Narwhal’s value than Solana itself. The Solana documentation currently recommends that validators use dedicated 1 Gbit/s lines as the minimum bandwidth setup and ideally a 10 Gbit line. Average sized validators report around 1.5Gbit/s peak traffic (during leader slots) Aptos node runners report using 25 Mbps by comparison. Of course, both chains don’t process nearly the same amount of traffic and there’s the question of the stakeweight of each validator but the big idea is that Quorum Store is more efficient from a leader’s point of view than “leader-based consensus.” Let’s run through how it works.
In Quorum Store, validators continuously steam batches of ordered transactions (similar to the blocks discussed above) to one another. The batches contain raw transaction data and metadata (batch identifiers.) Other validators receive these batches, sign the batches, and transmit the signatures to other validators just like they would a normal executed block in “leader-based consensus.” When a batch reaches the quorum of stake-weighted signatures, it essentially receives a proof-of-availability as all the validators that sign a batch promise to keep and provide the batch on request until it “expires.”
Figure A2.2 Illustration
Because of Quorum Store, the leader doesn’t have to propose transaction batches anymore. Instead, the leader simply selects a batch for which it has a Proof-of-Availability, sends out the batch metadata, executes the block, and sends out the execution results. Other validators can then map the metadata to the batch and replay the batch for verification. If they don’t have the batch, they can request it from other nodes and be sure they’ll receive it since 2f+1 nodes promised to store and provide the data. This reduces the messaging overhead of the leader. And because Quorum Store is run on a separate machine, it’s horizontally scalable by adding more boxes.
There is a lot of nuance that my TLDR has left out; you can find more details in the Aptos Blog Post and Narwhal Paper.
A3: Block-STM Algorithm
This section contains the Block-STM algorithm from the paper alongside explanatory comments to aid understanding.
Thread Logic
//this block checks if execution is complete, if it is, it ends the procedure, if not:
//it checks if there is a task, and based on the type of task, it performs an action
//if there are no tasks, it calls the scheduler to assign it a task.
1: procedure run()
2: task ← ⊥ //⊥ is pseudocode for null
3: while ¬Scheduler.done() do //¬ is pseudocode for not
4: if task ≠ ⊥ ∧ task.kind = EXECUTION_TASK then
5: task ← try_execute(task.version) ⊲ returns a validation task, or ⊥
6: if task ≠ ⊥ ∧ task.kind = VALIDATION_TASK then
7: task ← needs_reexecution(task.version) ⊲ returns a re-execution task, or ⊥
8: if task = ⊥ then
9: task ← Scheduler.next_task()
//this block attempts to execute a transaction version
//line 13 checks that the transaction did not read any estimates
//line 14 attempts to add a dependency and if it fails retries the transaction
//line 18 calls the MVMemory module that will be covered later,
//but the MVMemory.record function writes the read_set and write_set to the data structure
//and returns a bool that indicates if the trnasaction version wrote a new location
10: function try_execute(version) ⊲ returns a validation task, or ⊥
11: (txn_idx, incarnation_number) ← version //unpacks version into its components
12: vm_result ← VM.execute(txn_idx) ⊲ VM execution results not written to shared memory
13: if vm_result.status = READ_ERROR then
14: if ¬Scheduler.add_dependency(txn_idx, vm_result.blocking_txn_idx) then
15: return try_execute(version) ⊲ dependency resolved in the meantime, re-execute
16: return ⊥
17: else
18: wrote_new_location ← MVMemory.record(version, vm_result.read_set, vm_result.write_set)
19: return Scheduler.finish_execution(txn_idx, incarnation_number, wrote_new_location)
//this block checks if a transaction needs reexecution and returns a task for re-execution, or ⊥
//line 23 defines the conditions for a transaction version to be considered aborted
//the read set of the transaction must be invalid and the scheduler's attempt to abort must be true
20: function needs_reexecution(version)
21: (txn_idx, incarnation_number) ← version
22: read_set_valid ← MVMemory.validate_read_set(txn_idx)
23: aborted ← ¬read_set_valid ∧ Scheduler.try_validation_abort(txn_idx, incarnation_number)
24: if aborted then
25: MVMemory.convert_writes_to_estimates(txn_idx)
26: return Scheduler.finish_validation(txn_idx, aborted)
//defines atomic variables
Atomic Variables:
data ← Map, initially empty ⊲ (location, txn_idx)
last_written_locations ← Array(BLOCK.size(), {}) ⊲ txn_idx to a set of memory locations written during its last finished execution.
