UniFi: Rethinking the Ethereum Approach to Rollups
A new based restaking rollup design that enhances economic security and efficiency for rollups, addressing key challenges like transaction revenue loss and providing credible commitments for transaction outcomes.

It has been four years since Ethereum settled on a vertical approach to scaling, employing the use of interconnected stacks referred to as layer twos (and threes, and potentially fours), each with some degree of flexibility around their properties, to offer the optimal environment for boundless compute.
In crypto years, it's been decades, and the promise of a composable ecosystem is yet to be satisfied. This has recently led to a lot of unsavory criticism from certain proponents, who believe that abandoning L1 execution optimization was too much of a price to pay in pursuit of the L2 dream which hasn't lived up to expectations yet.
However, Ethereum has remained steadfast on the L2 path, which shouldn't be any surprise considering the amount of resources that have been expended for its realization; and the fact that no other practical solution exists that will allow scalability without hindering the network's coveted decentralization metric.
In this article, we present a somewhat comprehensive overview of rollups –everyone's favorite L2 scheme– on Ethereum; the expected value accrual to the L1 in a vertically-scaled regime; and the reality of both scalability and value accrual so far.
This is in order to understand the underlying value proposition of Puffer's approach to rollups– restaking-enhanced based rollups.
The theorized rollup-centric roadmap
The primary purpose of any general-purpose blockchain is to enable the processing of valid transactions which cause its state to be altered deterministically. This state is stored on its nodes and provides an insight into all the computational data (made up mostly of accounts and transactions) held by the chain from its genesis block.
As economic activity improves and a chain reaches escape velocity, its state grows proportionally and begins to affect the computational speed of the nodes keeping up with it. This directly leads to costlier block validation which is borne by the users via higher transaction fees; and higher transaction fees are a deterrent for economic activity.
At this stage, the chain could either choose to increase the computational capacity of individual nodes and scale “horizontally”. This means that the ability to produce and validate new blocks (and process new state) becomes gated by high entry costs. The presence of high entry costs translates to network centralization, and potentially the establishment of an oligopoly. We don't want that in Ethereum as decentralization is the network's core promise.
The second alternative is to offset computational efforts to a different stack which is better optimized for the task of computing and processing received inputs. This stack is kept compatible with the original chain via some mechanism that allows the former to benefit from the latter's security guarantees while remaining greatly flexible.
This is the approach employed by Ethereum via its layered architecture; which allows a different execution environment to be deployed atop the network and offer greater computational capacity, bounded on the lower end by Ethereum's own computational capacity.
There are various flavors of this implementation, but the most favored is rollups which take a hybrid approach to the process of data computation and storage. Rollups move most of their computational efforts and the incident state offchain, away from the L1; and so minimally store data on the L1 just to ensure its availability for verification.
As succinctly defined by Prestwich: A rollup is an opt-in, subset of another consensus, keeping a superset of state, via a custom state-transition function.
In the following subsections we will expand on this definition and then evaluate the definitive properties of rollup implementations.
Smart contract rollups
Smart contract rollups is used as an umbrella term here for the initial designs conceptualized for rollup L2s which were mostly execution-focused.
These sort of rollups offer a greatly optimized general-purpose execution environment separate from its parent chain, and only occasionally publish their activities to a pre-deployed contract on the parent chain –via a bridge– for finality/consensus and availability.
The various flavors of smart contract rollups is due to the ability of their designers to make tradeoffs in the following areas:
- The rollup's data compression/proof production method
- The rollup's proof submission/verification system
- The rollup's sequencing model
- The rollup's execution model
- The rollup's finality guarantees
These features aren't that hard to define, the problem is that they overlap a lot and so can be very easily confused, but don't worry– it's on.
Data Compression
As we discussed earlier, rollups are expected to occasionally publish their state to the parent chain in order to remain somewhat composable with it.
