The Verge: Making Ethereum Verifiable And Sustainable
Explore how "The Verge," a pivotal Ethereum upgrade, leverages Verkle trees to enhance verifiability and sustainability. This article breaks down its role in reducing storage needs and driving network scalability.

The Path to Verifiability
Web3's core advantage is verifiability – users can verify how systems actually operate. This feature explains why many within and outside the crypto industry describe web3 as a step towards a more transparent and verifiable internet.
Unlike Web2 platforms like Facebook or Instagram, where algorithms and rules remain opaque even when documented, crypto protocols are designed for complete auditability. Even if they are shared, you lack the capability to verify whether the platform operates as specified. This is the opposite of crypto, where every protocol is designed to be as auditable as possible—or at least, it is expected to be.
Today, we will explore “The Verge”, a section from Vitalik’s recently published six-part series on Ethereum’s future, to analyze the steps Ethereum is taking toward achieving verifiability, sustainability, and scalability in the future. Under the heading "The Verge," we will discuss how blockchain architectures can be made more verifiable, the innovations these changes bring at the protocol level, and how they provide users with a more secure ecosystem. Let’s begin!
What does “verifiability” mean?
Web2 applications function as "black boxes" – users can only see their inputs and the resulting outputs, with no visibility into how the application actually works. In contrast, cryptocurrency protocols typically make their source code publicly available, or at minimum have plans to do so. This transparency serves two purposes: it allows users to interact directly with the protocol's code if they choose, and it helps them understand exactly how the system operates and what rules govern it.
“Decentralize what you can, verify the rest.”
Verifiability ensures that systems are accountable and, in many cases, guarantees that protocols function as intended. This principle highlights the importance of minimizing centralization, as it often leads to opaque, unaccountable structures where users cannot verify operations. Instead, we should strive to decentralize as much as possible and make the remaining elements verifiable and accountable where decentralization is not feasible.
The Ethereum community seems to align with this perspective, as the roadmap includes a milestone (called "The Verge") aimed at making Ethereum more verifiable. However, before diving into The Verge, we need to understand what aspects of blockchains should be verified and which parts are crucial from the users' perspective.
Blockchains essentially function as global clocks. In a distributed network with around 10,000 computers, it can take a significant amount of time for a transaction to propagate from the originating node to all other nodes. For this reason, nodes across the network cannot determine the exact order of transactions—whether one arrived before or after another—since they only have their own subjective perspectives.
Because the order of transactions is important, blockchain networks use specialized methods called “consensus algorithms” to ensure that nodes remain synchronized and process transaction sequences in the same order. Although nodes cannot determine the transaction order globally, consensus mechanisms enable all nodes to agree on the same sequence, allowing the network to function as a single, cohesive computer.
Beyond the consensus layer, there is also the execution layer that exists in every blockchain. The execution layer is shaped by the transactions that users want to execute.
Once transactions have been successfully ordered by consensus, each transaction must be applied to the current state at the execution layer. If you're wondering, "What is the state?", you've likely seen blockchains compared to databases—or more specifically, to a bank’s database because blockchains, like banks, maintain a record of everyone's balances.
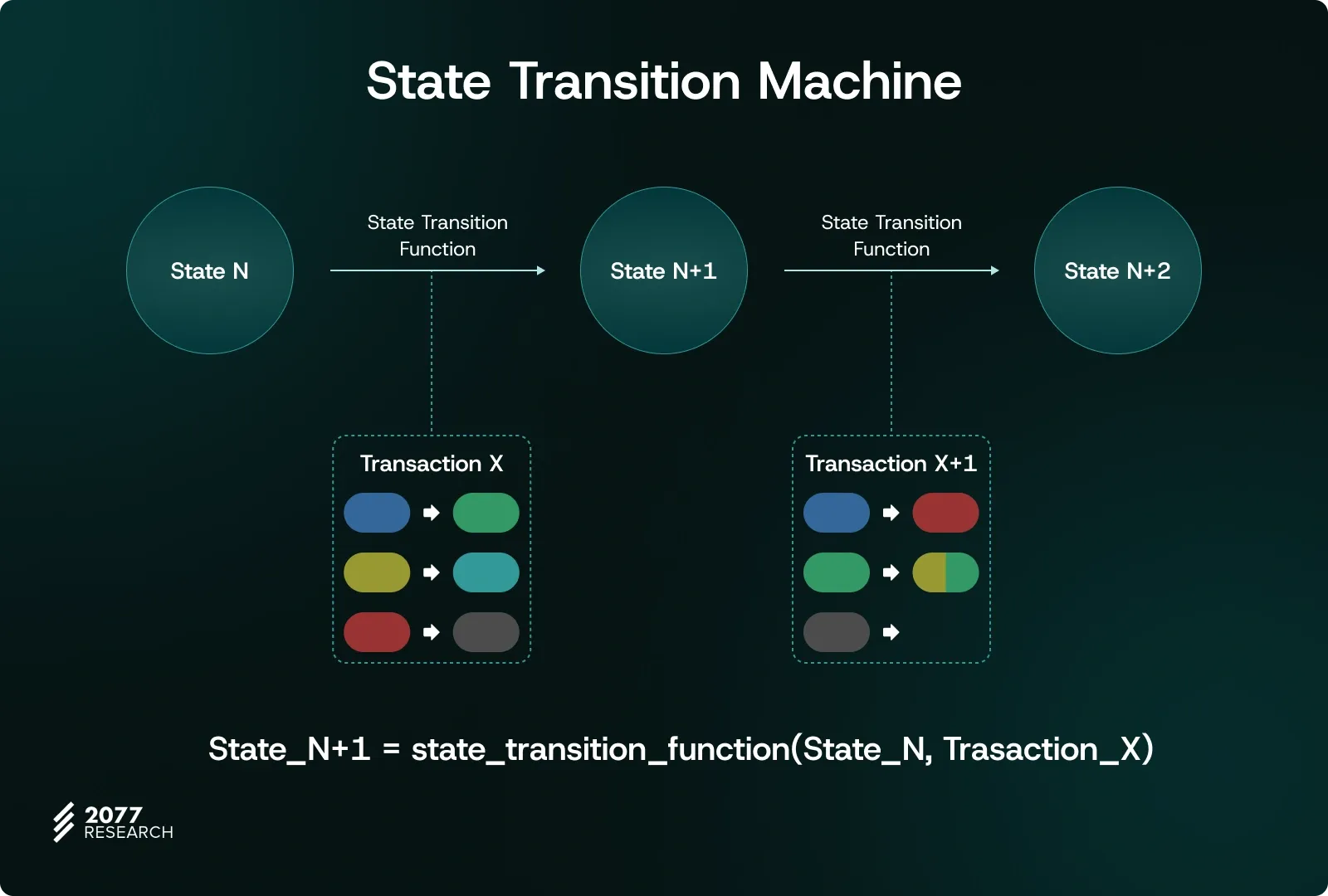
If you have $100 in the state we call "S" and want to send $10 to someone else, your balance in the next state, "S+1", will be $90. This process of applying transactions to move from one state to another is what we call an STF (State Transition Function).