last_read_set ← Array(BLOCK.size(), {}) ⊲ txn_idx to a set of (location, version) pairs per reads in last finished execution.
//data is the MV data structure, it maps the (location, transaction_index) pair to
//an (incarnation number, value) pair or to an ESTIMATE marker
//the next two lines describe creating abstract data strctures that hold a mapping of
//transaction id to the last written memory locations and
//txn id to the memory locations that version of the transaction read
//A procedure is essentially a function that does not return any value
//this block iterates over every location-value pair in the write set
//and stores it in the multi-version data structure
27: procedure apply_write_set(txn_index, incarnation_number, write_set)
28: for every (location, value) ∈ write_set do
29: data[(location, txn_idx)] ← (incarnation_number, value) ⊲ store in the multi-version data structure
//Read-Copy-Updates the variable that holds the last write set of a transaction
30: function rcu_update_written_locations(txn_index, new_locations)
31: prev_locations ← last_written_locations[txn_idx] ⊲ loaded atomically (RCU read)
32: for every unwritten_location ∈ prev_locations \\ new_locations do
33: data.remove((unwritten_location, txn_idx)) ⊲ remove entries that were not overwritten
34: last_written_locations[txn_idx] ← new_locations ⊲ store newly written locations atomically (RCU update)
35: return new_locations \\ prev_locations ≠ {} ⊲ was there a write to a location not written the last time?
//unpacks the last written locations into previous locations
//determines the set that contains elements in new locations that are not in previous locations
//and for every location that this incarnation does not write to,
//remove the location from the write set
//this entire fucking block literally just finds old written locations that were not written in this new incarnation and removes them
//it also returns a bool to confirm that there was a write to a location that wasn't written to this time.
//the \\ symbol in line 35 is set difference. the line checks if the set difference is empty
//this block records a version to the multi version data structure
36: function record(version, read_set, write_set)
37: (txn_idx, incarnation_number) ← version
38: apply_write_set(txn_idx, incarnation_number, write_set) //procedure call
39: new_locations ← {location | (location, ★) ∈ write_set} ⊲ extract locations that were newly written
40: wrote_new_location ← rcu_update_written_locations(txn_idx, new_locations) //check if new locations were written
41: last_read_set[txn_idx] ← read_set ⊲ store the read-set atomically (RCU update)
42: return wrote_new_location
//calls the apply_write_set procedure which stores the write-set data in the multi-version data structure
//extracts the locations that were not written by the previous incarnation
//unpacks the rcu_update_written_location function which returns a bool but also updates the set of written transactions
//stores the read_set
//returns the value of wrote_new_location bool
43: procedure convert_writes_to_estimates(txn_idx)
44: prev_locations ← last_written_locations[txn_idx] ⊲ loaded atomically (RCU read)
45: for every location ∈ prev_location do
46: data[(location, txn_idx)] ← ESTIMATE ⊲ entry is guaranteed to exist
//logic for reading from the multi-version data structure
47: function read(location, txn_idx)
48: 𝑆 ← {((location, idx), entry) ∈ data | idx < txn_idx} // | means such that
49: if 𝑆 = {} then
50: return (status ← NOT_FOUND)
51: ((location, idx), entry) ← arg max𝑖𝑑𝑥 𝑆
52: if entry = ESTIMATE then
53: return (status ← READ_ERROR, blocking_txn_idx ← idx)
54: return (status ← OK, version ← (idx, entry.incarnation_number), value ← entry.value)
//takes location and txn_idx as inputs
//creates a data structure S of the form ((location, transaction id), entry)
//and fills it with all the data from the multi-version data structure
//while the transaction ids of the elements in data are less than the specified txn id
//(remember 1<2<3<...) so if txn_id is 3, it fills S with all the data for 1 and 2
//if the set is empty, set status to not found i.e there are no writes to that location
//by earlier transactions
//select the entry from S with the highest transaction index (the most recent transaction since 2>1)
//find the write of the most recent transaction to that location.