This could be done by just dumping its entire state onto the parent chain's block, obtaining consensus/finality from the latter's validation, and calling it a day; but that's greatly cost ineffective for both networks. The rollup will have to pay more for this since their state is likely to take up more blockspace on the parent chain; and the parent chain's nodes will suffer greatly from the stress of keeping up with both the execution carried out on it, and syncing the rollup's state.
So they have to compress their state using these beautiful things called merkle trees (or any other data structure, we're using merkle for triviality), and publish the resultant “state root” to their smart contract on the parent chain (L1 contract) as a sort of summary of their state over a specific period of time.
At some predefined epoch, batches of transactions executed on the rollup are compressed into the relevant structure and posted to the parent chain in a single transaction, by an approved agent. This transaction also includes the rollup's last submitted state root (pre-state root if you wish), which the L1 contract checks to make sure that it corresponds to the state root submitted in the last submitted transaction.
Proofs, proofing and proof verification
A proof in this context is simply cryptographic attestation that some activity occurred, with a means to allow anyone to derive the original activity from this minimalistic construction.
Constricting this a bit more; a proof is what the rollup submits to its parent chain to allow the latter to compute (and verify) its entire state, or a specific state transition, if the need arises.
While rollups are always aware of their parent chain's state –they keep up with it via a bidirectional bridge that either could use to communicate with themselves– the parent chain is only aware of the rollup's state due to the latter reporting it using the proofs we spoke of.
This leaves the rollup prone to a situation where an incorrect or fraudulent state transition is published and finalized on its parent chain.
To prevent such, it is expected that rollups should have a mechanism to report inconsistencies to their parent chain, before the latter finalizes the state published by anyone.
There are two mechanisms for proof publishing:
Fault proofs
These are published as proof that an anomaly occurred on the rollup. This might be due to an actor violating their privilege, or an execution error; either ways, fault proofs are published to prove fraud i.e., “this shouldn't have happened, but it did, and here's the proof that it did happen, so please undo it”.
This implementation is optimistic and so gives rise to optimistic rollups, as the underlying assumption is that the actions contained in the rollup's submitted state root are valid until contested.
Validity proofs
Which are published to allow the L1, or even anyone, to verify that a specified action occurred on the rollup. The logic of the action isn't consequential in this case, all that matters is whether it happened or not.
This implementation gives rise to zero-knowledge rollups which enforce the inclusion of a proof, showing that the state transition due to its contents are valid, in the transaction sent by the sequencer to the L1 contract.
Sequencing and ordering
So we talked of producing the state root (and proofs) and how they are published, let’s now talk about who's doing the publishing. Sequencing is a bit of a touchy subject, so we'll be treading very lightly here.
Sequencers are responsible for ordering and batching transactions on the rollup into simpler data structures and posting this data structure alongside a proof (in some cases) that the contents of the data structure actually occurred.
Thus, the sequencer produces a deterministic ordering of a set of transactions executed on the rollup, (possibly) compresses them, and then sends them to the L1 contract to be finalized.
In some implementations the sequencer is a full node and is responsible for both ordering a payload and giving guarantees that the payload will be executed in that order; others may choose to offset the production and publication of state roots to other agents.
The ability to challenge the published state root in optimistic rollups is also a permissioned role due to the mechanics of fraud proof games.
Execution model
General-purpose rollups have the ability to expand their computational capacity beyond that of their parent chain; they can choose for their execution environment to be backwards-compatible with the latter's or entirely abandon it for a new smart contract virtual machine.
This is where most of the magic happens as rollup teams will go out of their way to implement the better virtual machine. So far we have the OVM, WASM, various iterations of zkVMs; all with different levels of EVM-equivalence or -compliance, to enable smart contracts to run better.
Finality and Consensus
Depending on their setup and that of their parent chain, rollups are able to grant their users a notion of soft finality (otherwise known as preconfirmation) locally, before they can get consensus on the parent chain. The extent of this guarantee obviously depends on the setup of the system and the cost of false preconfirmations.
Either ways, the parent chain's consensus is persistently superior and is the only way for a rollup transaction to gain true finality.