In Bitcoin, the STF is primarily limited to balance changes, making it relatively simple. However, unlike Bitcoin, Ethereum's STF is much more complex because Ethereum is a fully programmable blockchain with an execution layer capable of running code.
In a blockchain, there are three fundamental components that you need—or are able—to verify:
- State: You may want to read a piece of data on the blockchain, but lack access to the state since you don’t run a full node. Therefore, you request the data via an RPC (Remote Procedure Call) provider like Alchemy or Infura. However, you must verify that the data has not been tampered with by the RPC provider.
- Execution: As mentioned earlier, blockchains utilize an STF. You must verify that the state transition was executed correctly—not on a per-transaction basis but on a block-by-block basis.
- Consensus: Third-party entities, like RPCs, can provide you with valid blocks that have not yet been included in the blockchain. Thus, you must verify that these blocks have been accepted through consensus and added to the blockchain.
If this seems confusing or unclear, don’t worry. We will go through each of these aspects in detail. Let’s start with how to verify blockchain state!
How to verify blockchain state?
Ethereum’s “state” refers to the set of data stored in the blockchain at any point in time. This includes balances of accounts (contract accounts and externally owned accounts or EOAs), smart contract code, contract storage, and more. Ethereum is a state-based machine because transactions processed in the Ethereum Virtual Machine (EVM) alter the previous state and produce a new state.
Each Ethereum block contains a value that summarizes the current state of the network after that block: the stateRoot. This value is a compact representation of the entire Ethereum state, consisting of a 64-character hash.
As each new transaction modifies the state, the stateRoot recorded in the subsequent block is updated accordingly. To calculate this value, Ethereum validators use a combination of the Keccak hash function and a data structure called the Merkle Tree to organize and summarize different parts of the state.
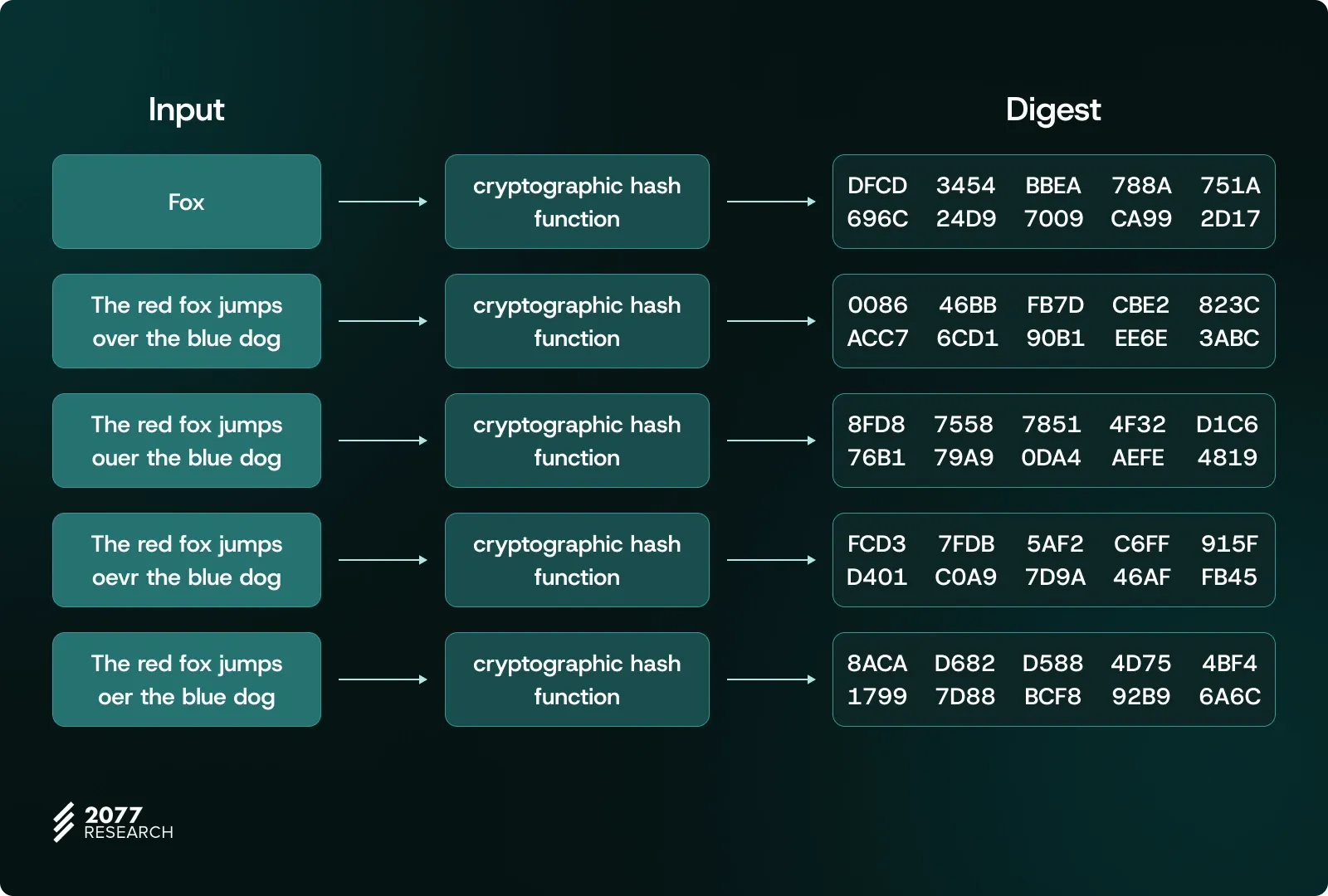
Hash functions are one-way functions that transform an input into a fixed-length output. In Ethereum, hash functions like Keccak are used to generate summaries of data, serving as a kind of fingerprint for the input. Hash functions have four fundamental properties:
- Determinism: The same input will always produce the same output.
