Designing Cross-L2 Interoperability Standards: The Impact of Shared Resources
Exploring cross-L2 interoperability standards and the role of shared resources in enhancing blockchain scalability, security, and seamless communication.

The rapid expansion and fragmentation of the L2 ecosystem
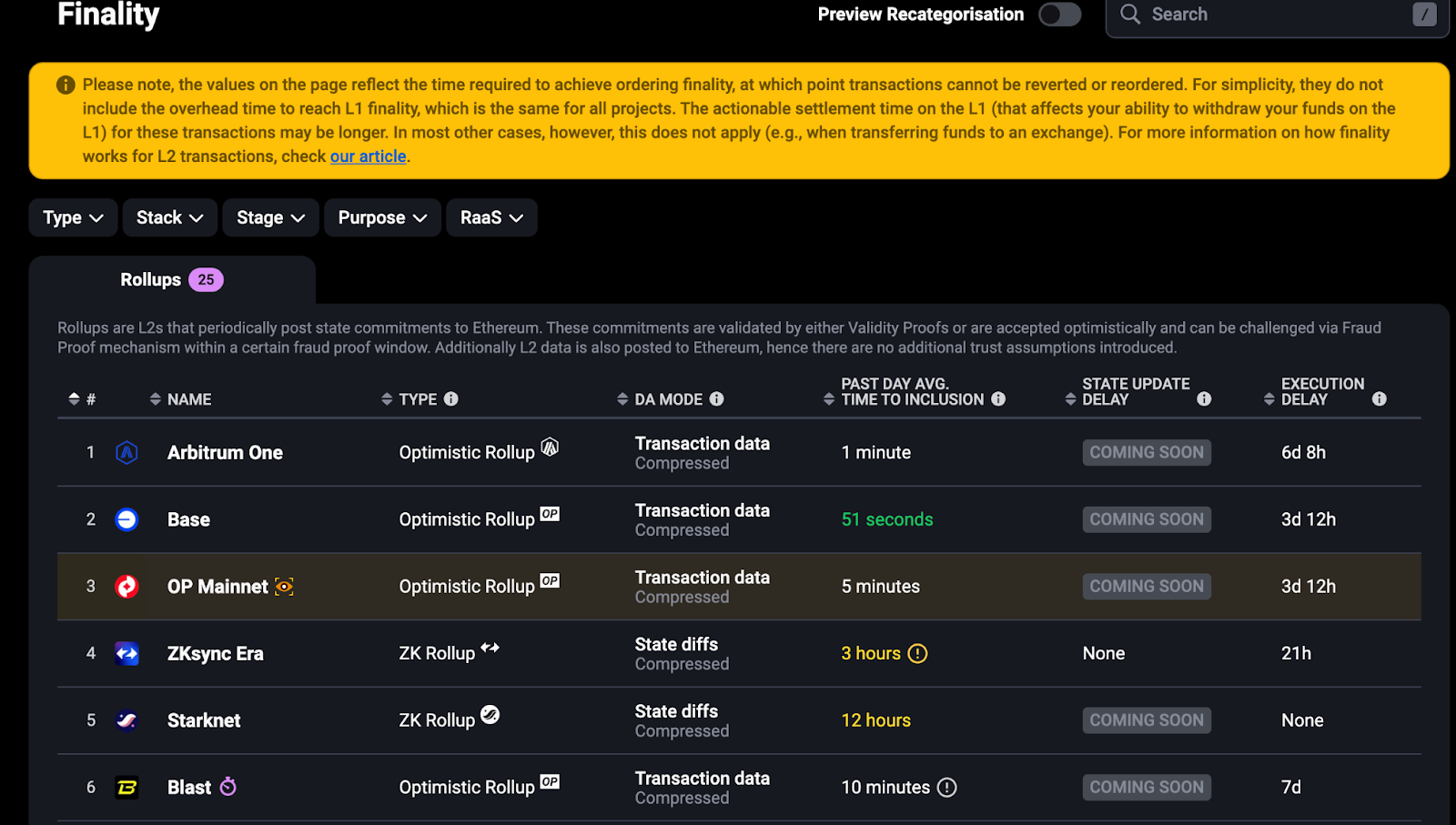
As observed on L2Beat, Layer 2 (L2) solutions are growing rapidly. Currently, 126 L2s are already live or about to launch, compared to just 90 a month ago. The narrative around L2s is validated, as more users have shifted their activities to L2s, escaping the high transaction fees on Ethereum L1, which can easily exceed double digits in USD. This shift has led to a flourishing L2 ecosystem, and everything seems to be progressing in the right direction..

However, this "honeymoon period" did not last long. As various L2s began competing for TVL, users’ assets became increasingly fragmented across different L2s, exposing numerous challenges in user experience (UX), particularly in cross-L2 interactions. Two core challenges—asset fragmentation and state fragmentation—have emerged as significant barriers preventing users from fully leveraging the potential of multi-layer networks. These issues have also been a major source of FUD against Ethereum over the past year.
Asset fragmentation is relatively easy to understand. Every L2 aims to attract as much liquidity as possible. Before L2s, all assets were concentrated on Ethereum L1. With the rise of L2s, more assets are being deposited via Canonical Bridges or transferred via third-party liquidity bridges. However, when users want to withdraw their assets from L2s back to L1 using Canonical Bridges, the user experience is far from seamless. For instance, withdrawing from Optimistic Rollups involves waiting through a challenge period, while ZK Rollups may require delayed submissions. This creates an "easy-in, hard-out" dilemma for users.
State fragmentation is a more subtle but far-reaching issue. Each L2 network maintains an independent state, meaning their blockchain data (e.g., account balances, smart contract states) cannot naturally sync or interact with one another. This lack of interoperability greatly limits cross-L2 smart contract interactions. For example, imagine a user completes a collateralization operation on Arbitrum and then wants to participate in a protocol on Mantle. These two L2s cannot directly communicate their states. Instead, the user would need to withdraw assets from Arbitrum to Ethereum L1 and then bridge them to Mantle. This process is not only costly but also involves multiple steps. More critically, it lacks real-time efficiency—users must wait for the bridging transactions to complete, which can take several minutes or even hours. So, how can we resolve this poor UX and enable the entire L2 ecosystem to communicate seamlessly, just like smart contracts on Ethereum L1?
Exploring resource sharing across L2s
From the above designs, it is evident that resource sharing is becoming increasingly vital in the multi-chain and cross-chain blockchain ecosystem. We firmly believe that any level of interoperability fundamentally relies on shared resources. These resources, jointly maintained by interconnected chains, act as an invisible bridge, serving as the key to breaking down the isolation between chains. For example, as with current bridges, users need to use the shared liquidity in the bridge to complete the swap of chain assets, which is the bridge's shared resource. This sharing mechanism not only enhances collaboration within the ecosystem but also lays a solid foundation for the growth of cross-L2s systems.
The evolution of modular design: From separation to collaboration

Modular blockchains have emerged as a significant trend in blockchain design in recent years. The core idea is to separate settlement, data availability, and execution functions, allowing different modules to specialize in specific tasks. By breaking down and optimizing the functionalities of monolithic blockchains, modular design aims to create an optimized system through flexible combinations.
The evolution of traditional internet technologies provides many similar examples. For instance, early computer networks concentrated all computing, storage, and networking functions on a single host (e.g., mainframes). Over time, this evolved into distributed systems, where these functions were split across independent nodes. Later, the rise of cloud computing platforms re-integrated these distributed systems into unified service frameworks by sharing resources such as storage, computational power, and network bandwidth. This modular and collaborative evolution significantly improved system efficiency and flexibility.
Similarly, the ultimate goal of modular blockchains is to achieve an optimal solution through more efficient module integration. We are now at a historic juncture in this transition. As modular designs continue to mature, the blockchain ecosystem is poised to achieve greater scalability and collaborative potential.