So those were the technical details, but there's still the question of “why” and pesky economics; why would a potential alternate L1 blockchain choose to obtain finality from Ethereum for a fee; why would Ethereum even consider supporting potentially vampiric networks.
The full details are provided by Barnabé here, but the crust of it is this;
- Social sovereignty and data availability for the L2
- Scalability and data availability fees for the L1
The L2 gains some notion of social sovereignty from Ethereum's established social layer. This is implicit since we see a lot of support for rollups from reputable Ethereum contributors and researchers; there's also the shaky but noteworthy “ethereum alliance” metric.
It also gets a guarantee that its data/state is always available on an immutable layer, so that its nodes can forgo state storage and go all the way out on increasing the network's computational capacity.
On the other hand, Ethereum gets to scale in a hands-off manner by allowing new teams to leverage its secure framework and almost insurmountable total cost of attack (TCA).
The L1 is also expected to get some form of economic benefit from the L2 for the latter's use of its storage (which is where things get a bit sticky). The revenue here is due to providing the data availability service to rollups via EIP-4844’s blobs.
Rollups in action
A look at the l2beat website shows that after this entire time and with more than fifty live general-purpose rollups, we are yet to have any completely live up to their promises, less so the original expectations of their proponents.
This isn't to say that it has all been a wasted venture so far; individual teams have made great improvements across the stack, but various problems have remained persistent both in the technical and economic models of Ethereum's approach to scalability.
Below we evaluate the most consequential ones under a technical and economic framework.
Technical failings
- Fragmentation across stacks: due to the trust model of their native bridges and individualistic approaches to implementation, teams end up building complex stacks that are barely composable with Ethereum and less so with other rollups. While intent-based bridges have risen as a viable solution to this, there's barely any doubt that rollup native bridges will be more economically secure. Compatibility was abandoned while chasing peculiarity and this has led to the notion that L2s are completely distinct from their parent chain. If you want compatibility, you must start with compatibility.
- Centralized sequencing and validation: the ability to order transactions gives the sequencer an uncontested “last look” privilege, so that they can censor transactions and extract all sorts of MEV as they please. This has caused almost every performant rollup to employ a single sequencer that is maintained by their team. The ability to grant soft finality via validators is also permissioned.
These design choices grant users better experience but directly goes against Ethereum's ethos of decentralization. Ethos aside, there's also the issue that centralized sequencing is a nontrivial single point of failure, and downtimes at any point will be catastrophic for the rollup.
Economic failings
- It has always been an established fact that data isn't a particularly valuable commodity relative to computation/execution. Rollups take further advantage of offchain transaction execution to employ compression schemes and decrease the size of their posted payload, further decreasing the amount they pay for using the parent chain for data availability. Ethereum also pushes the margins via EIP-4844 to establish a multidimensional fee market for its DA services to rollups, so that they can get finality for even lesser costs. All this means that rollups do not pay “enough”; and that would be okay if Ethereum didn't prioritize its data availability duty to rollups over its execution duties to its own users and applications, even if for the short-term. This brings us to the next point below.
- Pushing most execution to its rollups means that more applications will be built on the rollups, which means existing (and incoming) users and value will be redistributed (and accrue) to a handful of barely compatible rollups, leaving economic activity on Ethereum to fizzle out.
This is also worsened by the fact that Ethereum doesn't directly benefit from economic activity on its rollups, unless in a benevolent manner.
Ultimately, the rollup space has under-delivered by a whole lot for a long time (#L222 was a thing) and “dissident” voices are now rising strongly in unison to demand that L1 execution should be reprioritized, and rollups left to their fate. However, we believe there's still some hope; vertical scaling remains the better way to offer more throughput without overtly impeding on decentralization and security, but it has to take a less-discussed approach that has only begun to see light under a new terminology.
Based rollups; primitive arising?
A wise man once wrote “It’s critical that Ethereum’s rollup fee capture is in addition to its native L1 execution, not reliant solely on it”. Well, how about we allow the L1 to benefit from the L2's execution and economic activity? That just might work too if done well, and it doesn't necessarily hinder the development of a better base later execution environment in the short to medium term.