- Fixed output length: Regardless of the input's length, the output length is always fixed.
- One-way property: It is practically impossible to derive the original input from the output.
- Uniqueness: Even a small change in the input produces a completely different output. Thus, a specific input maps to a practically unique output.
Thanks to these properties, Ethereum validators can perform the STF (State Transition Function) for each block—executing all transactions in the block and applying them to the state—and then verify whether the state indicated in the block matches the state obtained after the STF. This process ensures the proposer of the block has acted honestly, making it one of the validators' key responsibilities.
However, Ethereum validators do not hash the entire state directly to find its summary. Due to the one-way nature of hash functions, directly hashing the state would eliminate verifiability, as the only way to reproduce the hash would be to possess the entire state.
Since Ethereum’s state is terabytes in size, it is impractical to store the entire state on everyday devices like phones or personal computers. For this reason, Ethereum uses a Merkle tree structure to compute the stateRoot, preserving the verifiability of the state as much as possible.
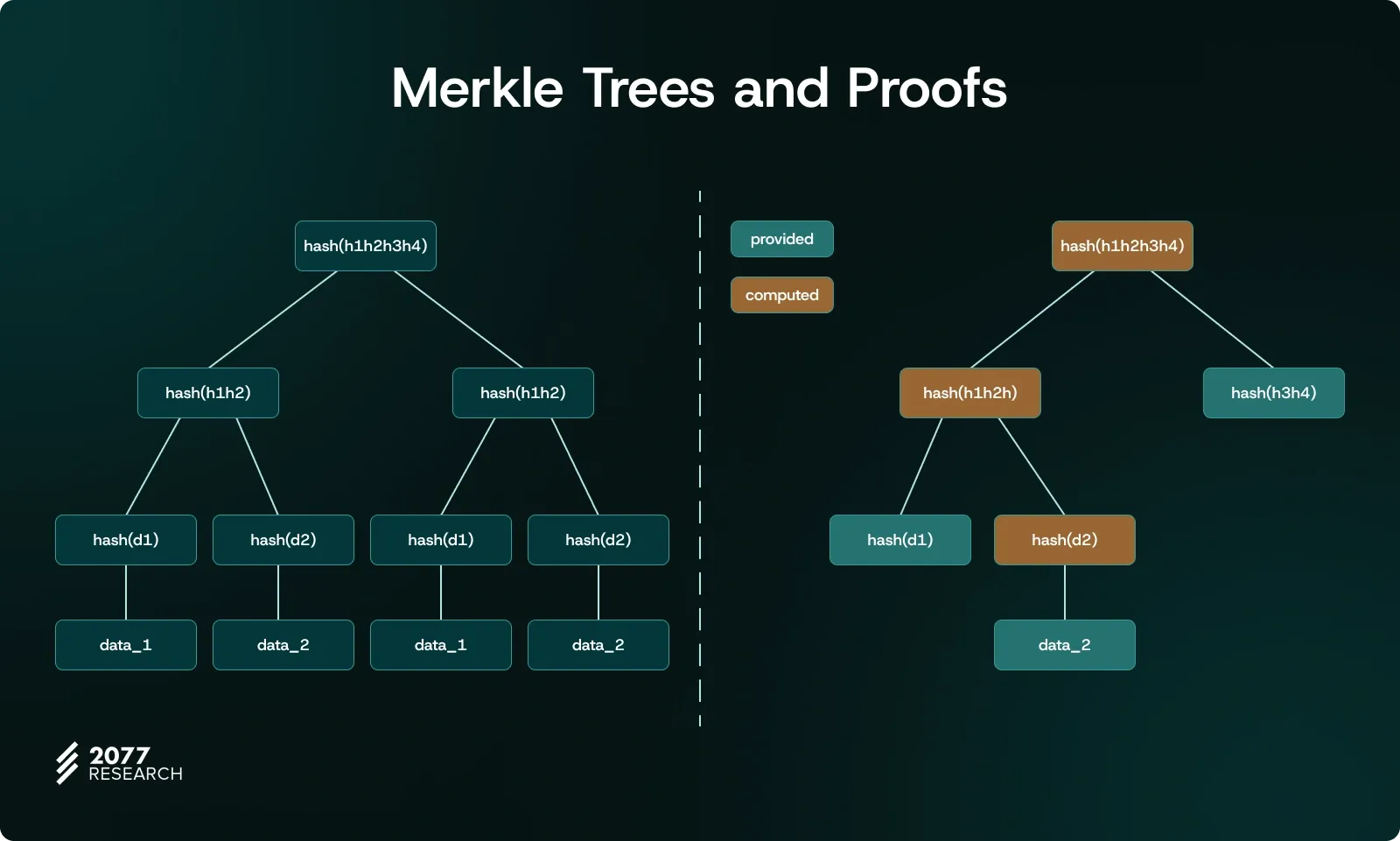
A Merkle tree is a cryptographic data structure used to securely and efficiently verify the integrity and correctness of data. Merkle trees are built upon hash functions and organize the hashes of a dataset hierarchically, enabling the verification of the integrity and correctness of this data. This tree structure consists of three types of nodes:
- Leaf nodes: These nodes contain the hashes of individual data pieces and are located at the bottom level of the tree. Each leaf node represents the hash of a specific piece of data in the Merkle tree.