Shared resources: The invisible bridges for cross-L2 collaboration
For all L2s, the current fragmentation issue can be seen as the growing pains caused by modular separation. All attempts to address this issue inherently rely on leveraging shared resources. This is precisely why shared resources remain the invisible bridge enabling inter-chain collaboration, serving as a critical link to achieve interoperability in a multi-chain ecosystem.
Now let's adopt a top-down system analysis approach to illustrate the various ways shared resources are utilized in the Ethereum ecosystem and how they impact inter-chain interoperability (interop). To make this more concrete, let us consider a specific transaction scenario: a user wants to burn 10 USDT on Arbitrum and then mint 10 USDT on Mantle.
Shared settlement

As we know, all Ethereum L1 smart contracts inherently share Ethereum's global state, achieving the highest level of interoperability within monolithic chain ecosystems. However, due to gas and performance limitations, we still rely on L2s to handle the execution overflow from Ethereum L1. To maintain their independence, L2s only share the settlement layer through isolated bridge contracts, which significantly reduces the level of interop between L2s.
Chain Abstraction has gained traction as one of the most promising solutions to the fragmentation problem. We’ve seen examples like Mantle and Nomial, attempt to eliminate liquidity fragmentation by sharing on-chain liquidity. Similarly, Across integrates off-chain liquidity to provide a smooth cross-chain transfer UX, while Particle proposes a unified settlement layer to enable seamless interop. These designs extend the shared settlement layer to provide common security guarantees and economic benefits to all connected L2s. However, these solutions do not fundamentally resolve the asynchronous nature of the process—whether based on liquidity aggregation or bridging mechanisms, interop between chains remains an asynchronous operation.
But what if the isolated bridge contracts are replaced with generalized and shared resources, enabling all L2s to share liquidity, which will bring us a shared bridge. For example, when a user executes a burn transaction on Arbitrum, the transaction, once submitted to Ethereum L1, does not need to wait for a finalized state. Mantle can immediately retrieve the Merkle proof of the state transition and execute the mint operation. While this process is still asynchronous, it significantly reduces the time required to wait for transaction finalization, greatly improving the efficiency of cross-L2 operations and the overall user experience.
Shared sequencing

Would the situation change if we shared more resources? Suppose we generalize transactions submitted by L2s and perform cross-L2 transaction ordering within a unified component. This approach could enable a state where multi-chain transactions, bundled into a tx bundle, are guaranteed to be included in the next block. However, a critical issue arises: atomic inclusion does not guarantee the successful execution of transactions.
This means that even if the burn transaction on Arbitrum fails, the mint transaction on Mantle could still proceed. In such a scenario, the system risks encountering state inconsistency, which is an extremely dangerous outcome. Without ensuring the atomicity of cross-chain transactions, this mechanism could severely compromise the integrity and credibility of the blockchain system.
As a result, this approach does not fundamentally improve the level of interop. We still need to wait for the transaction on Arbitrum to finalize before executing the corresponding transaction on Mantle. This dependency on the synchronization of transaction results is an unavoidable requirement in current cross-chain interoperability designs, especially when the integrity and consistency of state transitions must be preserved.
Shared data availability

What would happen if we expanded the scope of shared resources further and introduced Shared Data Availability (Shared DA)? Shared DA provides a unified infrastructure for data storage and verification across multiple L2s, enabling all participating chains to share the same data availability layer. This design offers significant advantages in improving data reliability and reducing costs, especially in modular blockchain architectures, where Shared DA can effectively reduce the resource overhead required for each chain to independently maintain data availability.
However, Shared DA itself does not have a direct impact on improving interoperability. Its primary role is to provide more efficient infrastructure support for other shared resources, such as a shared settlement layer or shared sequencing. Through collaboration with these other shared resources, Shared DA can indirectly influence the level of interoperability. For example, when multiple L2s share the same DA layer, the state transfer of cross-chain transactions (e.g., the generation and verification of Merkle proofs) can become faster and more consistent, significantly reducing the latency of cross-chain transactions. However, these improvements do not fundamentally change the asynchronous nature of interoperability.
Additional interoperability considerations
In today's blockchain ecosystem, achieving atomic execution across multiple L2 networks remains one of the most pressing challenges in interoperability. Atomic execution requires that all transactions in cross-chain operations either all succeed or completely revert- this is a key functionality for ensuring trust and consistency in a decentralized ecosystem. However, since existing smart contracts cannot directly trigger cross-chain operations, achieving this level of coordination is no easy task.
Multi-chain block building
The community is exploring various solutions for this. One promising direction is collaborative construction, such as the Optimism Superchain framework. In this model, each L2 sequencer in the Superchain operates autonomously but shares critical transaction logs (e.g., cross-chain messages) with other chains in the "core dependency set" via real-time gossip. Also there is a shared timestamp invariant that ensures that cross-chain transactions can be propagated intra-block—meaning a transaction initiated on Chain A can trigger an action on Chain B within the same L2 block height, even if Chain A’s execution hasn’t been finalized. This design eliminates the need for destination chains to wait for source chain finalization, enabling near-instant cross-chain interactions while preserving atomicity.
Another innovative solution improves flexibility by separating the roles of sequencer and builder. For example, independent sequencers can retain control over block production but auction the "block top" space to specialized super-builders (like Javelin by Nodekit). These super-builders focus on assembling cross-chain transaction packages and injecting them into purchased blocks. If users want to swap tokens between Arbitrum and Mantle, they only need to submit transaction intentions to the super-builder. The super-builder then purchases block space on both chains, pre-simulates transactions to ensure dependencies are met, and executes operations atomically. This design not only reduces dependency on a single centralized entity but also allows super-builders to operate in heterogeneous L2 ecosystems without requiring complete control over the sequencing process.
Multi-chain STF combination
Beyond this, we know that state transition function (STF) validity verification for single Rollups is relatively mature - whether ensuring state correctness through zero-knowledge proofs (ZK Proofs) or challenging potential errors through fraud proofs, each Rollup ecosystem has established its own trust mechanism. However, when users need to execute transactions simultaneously on multiple heterogeneous Rollups (for example, depositing assets on Mantle and triggering lending on ZKSync), coupling different Rollups' STF logic to achieve cross-chain atomicity remains an insufficiently solved challenge. Settlement time differences between the two can cause cross-chain operations to deadlock.
For interactions purely between ZK rollups, due to their near-instant finality, they can achieve STFs-level combination through the additional introduction of something like a Proof Aggregation Layer. In this additional layer, classification and subsequent verification can be performed based on the proof systems used by different Rollups.
For interactions between Optimistic Rollups, since they all need to pass through a challenge period to be considered finalized, and different L2s may have different challenge periods - for example, Arbitrum and Optimism each use their own challenge mechanisms - when they settle on Ethereum L1, their STFs are verified separately and are constrained by the chain with the longer challenge period. If we want to optimize this UX aspect, we may need to introduce additional trust assumptions (such as restaking) to take on risks from the challenge period, and then hedge these risks through methods like rollbacks or settlement fee income.
Finally, the most complex case is STFs combination between ZK and Optimistic rollups, which will also be constrained by the slower-settling chain. Additionally, due to differences in proof systems, STFs need to be abstracted, introducing components that can accommodate both types of state verification, and obviously Ethereum itself is the best option for this.
Transaction order between multiple chains finalized time
Another UX concern in cross-L2 is the timing guarantee of transaction ordering between multiple chains. A common approach is to have multiple Rollups share a Sequencer, which performs "global bundling" of cross-L2 transactions within the same time window. The Shared Sequencer can make each chain aware of cross-chain transaction ordering at the execution level, however, to achieve secure final confirmation still requires returning to Ethereum L1's data availability and finality (approximately 15 minutes), as multiple L2s still need to rely on L1 for security endorsement. Therefore, even with the introduction of a Shared Sequencer, progress will still be hindered by the settlement speed of the "slowest chain".