This is the entire point of enshrined, booster, based rollups.
Smart contract rollups are generally implemented outside the L1's consensus gadget; the L1 doesn't have write access to their state, it merely reads and stores the state as reported to it. Based rollups flip this dynamic to allow agents on the L1 to implement a state transition function on the rollup through a shared environment with the latter, rather than having its state be reported to them only for finalization.
Intuitively, this means that agents on the L1 can directly benefit from economic activity on the rollup, thus expanding the L1's revenue and duties beyond data availability. It becomes a sequencer, occasionally performing execution for the rollup!
Beyond the simplification of the economic model, L1-sequencing grants based rollups certain technical advantages over smart contract rollups:
- They have better liveness guarantees due to their liveness being entirely equivalent to the L1's liveness. This also translates to better security guarantees, as they are directly protected by the L1's TCA rather than having to dispute/prevent faults using proofs.
- They are as decentralized as the L1, which puts them eons ahead of smart contract rollups that (mostly) still run on trust-enabled models across the board.
While this implementation is great for the L1, it pushes the opportunity cost over the margin for potential rollups launched in this way; as the latter is forced into forfeiting a considerable portion of their revenue while remaining relatively limited in their design choices due to the requirement that they are immediately compatible with the L1's consensus gadget.
However, these drawbacks can be easily overcome by the validator responsible for publishing the rollup's block at any time, if they are willing to.
Employing a validator set that opts into providing a portion of the extractable value in a proposed rollup block back to the rollup allows the latter to recapture some MEV; and a validator set which can provide economically secured optimistic preconfirmations for the rollup's payload essentially removes the constraints of the consensus gadget.
This is exactly what Puffer's UniFi is about: the establishment of validator sets that allow L1-sequenced rollups to trustlessly circumvent their limitations, using Eigenlayer's services.
Puffer's based rollups; combining primitives
Puffer is a native liquid restaking protocol which is built atop Eigenlayer to enable users to pool capital in ETH and spin up modules for a variety of Actively Validated Services (AVSs).
Eigenlayer's AVSs provide various services to various ecosystems and protocols in different contexts; their underlying value is that they enable setups where any protocol could inherit Ethereum's PoS-backed economic security, by incentivizing the validators who opt into the AVS with enhanced yield offerings on their stake.
Puffer supercharges this by decreasing the entry cost of participating in the Ethereum network as a validator node. It decreases the minimum 32 ETH requirement per validator by allowing multiple users to pool their ETH in a Puffer module.
Puffer modules are set up so that when the pooled ETH it is up to the minimum requirement, it is used to set up a validator via the NoOp function; so that an appointed node operator locks up some ETH in the validator ticket contract and mints a corresponding value of validator tickets, which they then deposit alongside some quantity of ETH to the Puffer contract in order to begin providing validation services and receiving yield.
After the validator has been setup, a restaking operator is employed by the protocol to oversee the management of the module's selected AVSs.
Thus, Puffer offers two functions via its modules:
- Liquid staking: similar to lido, rocket pool, and other liquid staking services which allow pooling of user ETH for the purpose of Ethereum native validation.
- Liquid restaking: allowing users to set their withdrawal credentials to an EigenPod, which allows their validation services to be extended beyond Ethereum to more exotic AVSs.
This setup allows Puffer to establish a variety of validator sets whose capital is deployed to secure select AVSs, conditional on the latter being approved by Puffer governance. The existence of these validator sets places Puffer in a unique position to elevate based rollups beyond their current challenges.
The synergy between restaking and based rollups
As hinted above, various types of protocols can choose to become an AVS atop Eigenlayer in order to benefit from Ethereum's economic guarantees provided by its TCA.
One of the obvious applications of this service would be allowing rollups to more concisely benefit from Ethereum's economic security with less hassles. We can even take things a step further and define guarantees which the AVS expects validators to satisfy, in order to enforce alignment, which is all the more better if the L1 is expected to have more leeway over the rollup!