- Branch nodes: These nodes contain the combined hashes of their child nodes. For instance, in a binary Merkle tree (where N=2), the hashes of two child nodes are concatenated and hashed again to produce the hash of a branch node at a higher level.
- Root node: The root node is at the topmost level of the Merkle tree and represents the cryptographic summary of the entire tree. This node is used to verify the integrity and correctness of all the data within the tree.
If you're wondering how to construct such a tree, it involves just two simple steps:
- Leaf node creation: Each piece of data is processed through a hash function, and the resulting hashes form the leaf nodes. These nodes resie at the lowwest level of the tree and represent the cryptographic summary of the data.

- Combine and hash: The hashes of the leaf nodes are grouped (e.g., in pairs) and combined, followed by hashing. This process creates branch nodes at the next level. The same process is repeated for the branch nodes until only a single hash remains.
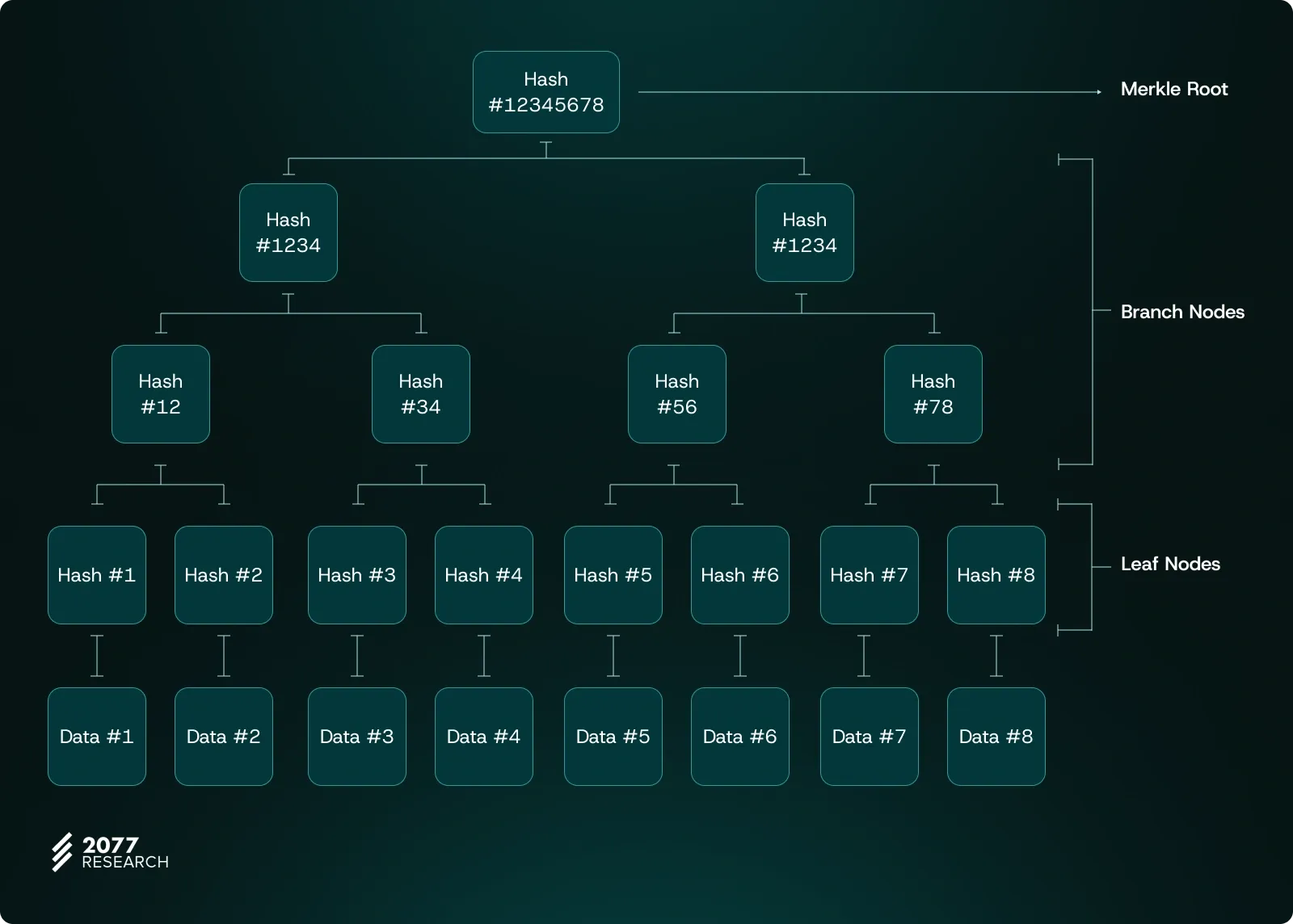
The final hash obtained at the top of the tree is called the Merkle root. The Merkle Root represents the cryptographic summary of the entire tree and allows for secure verification of data integrity.