To reduce trust in single or few Sequencer, security and arbitration capabilities can be enhanced through introducing bonding. To further accelerate the "soft confirmation" of cross-L2 transactions, a Fast Finality Committee can be set up within the protocol. These committee members provide signature endorsements for transactions within a short time, allowing transactions to receive "soft confirmation" within seconds to minutes.
Vitalik’s perspective on cross-L2 standards

In response to the current issues facing the ecosystem, the community has proposed numerous EIPs. Fortunately, Vitalik has shared his thoughts on this matter, selecting a few of the most critical EIPs and suggesting that they be combined to address these challenges more effectively.
Phase 1 - combining existing EIPs to develop interoperability standards
Development of cross-L2 communication standards
The starting point for all transactions is how do we identify and differentiate our wallets? As we know, all EVM networks share the same address format, which often leads to asset losses when users mistakenly select the wrong chain.
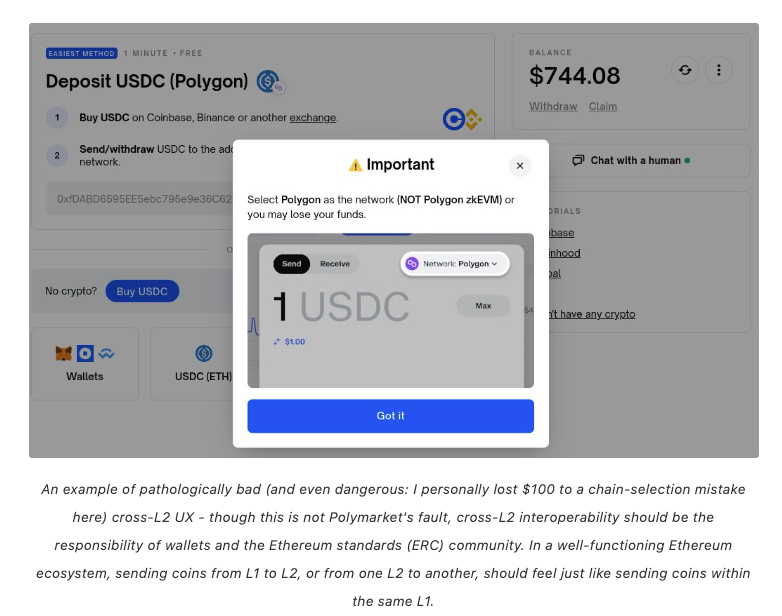
EIP-3770 addresses this issue by proposing a standardized format for adding chain identifiers to blockchain addresses. For example, by adding a prefix `chainID:address` to an address, it becomes clear which chain the address belongs to. For instance, `ethereum:0x123...456` and `mantle:0x123...456` represent the same private key on two different networks. This is critical for a multi-chain ecosystem, as we know that Polkadot and Cosmos also use the same private key, but they generate different addresses in their own different networks, where Polkadot uses a network prefix as part of its address encoding, generating unique addresses for different networks, while Cosmos employs a method more similar to EIP-3770, adding a network prefix directly at the start of the address, such as `cosmos1...`. This approach improves readability and allows for intuitive chain identification.
Next is ERC-7683, a significant proposal for cross-chain interactions within the Ethereum ecosystem. Its goal is to standardize the creation, propagation, and execution of cross-chain intents, improving the efficiency of multi-chain interactions, optimizing liquidity usage, and fostering ecosystem interoperability. In simple terms, ERC-7683 introduces a "dialogue" standard between chains. For example, it allows me to declare: "I will provide assets from the current L2 to anyone who provides sufficient funds for me on another L2."
The truly fascinating part of ERC-7683 lies not just in the dialogue standard itself but in its flexibility, which unlocks limitless future possibilities. We can draw several questions from this concept:
- Who provides the funds for me?
This could be on-chain liquidity providers participating in DeFi protocols, or off-chain market makers and venture capitalists (VCs) with large amounts of long-tail assets. This idea leads to the concept of SolverFi, which could even evolve into the narrative of Solver as a Service.
- How do we verify that the counterparty has provided the assets I need?
This question introduces the modular design narrative for generalized verification services. Such services are often complemented by messaging protocols to provide customizable verification for cross-chain dApps. Examples include LayerZero's Decentralized Verifier Network (DVNs) and Hyperlane's Interchain Security Modules (ISMs)

By further abstracting these verification services, we can design a verifier marketplace. In such an abstract market, we could achieve a higher degree of interoperability, such as combining multi-verification transactions and executing them atomically. This market-based design not only enhances verification flexibility but also provides essential infrastructure for future complex cross-chain interactions.
A new form of light client: applications of ERC-3668
Another significant EIP is ERC-3668 (also known as CCIP Read), proposed by ENS to extend Ethereum's functionality by allowing smart contracts to securely access off-chain data. This EIP introduces a mechanism for "relaying off-chain data," enabling smart contracts to fetch data from off-chain sources while providing an on-chain verification mechanism to ensure the data's trustworthiness.
Why is this considered a new form of light client?
We all knew traditional light clients have two core features: Accessing off-chain state and Verifying state trustworthiness. Light clients do not need to store the entire blockchain's data. Instead, they verify off-chain state using block headers or proofs.
ERC-3668 aligns closely with these functionalities. ERC-3668 allows off-chain services to submit data securely to on-chain contracts using Merkle proofs or zkSNARKs and contracts verify the authenticity of off-chain data using these proofs, mirroring the logic of light clients.
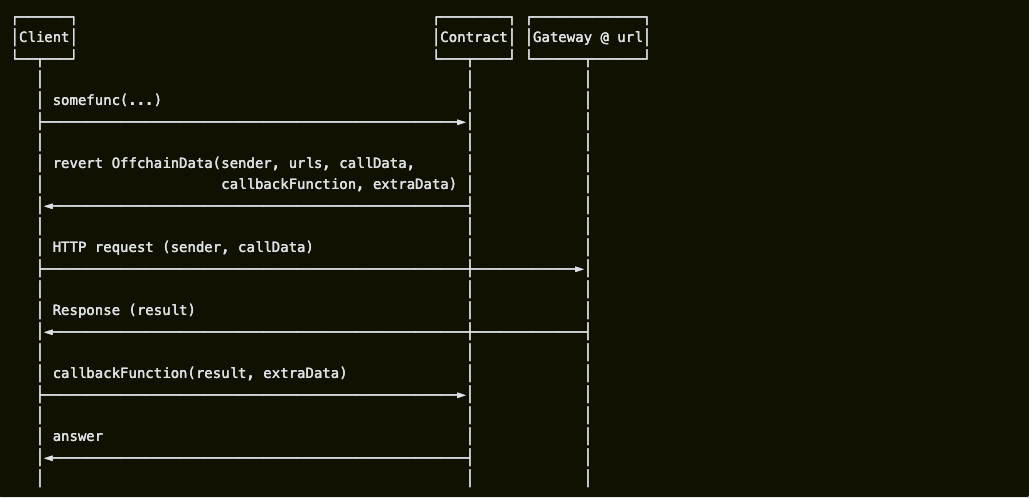
Thus, ERC-3668 can be viewed as an extension of light client functionality, enabling smart contracts to securely access off-chain states. Its architecture includes clients and on-chain verification contracts, as well as off-chain CCIP Read gateways. In practice, users initiate an off-chain data request via a client, and the contract returns an `OffchainLookup` error containing the gateway's URL, along with a callback function and parameters (`extraData`) for future use. The client then sends an HTTP request to the URL, combines the off-chain information with the `extraData`, and completes verification in the callback function.