//if the entry is an estimate return status as read error
//and set the value of the transaction blocking the transaction supplied in inout as idx
//else return status as ok and set version to a tuple
//takes a snapshot of the multiversion data structure
55: function snapshot()
56: ret ← {}
57: for every location | ((location, ★), ★) ∈ data do //★ is a placeholder
58: result ← read(location, BLOCK.size())
59: if result.status = OK then
60: ret ← ret ∪ {location, result.value} //pseudo for set union
61: return ret
//for every location such that contains a map of estimate or incarnation-value pair to
//the location and transaction id pair, create an array equal in size to the block size
//and move it to result
//if result.status = OK then **add the location and result.value to the snapshot.**
62: function validate_read_set(txn_idx)
63: prior_reads ← last_read_set[txn_idx] ⊲ last recorded read_set, loaded atomically via RCU
64: for every (location, version) ∈ prior_reads do ⊲ version is ⊥ when prior read returned NOT_FOUND
65: cur_read ← read(location, txn_idx)
66: if cur_read.status = READ_ERROR then
67: return false ⊲ previously read entry from data, now ESTIMATE
68: if cur_read.status = NOT_FOUND ∧ version ≠ ⊥ then
69: return false ⊲ previously read entry from data, now NOT_FOUND
70: if cur_read.status = OK ∧ cur_read.version ≠ version then
71: return false ⊲ read some entry, but not the same as before
72: return true
//line 64 and 65 can be read as for every location, version pair in the set of prior reads
//set the current read to the most recent value set of values written by txn
Algorithm 3: The VM module
73: function execute(txn_id)
74: read_set ← {} ⊲ (location, version) pairs
75: write_set ← {} ⊲ (location, value) pairs
76: run transaction BLOCK[txn_idx] ⊲ function call--run transaction, intercept reads and writes
77: ....
78: when execution requires writing data to a location:
79: if (location, prev_value) ∈ write_set then
80: write_set ← write_set \\ {(location, prev_value)} ⊲ store the latest value per location
81: write_set ← write_set ∪ {(location, value)} ⊲ VM does not write to MVMemory or Storage
// when the execution of a transaction has never written to a location
//line 81 adds a location value pair to the write set.
82: ....
83: when execution requires reading from a location:
84: if (location, value) ∈ write_set then
85: VM reads value ⊲ value written by this txn
86: else
87: result ← MVMemory.read(location, txn_idx)
88: if result.status = NOT_FOUND then
89: read_set ← read_set ∪ {(location, ⊥)} ⊲ record version ⊥ when reading from storage
90: VM reads from Storage
91: else if result.status = OK then
92: read_set ← read_set ∪ {(location, result.version)}
93: VM reads result.value
94: else
95: return result ⊲ return (READ_ERROR, blocking_txn_id) from the VM.execute
//for line 87, recall that the "read" fuction
//checks for the most recent write and determines if it's empty, estimate , or OK
96: ....
97: return (read_set, write_set)
Algorithm 4: The Scheduler module, variables, utility APIs and next task logic
Atomic variables:
execution_idx ← 0, validation_idx ← 0, decrease_cnt ← 0, num_active_tasks ← 0, done_marker ← false
⊲ Respectively:
An index that tracks the next transaction to try and execute.
A similar index for tracking validation.
Number of times validation_idx or execution_idx was decreased.