How do we use Merkle roots to verify Ethereum’s state?
Merkle proofs enable the Verifier to efficiently validate specific pieces of data by providing a series of hash values that create a path from the targeted data (a leaf node) to the Merkle Root stored in the block header. This chain of intermediate hashes allows the Verifier to confirm the data's authenticity without needing to hash the entire state.
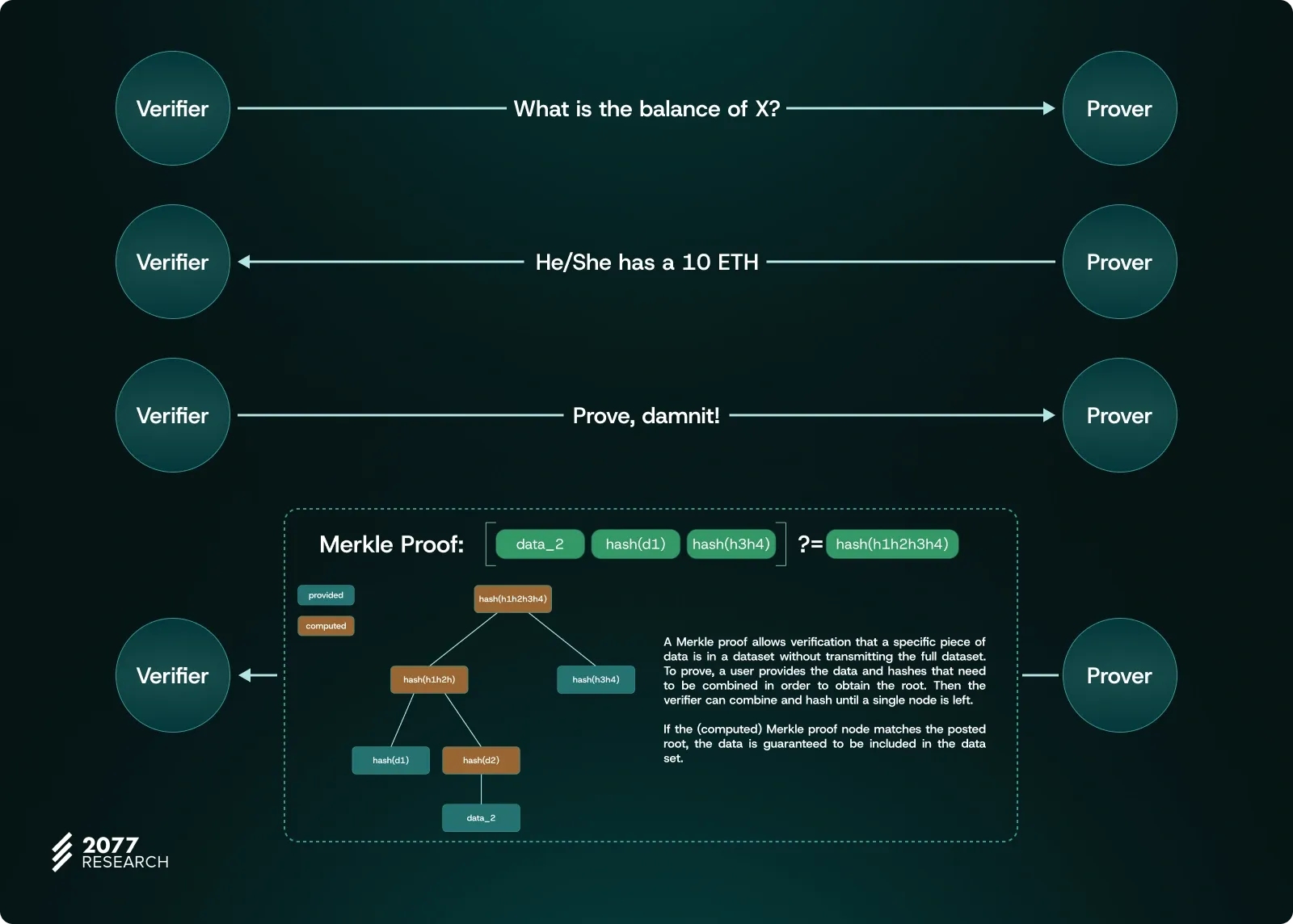
Starting from the specific data point, the Verifier combines it with each "sibling" hash provided in the Merkle Proof and hashes them step-by-step up the tree. This process continues until a single hash is produced. If this computed hash matches the stored Merkle Root, the data is considered valid; otherwise, the Verifier can determine that the data does not correspond to the claimed state.