Currently, Linea and ENS have implemented ERC-3668 to store ENS data on L2 while allowing users to seamlessly resolve this data on Ethereum L1. This approach significantly reduces costs while maintaining minimal trust assumptions for data retrieval. Linea’s implementation closely follows ERC-3668’s native design. For instance, if a user owns the domain `abc.linea.eth`, the address it is bound to is invisible to L1 dApps but can be retrieved via ERC-3668. The workflow is as follows:
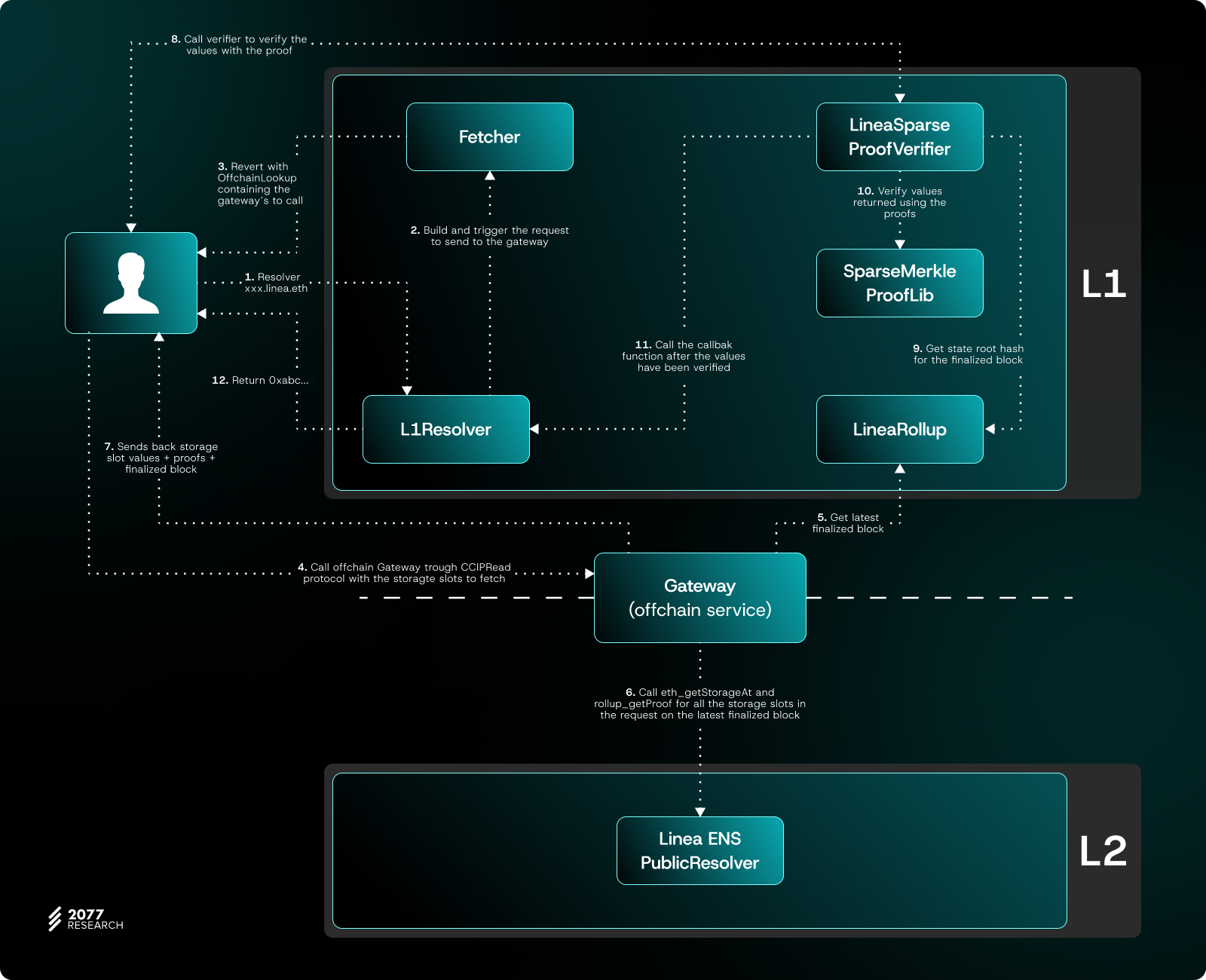
1. The user initiates an ENS domain resolution request on Ethereum L1. The `Resolver` contract on L1 calls the Fetcher contract to construct the query. The user then receives a revert with an `OffchainLookup` error, which includes the Gateway URL to query.
2. The client sends an HTTP request to the specified Gateway URL to fetch the ENS domain's storage slot on L2 and the latest finalized block number. The gateway retrieves this data from Linea’s L2 contract.
3. The gateway returns the storage slot information, the associated proofs, and the finalized block number. These proofs must be validated by a verification contract deployed on Ethereum L1 to ensure their authenticity. Only after successful validation are the returned data considered trustworthy.
This process allows users to seamlessly resolve ENS data on Ethereum L1 while offloading storage and retrieval costs to L2.
Recently we have seen a new RIP called RIP-7859 designed for L1 to L2 data retrieval. RIP-7859 is a proposal that aims to establish a standardized mechanism in L2 networks for storing “L1 origin data” and “L2 historical block hashes.” By pre-deploying two contracts (an L1 origin storage contract and an L2 history storage contract) on the L2, this proposal allows L2 contracts to directly retrieve and verify the hash information of the L1 blocks and historical L2 blocks they depend on, thereby reducing the complexity of cross-layer verification.
Regarding ERC-3668, RIP-7859 provides a way to store L1 block information locally on the L2, enhancing the verifiability of external data when a contract calls it. When a contract uses the ERC-3668 (CCIP Read) mechanism to fetch additional information off-chain, the “locally available L1 origin data” provided by RIP-7859 makes it more convenient and efficient to verify L1 transactions, storage, or state on the L2 side. In short, RIP-7859 and ERC-3668 are complementary in cross-layer (L1↔L2) data verification scenarios: the former “solidifies” key L1 information on the L2, while the latter provides a general-purpose workflow for off-chain data retrieval and custom validation, thereby enhancing the security and flexibility of cross-layer contract interactions.
Combining standards: building a complete cross-L2 solution
After understanding the core EIP designs mentioned earlier, we can try to combine them to create a complete cross-L2 solution.
Imagine this scenario: a user wants to transfer 1000 USDT from Arbitrum to Mantle and use it to buy ETH at a price of 3000 USDT. While this might sound simple, it actually involves complex multi-chain interactions and state synchronization. Let’s walk through how this process can be achieved step by step.