Number of ongoing validation and execution tasks.
Marker for completion.
txn_dependency ← Array(BLOCK.size(), mutex({})) ⊲ txn_idx to a mutex-protected set of dependent transaction indices
txn_status ← Array(BLOCK.size(), mutex((0, READY_TO_EXECUTE))) ⊲ txn_idx to a mutex-protected pair (incarnation_number, status),
where status ∈ {READY_TO_EXECUTE, EXECUTING, EXECUTED, ABORTING}.
98: procedure decrease_execution_idx(target_idx)
99: execution_idx ← min(execution_idx, target_idx) ⊲ atomic
100: decrease_cnt.increment()
101: function done()
102: return done_marker
103: procedure decrease_validation_idx(target_idx)
104: validation_idx ← min(validation_idx, target_idx) ⊲ atomic
105: decrease_cnt.increment()
106: procedure check_done()
107: observed_cnt ← decrease_cnt
108: if min(execution_idx, validation_idx) ≥ BLOCK.size() ∧ num_active_tasks = 0 ∧ observed_cnt = decrease_cnt then
109: done_marker ← true
//line 108 can be read as:
//if the next task is for a transaction not in this block
//and the number of active tasks is 0
//and the observed count is equal to the number of times counters were decreased
//then execution has finished
110: function try_incarnate(txn_idx)
111: if txn_idx < BLOCK.size() then
112: with txn_status[txn_idx].lock()
113: if txn_status[txn_idx].status = READY_TO_EXECUTE then
114: txn_status[txn_idx].status ← EXECUTING
115: return (txn_idx, txn_status[txn_idx].incarnation_number)
116: num_active_tasks.decrement()
117: return ⊥
//no actual execution of the transaction, just sets up the environemnt to call
//execute from line 73
//determines what transaction to execute and calls try incarnate with the transaction id
118: function next_version_to_execute()
119: if execution_idx ≥ BLOCK.size() then
120: check_done()
121: return ⊥
122: num_active_tasks.increment()
123: idx_to_execute ← execution_idx.fetch_and_increment()
124: return try_incarnate(idx_to_execute)
//same as above for validation tasks
125: function next_version_to_validate()
126: if validation_idx ≥ BLOCK.size() then
127: check_done()
128: return ⊥
129: num_active_tasks.increment()
130: idx_to_validate ← validation_idx.fetch_and_increment()
131: if idx_to_validate < BLOCK.size() then
132: (incarnation_number, status) ← txn_status[idx_to_validate].lock()
133: if status = EXECUTED then //ensures the transaction has been executed
134: return (idx_to_validate, incarnation_number)
135: num_active_tasks.decrement()
136: return ⊥
//selects between execution and validation tasks
137: function next_task()
138: if validation_idx < execution_idx then
139: version_to_validate ← next_version_to_validate()
140: if version_to_validate ≠ ⊥ then
141: return (version ← version_to_validate, kind ← VALIDATION_TASK)
142: else
143: version_to_execute ← next_version_to_execute()
144: if version_to_execute ≠ ⊥ then
145: return (version ← version_to_execute, kind ← EXECUTION_TASK)
146: return ⊥
Algorithm 5 The Scheduler module, dependencies and finish logic
//determines if a transaction is being blocked by the transaction in the second argument
147: function add_dependency(txn_idx, blocking_txn_idx)
148: with txn_dependency[blocking_txn_idx].lock()
149: if txn_status[blocking_txn_idx].lock().status = EXECUTED then ⊲ thread holds 2 locks
150: return false ⊲ dependency resolved before locking in Line 148
151: txn_status[txn_idx].lock().status() ← ABORTING ⊲ previous status must be EXECUTING
152: txn_dependency[blocking_txn_idx].insert(txn_idx)
153: num_active_tasks.decrement() ⊲ execution task aborted due to a dependency
154: return true
155: procedure set_ready_status(txn_idx)
156: with txn_status[txn_idx].lock()
157: (incarnation_number, status) ← txn_status[txn_idx] ⊲ status must be ABORTING
158: txn_status[txn_idx] ← (incarnation_number + 1, READY_TO_EXECUTE)