Example: Verifying a data point with Merkle proof
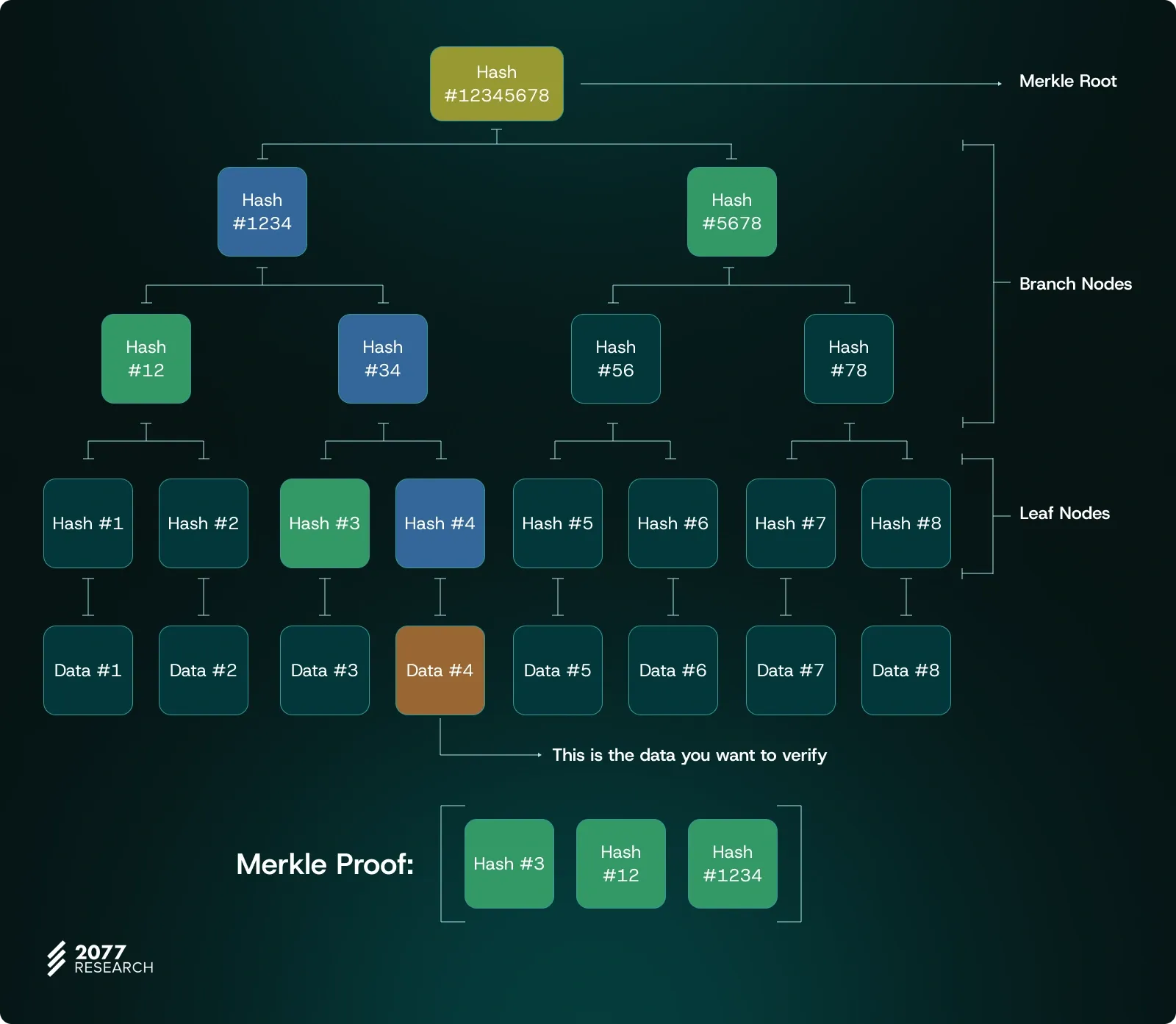
Let's say we have received Data #4 from an RPC and want to verify its authenticity using a Merkle Proof. To do this, the RPC would provide a set of hash values along the path needed to reach the Merkle Root. For Data 4, these sibling hashes would include Hash #3, Hash #12, and Hash #5678.
- Start with Data 4: First, we hash Data #4 to get Hash #4.
- Combine with Siblings: We then combine Hash #4 with Hash #3 (its sibling at the leaf level) and hash them together to produce Hash #34.
- Move Up the Tree: Next, we take Hash #34 and combine it with Hash #12 (its sibling in the next level up) and hash them to get Hash #1234.
- Final Step: Finally, we combine Hash #1234 with Hash #5678 (the last sibling provided) and hash them together. The resulting hash should match the Merkle Root (Hash #12345678) stored in the block header.
If the computed Merkle Root matches the state root in the block, we confirm that Data #4 is indeed valid within this state. If not, we know that the data does not belong to the claimed state, indicating potential tampering. As you can see, without providing the hashes of all the data or requiring the Verifier to reconstruct the entire Merkle Tree from scratch, the Prover can prove that Data #4 exists in the state and has not been altered during its journey—using just three hashes. This is the primary reason why Merkle Proofs are considered efficient.
While Merkle Trees are undoubtedly effective at providing secure and efficient data verification in large blockchain systems like Ethereum, are they truly efficient enough? To answer this, we must analyze how Merkle Tree performance and size impact the Prover-Verifier relationship.
Two Key Factors Affecting Merkle Tree Performance: ⌛
- Branching Factor: The number of child nodes per branch.
- Total Data Size: The size of the dataset being represented in the tree.