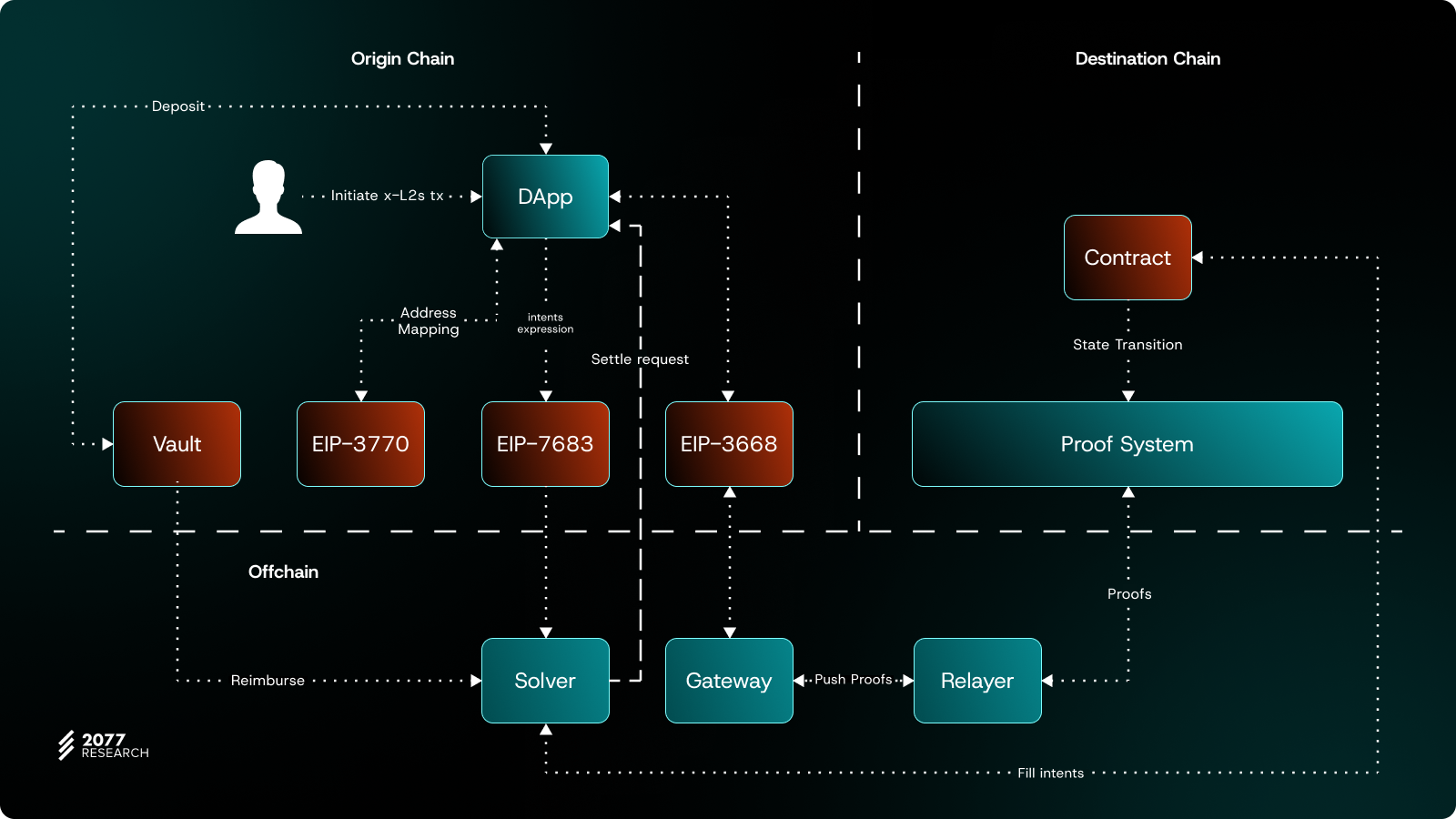
The user begins by submitting a transaction intent through a wallet or dApp that supports EIP-7683. This intent clearly specifies the user’s goals:
- Source chain (Arbitrum): Deposit 1000 USDT into a vault.
- Target chain (Mantle): Place a limit order to purchase ETH using 1000 USDT, with a price cap of 3000 USDT/ETH.
- Time constraint: The transaction must be completed within 15 minutes.
Once the intent is submitted, it is captured and processed by a Solver. The Solver’s role is to interpret the user’s request and execute the transaction on the target chain. Before proceeding, the Solver verifies the validity of the user’s specified target address and parses the transaction parameters for Mantle. Once these preliminary steps are completed, the Solver executes the user’s intent on Mantle, transferring the 1000 USDT to the target address and placing the limit order to purchase ETH. The Solver enables this entire cross-chain process to happen automatically, shielding the user from the underlying technical complexity.
After the transaction is completed on Mantle, the results need to be reported back to Arbitrum to close the loop. This is where ERC-3668 (CCIP Read) comes into play. The state transition on Mantle, along with the corresponding proof, is submitted back to Arbitrum through an off-chain CCIP Read gateway. Proofs, such as zkSNARKs, allow the smart contract on Arbitrum to verify that the transaction on Mantle was indeed successful. With this setup, the cross-chain interaction between Mantle and Arbitrum happens seamlessly, without requiring direct intervention from the user. It is achieved through a combination of off-chain gateways and on-chain verification mechanisms.
Finally, based on the verified data, the Solver completes its reimbursement process on Arbitrum. At this point, the user’s cross-chain asset transfer and limit order intent have been fully realized. From the user’s perspective, the process is seamless and efficient, while the underlying technical complexity is abstracted away. All the user needs to do is submit the intent and wait for the final result.
The success of this cross-chain design hinges on the thoughtful integration of multiple EIP technologies: EIP-7683 provides a standardized framework for cross-chain intents, enabling users to clearly define their needs; ERC-3668 facilitates secure synchronization of cross-chain states through off-chain data access and on-chain verification mechanisms. Meanwhile, the Solver acts as both an executor and a connector, simplifying the user experience while ensuring transaction efficiency.
Phase 2 - further optimization and future directions
The Phase 1 design can be summarized as a set of standardized frameworks. These designs are entirely independent of the underlying technical approaches of various L2s, ensuring minimal intrusion into existing systems while establishing a unified set of norms. However, while Phase 1 provides the fundamental capabilities for cross-chain interaction, there is still significant room for improvement in terms of user experience (UX). To achieve a better UX, we can introduce additional designs and functionalities.
Improving the cross-L2 sending functionality
In previous Cross-L2s communication standards, we discussed introducing a chain identifier into addresses to distinguish between chains. But how are these chain identifiers maintained? Currently, all chain identifiers are centrally managed via [GitHub](https://github.com/ethereum-lists/chains). To address this centralization and provide on-chain verifiability, ERC-7785 introduces a design for registering chain identifiers on-chain.
Using ENS, chain names can be mapped to chain identifiers, allowing for decentralized management and on-chain verification. For instance, Mantle can register `mantle.eth` and associate it with a hash composed of configuration data and the chain name, which serves as its chain identifier. This mapping makes `mantle.eth` directly link to the chain identifier, enabling any on-chain participant to retrieve and validate the chain identifier through ENS.
While EIP-3770 provides a way to specify chains in addresses, it falls short in terms of user experience (UX). Human-readable address formats, such as ENS names, can significantly enhance usability. To address this, ERC-7828 proposes an improvement to EIP-3770 by introducing the `account@chain` format to represent chain-specific addresses. For example, `user.eth@mantle.eth` indicates the address associated with the `user.eth` ENS name on the Mantle chain.
To resolve such addresses dynamically, a layered ENS resolution process is required:
1. First, resolve the `mantle.eth` domain to retrieve Mantle's chain identifier registered on-chain.
2. Then, using an off-chain data retrieval method like ERC-3668, fetch the address associated with `user.eth` on Mantle (e.g., `user.mantle.eth`).
This approach not only ensures clear differentiation of cross-chain addresses but also significantly improves readability and user experience.
Introducing keystore: enhancing the cross-L2 user experience
Smart wallets have long been a foundational component that Ethereum aims to introduce for mass adoption. They offer programmable account logic, native multi-signature support, and enhanced security features, significantly improving the user experience. However, in a complex multi-chain environment, these designs also introduce new challenges. For example, when a user updates their state (e.g., changes a session key) on one L2, this change cannot automatically propagate to other L2s. Users are forced to manually update their state on each chain, which is not only cumbersome but also introduces potential security risks. Worse still, if a key is compromised, users must revoke permissions on every chain manually—a process prone to errors and inefficiencies.
To address these challenges, the introduction of a Keystore component has emerged as a potential solution. This public component is designed as a unified platform for managing and synchronizing account states across L2s. With such a system, users can update their keys and account information in one hub location, and these changes are then automatically synchronized across all relevant blockchains and L2 networks.