Puffer's based rollups via UniFi
UniFi is an Eigenlayer AVS which decreases the cost of participating in the Ethereum network as a validator node via Puffer; while allowing users the benefits of better sequencing, execution and finality guarantees by allowing participating validators to issue credible commitments to users via Commit-Boost.
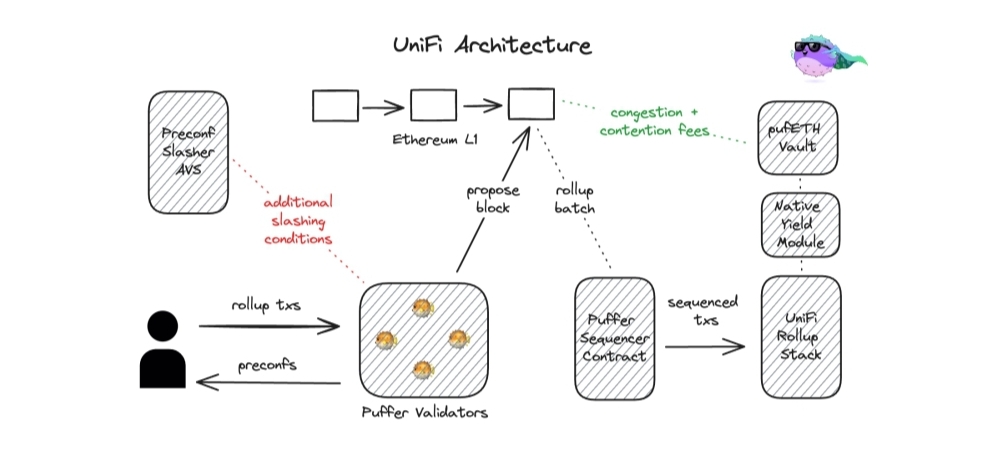
These credible commitments are akin to the notion of finality guarantees for a specific outcome on the users’ transactions, and are strictly more economically secure than commitments from an optimistic rollup with no fraud proof system as deviation from them will cause the offending validator to be slashed via Eigenlayer.
UniFis integration with Commit-Boost –which is a proposed standardized component of the MEV-Boost system– is what allows proposers (and other transaction executors) who opt into the system to make commitments to providing certain feature sets for users, by restricting the executors’ abilities as is necessary.
Some of its expected applications include:
- Committing to swap (and generally transaction) outcomes, so that users are guaranteed that their transactions are protected from toxic MEV.
- Committing to return a portion of MEV extracted per executable payload, so that the rollup doesn't entirely give up its MEV income whenever an L1 operator is responsible for sequencing.
The combination of these primitives grants UniFi a considerable head-start relative to vanilla based rollups. It can take advantage of Ethereum's decentralization without sacrificing too much revenue, while remaining able to offer preconfirmations. Thus, circumventing the two biggest problems associated with based rollups:
- Their limitation by the L1 consensus gadget; which Puffer solves via its integration with Commit-Boost that allows L1 operators to offer credible commitments towards a user's desired outcome on their transaction.
- Their loss of transaction execution revenue to the L1 operator for every L1-sequenced block; which Puffer solves via its Eigenlayer integration by specifying that a portion of the value an L1 operator gains is to be returned to the rollup, otherwise the operator risks being slashed.
Conclusion
Tying it all together; the adaptation of rollups as the pathway to “onboarding the next billion” crypto users has faced a lot of growing pains, especially considering its economic inconsistency for Ethereum that is faulted as the reason for the underlying asset's price stagnation. While we do not agree with this reasoning, there are still a lot of changes to be made across the board for trustless interoperability to be achieved, but the adaptation of community-wide standards has to be pushed.
Puffer's architecture offers an easy way out of the value accrual quagmire, without isolating itself from the existent ecosystem. It builds on and is integrated with standardized components and noteworthy primitives in a novel manner that positions it as a “provably-aligned” rollup whose value to Ethereum is immediately obvious.