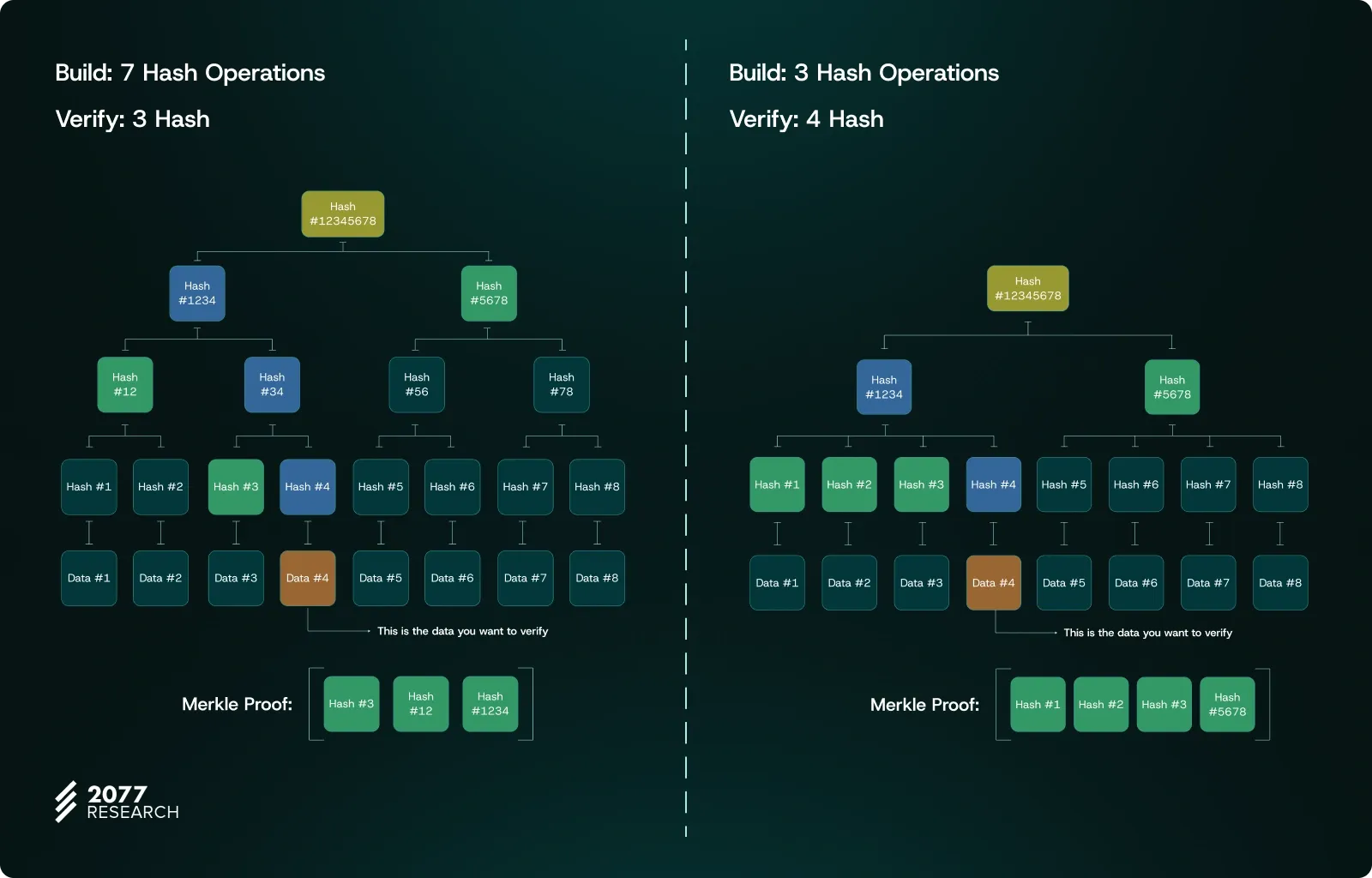
The Effect of Branching Factor:
Let’s use an example to better understand its impact. The branching factor determines how many branches emerge from each node in the tree.
- Small Branching Factor (e.g., Binary Merkle Tree):
If a binary Merkle Tree (branching factor of 2) is used, the proof size is very small, making the verification process more efficient for the Verifier. With only two branches at each node, the Verifier only needs to process one sibling hash per level. This speeds up verification and reduces the computational load. However, the reduced branching factor increases the height of the tree, requiring more hashing operations during tree construction, which can be burdensome for validators. - Larger Branching Factor (e.g., 4):
A larger branching factor (e.g., 4) reduces the height of the tree, creating a shorter and wider structure. This allows Full Nodes to construct the tree faster since fewer hash operations are needed. However, for the Verifier, this increases the number of sibling hashes they must process at each level, leading to a larger proof size. More hashes per verification step also mean higher computational and bandwidth costs for the Verifier, effectively shifting the burden from validators to verifiers.
The Effect of Total Data Size:
As the Ethereum blockchain grows, with each new transaction, contract, or user interaction adding to the dataset, the Merkle Tree must also expand. This growth not only increases the size of the tree but also impacts proof size and verification time.
- Full Nodes must process and update the growing dataset regularly to maintain the Merkle Tree.
- Verifiers, in turn, must validate longer and more complex proofs as the dataset grows, requiring additional processing time and bandwidth.
This growing data size increases the demand on both Full Nodes and Verifiers, making it harder to scale the network efficiently.
In summary, while Merkle Trees offer a degree of efficiency, they fall short of being an optimal solution for Ethereum’s continuously growing dataset. For this reason, during the The Verge phase, Ethereum aims to replace Merkle Trees with a more efficient structure known as Verkle Trees. Verkle Trees have the potential to deliver smaller proof sizes while maintaining the same level of security, making the verification process more sustainable and scalable for both Provers and Verifiers.
Chapter 2: Revolutionizing Verifiability in Ethereum - The Verge
The Verge was developed as a milestone in Ethereum’s roadmap aimed at improving verifiability, strengthening the blockchain’s decentralized structure, and enhancing network security. One of the primary goals of the Ethereum network is to enable anyone to easily run a validator to verify the chain, creating a structure where participation is open to everyone without centralization. The accessibility of this verification process is one of the key features that distinguishes blockchains from centralized systems. While centralized systems do not offer verification capabilities, the correctness of a blockchain is entirely in the hands of its users. However, to maintain this assurance, running a validator must be accessible to everyone—a challenge that, under the current system, is limited due to storage and computation requirements.