159: procedure resume_dependencies(dependent_txn_indices)
160: for each dep_txn_idx ∈ dependent_txn_indices do
161: set_ready_status(dep_txn_idx)
162: min_dependency_idx ← min(dependent_txn_indices) ⊲ minimum is ⊥ if no elements
163: if min_dependency_idx ≠ ⊥ then
164: decrease_execution_idx(min_dependency_idx) ⊲ ensure dependent indices get re-executed
165: procedure finish_execution(txn_idx, incarnation_number, wrote_new_path)
166: txn_status[txn_idx].lock().status ← EXECUTED ⊲ status must have been EXECUTING
167: deps ← txn_dependency[txn_idx].lock().swap({}) ⊲ swap out the set of dependent transaction indices
168: resume_dependencies(deps)
169: if validation_idx > txn_idx then ⊲ otherwise index already small enough
170: if wrote_new_path then
171: decrease_validation_idx(txn_idx) ⊲ schedule validation for txn_idx and higher txns
172: else
173: return (version ← (txn_idx, incarnation_number), kind ← VALIDATION_TASK)
174: num_active_tasks.decrement()
175: return ⊥ ⊲ no task returned to the caller
176: function try_validation_abort(txn_idx, incarnation_number)
177: with txn_status[txn_idx].lock()
178: if txn_status[txn_idx] = (incarnation_number, EXECUTED) then
179: txn_status[txn_idx].status ← ABORTING ⊲ thread changes status, starts aborting
180: return true
181: return false
182: procedure finish_validation(txn_idx, aborted)
183: if aborted then
184: set_ready_status(txn_idx)
185: decrease_validation_idx(txn_idx + 1) ⊲ schedule validation for higher transactions
186: if execution_idx > txn_idx then ⊲ otherwise index already small enough
187: new_version ← try_incarnate(txn_idx)
188: if new_version ≠ ⊥ then
189: return (new_version, kind ← EXECUTION_TASK) ⊲ return re-execution task to the caller
190: num_active_tasks.decrement() ⊲ done with validation task
191: return ⊥ ⊲ no task returned to the caller
*1 Executing transactions in batches reduces messaging and context switching but comes at the cost of requiring extra scheduling.
*2 The topic of OCC vs. PCC is considered moot in academia—the general sentiment is that OCC is suited for low contention applications and PCC for high contention applications. As such there is very little work ongoing in this regard—one of the most recent papers to discuss the subject was written in 1982. The following graph is adapted from the paper and it helps to reinform the established sentiment.
The 2016 study, Revisiting optimistic and pessimistic concurrency control by Goetz Graefe of Hewlett-Packard Labs, comes to the same conclusion as Menasce and Nakanishi; to quote the author,
“...we have concluded that optimistic concurrency control permits more concurrency than pessimistic concurrency control only if it fails to detect some actual conflicts or if a particular implementation of locking detects false conflicts.”
There are numerous studies that come to the same conclusion but we’ve left them out for brevity.
*3 A perfectly fair evaluation of Block-STM and Sealevel would require isolation, i.e., removing all other processes like Solana’s PoH and ledger commits, using the same VM for both TPUs and a host of laborious engineering tasks that are simply not worth the effort, especially when preliminary testing suggests that the TPUs follow the established trends.
*4 An optimization in the implementation of Block-STM allows aborted transactions to be restarted from the point of conflict. Instead of restarting execution from scratch, the MoveVM supports validating the readset of the transaction’s previous incarnation and if valid, continuing execution from the point of conflict.
*5 A second optimization is when the dependency is resolved before the execution task is created i.e when line 14 of the algorithm returns false. In the implementation, the VM continues execution from where it paused rather than restarting the execution.