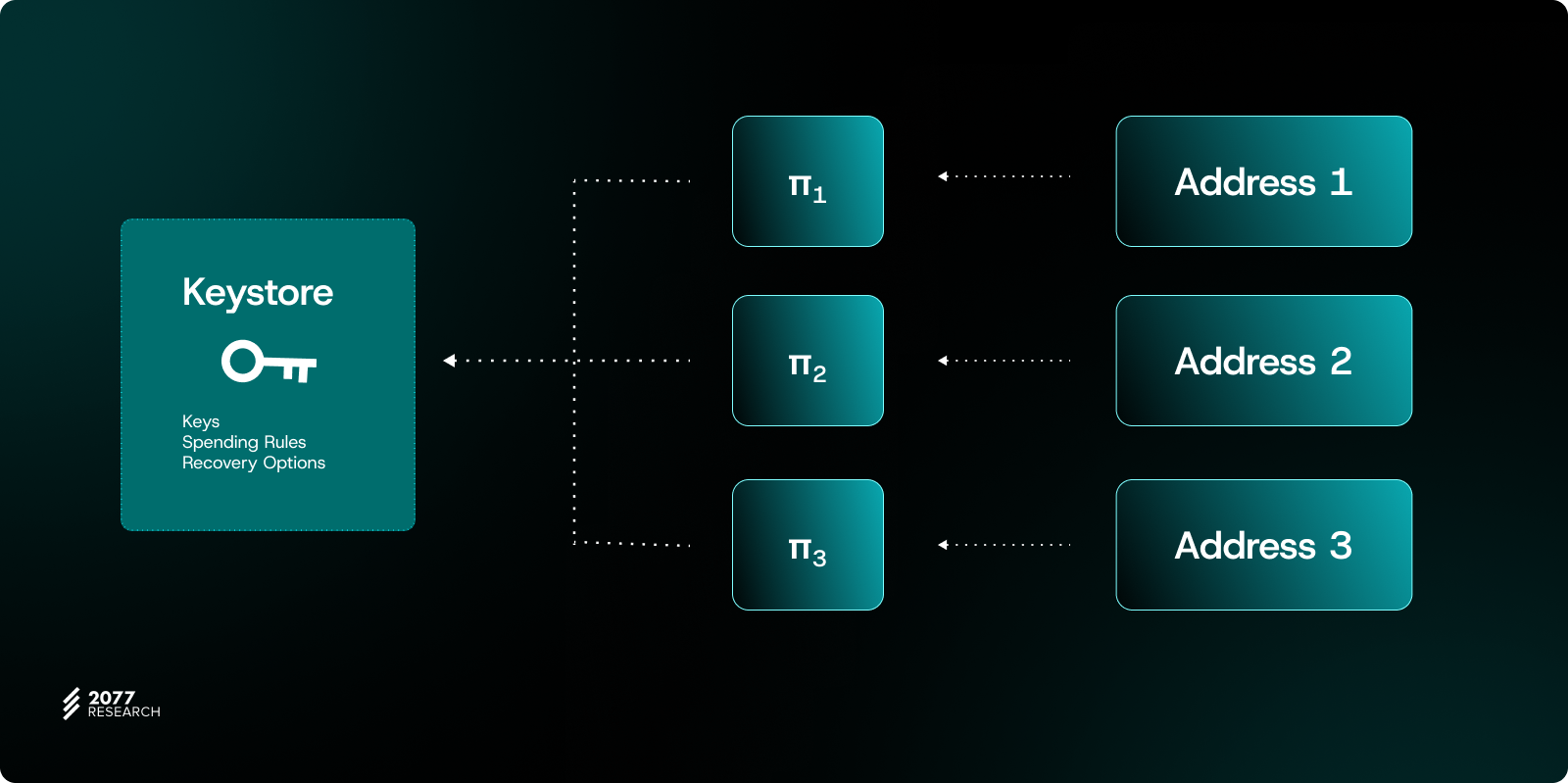
While we won’t delve deeply into the design of Keystore Rollup here, it can be briefly understood as a minimalistic Rollup focused solely on storing and updating user keys. Since this is a design for managing multi-chain keys, an Ethereum L1 contract must be maintained to store these keys, while all L2s can quickly query and update the information. However, this design faces challenges: updating keys directly on L1 is prohibitively expensive, whereas updating keys on individual L2s introduces additional trust assumptions on the L2 state synchronization mechanism. This is one of the main causes of poor UX in the multi-chain ecosystem.
To tackle these issues, the community has proposed several solutions. One such solution is RIP-7728, which introduces a new precompiled contract, L1SLOAD. This allows L2 smart contracts to directly read specific storage slots from L1 without manually generating and submitting Merkle proofs. But how does this work?
On L1, obtaining L2 state is relatively straightforward—one can read the pending or finalized L2 state root and provide a Merkle proof for inclusion. However, L2 typically lacks a concept of the L1 `StateRoot`. RIP-7728 assumes that L2s can reliably and consistently access the L1 state root. This is where the L1Blocks system contract introduced by OP Stack plays a role: it maintains the latest block information synchronized from L1 to L2, including block hashes and state roots. L1SLOAD combines the storage key with the state root to directly read data from L1’s state tree. This is why specifying the storage key is essential for L1SLOAD’s implementation.

That said, we must also consider the latency issue caused by L1 finality. Reading only finalized L1 block states can take around 15 minutes, resulting in a poor UX. If slot-level L1 state access can be achieved, UX would improve significantly. However, this would require L2s to implement robust mechanisms for handling potential L1 reorgs.
In addition to RIP-7728, Optimism’s [Remote Static Call](https://github.com/ethereum-optimism/ecosystem-contributions/issues/76) functionality also aims to address the same issue. This feature allows L2 smart contracts to directly query L1 data using the `eth_call` method. Like L1SLOAD, this also requires a precompiled contract, but no production-ready implementation has yet been introduced.
Don't trust, verify it
Currently, most users rely on centralized RPC providers (e.g., Infura, Alchemy) to access on-chain data. However, this approach poses two significant issues: first, it requires users to unconditionally trust these RPC providers, and second, it risks compromising user privacy. The future lies in deeply integrating light clients into wallets and browsers, enabling users to directly verify on-chain data without relying on third parties. In addition to ERC-3668, general-purpose light client designs like Helios can support broader application scenarios.
The working principles of light clients will not be elaborated here. Referencing Noah Citron's presentation, light clients can be simplified into two parts: CL (Consensus Layer) and EL (Execution Layer). When a user sends a query to the light client, it first retrieves block headers and uses the state root to obtain Merkle proofs for all states. At this point, the user only needs to request data and proofs from any untrusted provider to verify and obtain trustworthy data.
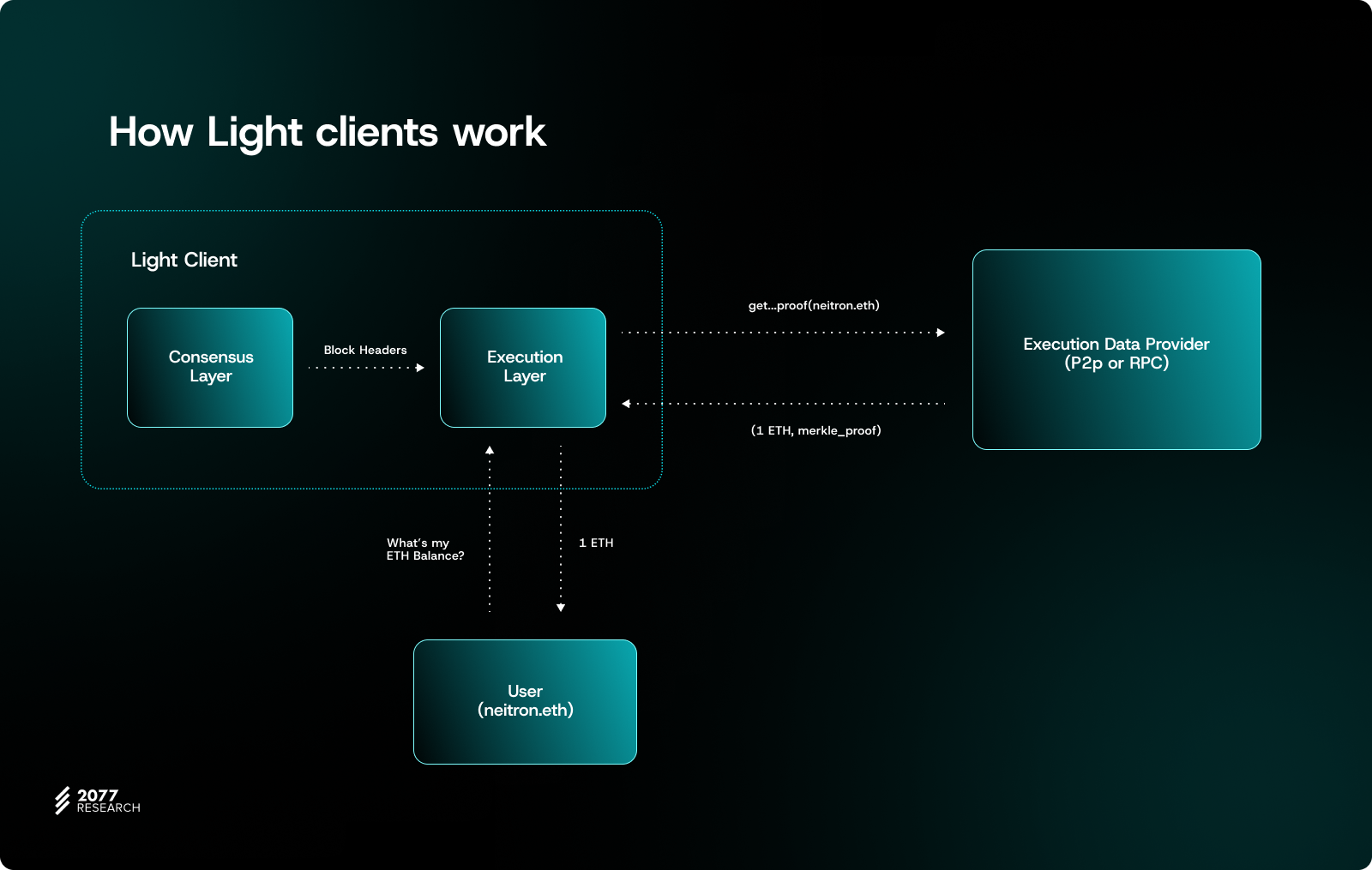
The main limitation of light clients lies in their insufficient support for L2s. Unlike L1, L2 lacks robust mechanisms to ensure the validity of block headers. L2 states are submitted to L1 by sequencers, but L1 validators cannot directly verify L2 block inputs and state transition functions (STF). Thus, L2 requires additional validation layers or mechanisms to ensure the correctness of its states.

To address this, Helios has proposed designs for cross-chain verification, specifically for the Optimism Stack (OP Stack), enabling interoperability at the superchain level. However, this design still relies on trusting sequencer signatures and lacks broader applicability. To tackle these limitations, Helios introduces two Gadgets: Irreversibility Gadget and Validity Gadget.
Irreversibility Gadget is a validity tool for data guaranteed by Ethereum consensus that LC can obtain. We need all verifiers to be confident that the blob data is valid. An intuitive idea is to wait for Ethereum L1 finalization, but this requires about 15 mins of latency. So is it possible for us to achieve lower latency?
For most L2s, the sequencer is an additional trust assumption, so we can utilize the sequencer to provide such validity guarantees by having the sequencer sign the blobs. Of course, this security guarantee is very low and places too much trust in the sequencer, so we can place certain restrictions on the sequencer through staking and slashing mechanisms.
Another approach is to still rely on Ethereum L1, but achieve effects like SSF by introducing organizations such as fast finality committees.

The purpose of the validity gadget is to make verifiers confident that the current output is computed from the input. Therefore, the simplest approach is to still rely on the additional trust assumption of the sequencer to endorse the output, having the sequencer execute based on the input to obtain the output. This approach has very low latency but questionable security, so we can still enhance security through stake/slash mechanisms.
Beyond this, we can also utilize TEE to obtain trusted output, which also provides very low latency while achieving decent security. Designs like fraud proofs can provide high security, but such dispute games introduce higher latency and system complexity.
The zk approach can achieve good security guarantees, but comes with very high latency and system complexity.

Once these two Gadgets are optimized to a production-ready level, a general-purpose L2 light client will no longer be an issue. This will not only enhance L2 verification capabilities but also bring decentralization and improved user experience to the broader multi-chain ecosystem.
Introduction of proof aggregation layer
As we know, if each L2 independently generates and submits its own ZKP, the cost of verifying these proofs on L1 can be extremely high. This issue becomes even more pronounced when multiple L2s states need to be verified simultaneously, as computation and storage costs quickly escalate. A natural optimization is to use Aggregate Proofs, which compress multiple ZKPs into a single proof, significantly reducing verification costs on both computation and storage fronts.
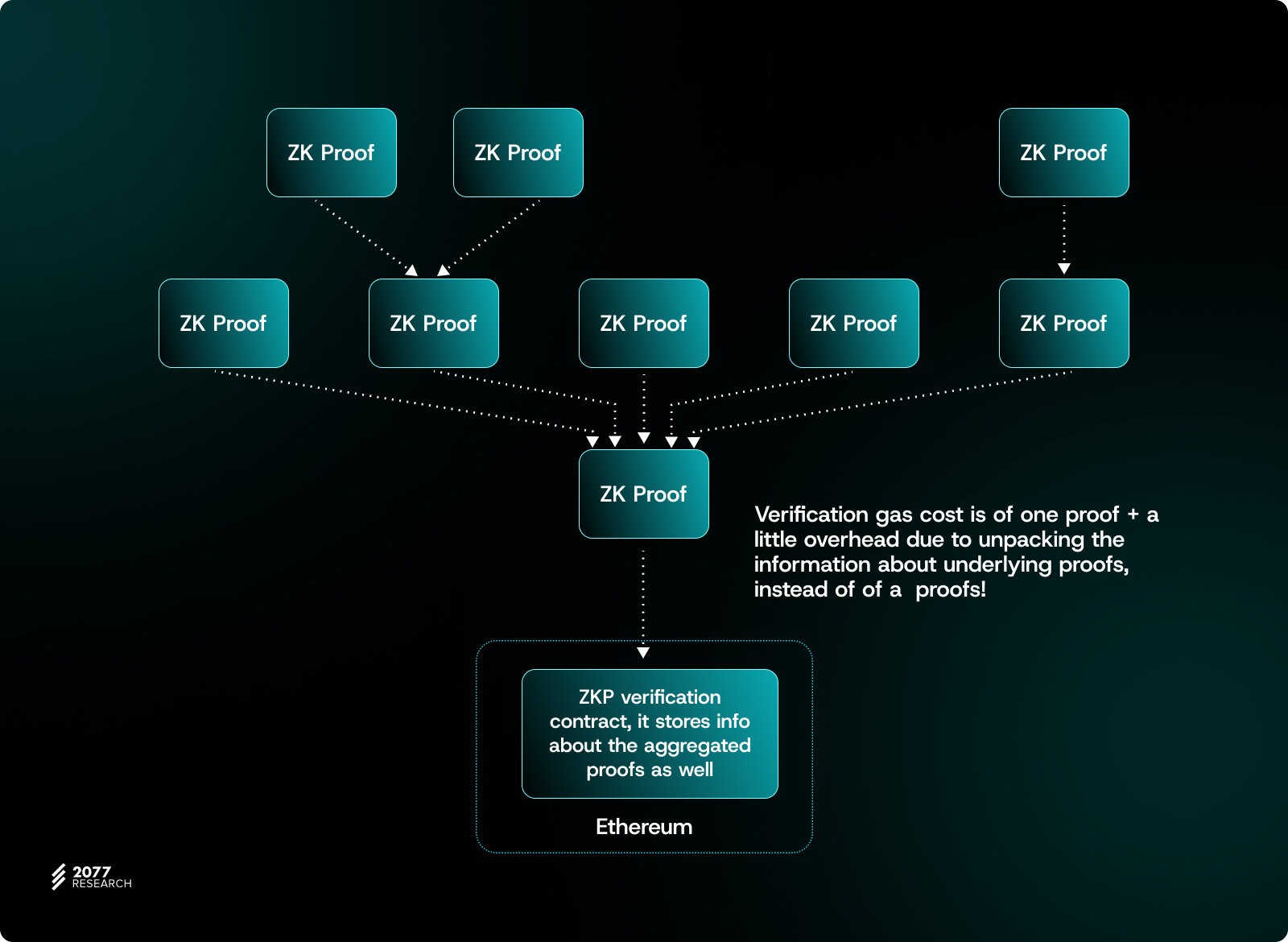
For native Rollup clusters like Optimism Superchain or zkSync Elastic Chain, generating aggregate proofs for homogeneous chains is relatively straightforward. For example, the Superchain can implement a [Shared Bridge](https://docs.optimism.io/superchain/superchain-explainer#properties-of-the-superchain), as there are minimal compatibility challenges within these frameworks. These setups not only simplify interoperability between chains but also reduce the complexity of cross-Rollup operations through standardized tools and protocols.
For heterogeneous L2s (L2s using different technical stacks and proof systems), the aggregation process is more challenging. One effective solution is to start at the proof system level, categorizing Rollups based on the proof systems they use (e.g., Groth16, PLONK, etc.), and then building further adaptation and standardization layers on top. By doing so, even if different L2s employ distinct proof technologies, we can achieve cross-Rollup aggregate proofs at a higher level, ultimately enhancing the efficiency and interoperability of the entire multi-chain ecosystem.
L1 dominant mint-and-burn bridge
ERC-7683's initial purpose is to simplify cross-chain exchanges of "Native Assets" between multiple chains. However, for "Bridged/Wrapped Assets", it typically requires executing mint operations on one side and burn (or lock-unlock) operations on the other side. When there exists a separate multisig committee controlling assets in the bridge, the security of these mint/burn operations essentially depends on this multisig setup. Therefore, for "cross-Rollup assets" to truly bind with L1 security, verifiable recording and settlement of cross-chain events needs to be conducted at the L1 layer. This is the motivation for designing an L1 dominant mint-and-burn bridge.
As described in ERC-7868, we need to introduce verifiable Cross Rollup input identifiers to identify cross-Rollup transaction sources and data. These identifiers can be cryptographically verified through execution results (such as block headers, state roots) submitted to L1 by the source Rollup. Building on this, "Settlement Time Validation" is performed, which means synchronously validating "cross-Rollup messages or cross-Rollup links" at settlement time. Here we can use two different settlement methods:
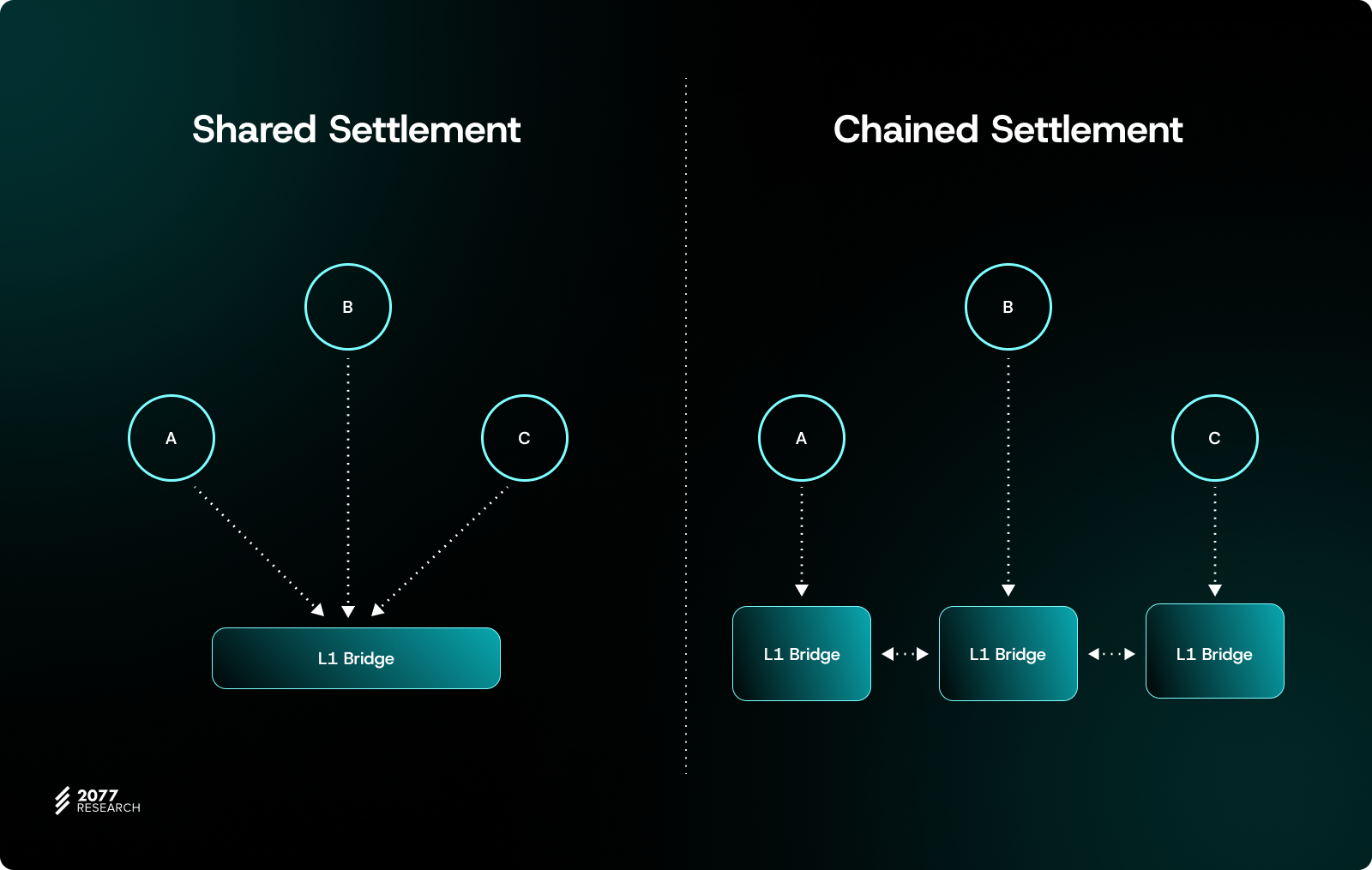
• Shared Settlement: All communicating Rollups share the same L1 Bridge for synchronous submission.• Chained Settlement: Each Rollup submits its own state and "cross-chain links pending verification," requiring results to be dependent on each other across the series of Rollups to complete the entire settlement.
This ensures that all cross-L2 operations are fully protected by L1 security at "final settlement time." This also avoids the centralization issues of traditional multisig bridges.
The ticker is ETH, the north star as well

Ethereum’s Rollup-Centric strategy has initially achieved the expansion of the multi-chain ecosystem, shifting a large amount of user activity from the high-cost L1 to the low-cost, high-throughput L2. However, with the continuous growth in the number of Rollups and the increasing maturity of the L2 ecosystem, the question of how to achieve a reasonable division of functions between L1 and L2 has become the core issue of the next phase.
We all hope to make Ethereum L1 the shared resource for all L2s, so what responsibilities should Ethereum undertake, and to what extent should L2s share it? As discussed above, varying degrees of reliance on shared resources allow L2s to achieve different levels of interop capabilities. At the same time, as a shared resource, we need to maintain its simplicity and highly abstract nature. Currently, Ethereum’s consensus mechanism and data availability service will provide a unified trust source for all L2s. Whether it is cross-chain asset transfers or state synchronization, Ethereum can be relied upon as the final arbiter. In addition, Ethereum can act as the communication hub between L2 Rollups, reducing inter-L2 communication latency and validation costs through proof aggregation, unified messaging protocols, and cross-chain bridging technologies. This is the meaning Ethereum brings to the L2 ecosystem—the ticker is ETH, and the north star is ETH as well.
We express our sincere gratitude to Bo Du, Tim Robinson, and Andreas Freund for reviewing this article.
Disclaimer: The content provided by 2077 Research is for informational purposes only and does not constitute financial, legal, or tax advice. The views expressed are those of the authors and do not necessarily reflect the opinions of 2077 Research or its affiliates. Readers should conduct their own research and exercise independent judgment when interpreting the information presented.




{kind=link}