Since transitioning to a Proof-of-Stake consensus model with The Merge, Ethereum validators have had two primary responsibilities:
- Ensuring Consensus: Supporting the proper functioning of both probabilistic and deterministic consensus protocols and applying the fork-choice algorithm.
- Checking Block Accuracy: After executing the transactions in a block, verifying that the root of the resulting state tree matches the state root declared by the proposer.
To fulfill the second responsibility, validators must have access to the state prior to the block. This allows them to execute the block's transactions and derive the subsequent state. However, this requirement imposes a heavy burden on validators, as they need to handle significant storage requirements. While Ethereum is designed to be feasible and storage costs have been decreasing globally, the issue is less about cost and more about the reliance on specialized hardware for validators. The Verge aims to overcome this challenge by creating an infrastructure where full verification can be performed even on devices with limited storage, such as mobile phones, browser wallets, and even smartwatches, enabling validators to run on these devices.
First Step of the Verifiability: State
Transitioning to Verkle Trees is a key part of this process. Initially, The Verge focused on replacing Ethereum's Merkle Tree structures with Verkle Trees. The primary reason for adopting Verkle Trees is that Merkle Trees pose a significant obstacle to Ethereum’s verifiability. While Merkle Trees and their proofs can work efficiently in normal scenarios, their performance degrades drastically in worst-case scenarios.
According to Vitalik’s calculations, the average proof size is around 4 KB, which sounds manageable. However, in worst-case scenarios, the proof size can balloon to 330 MB. Yes, you read that correctly—330 MB.
The extreme inefficiency of Ethereum's Merkle Trees in worst-case scenarios stems from two primary reasons:
- Use of Hexary Trees: Ethereum currently uses Merkle Trees with a branching factor of 16. This means that verifying a single node requires providing the remaining 15 hashes in the branch. Given the size of Ethereum's state and the number of branches, this creates a substantial burden in worst-case scenarios.
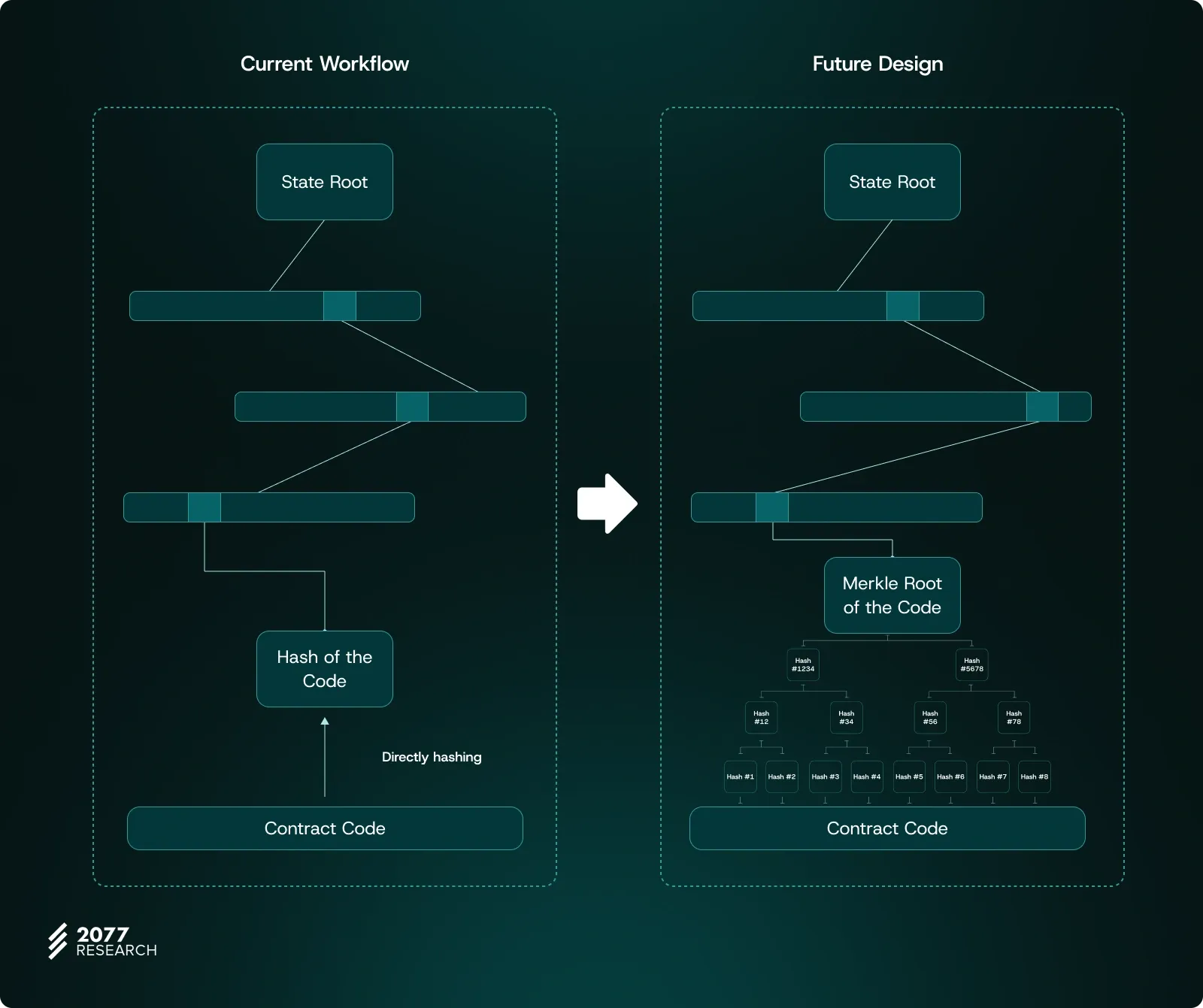
- Non-Merkelization of Code: Instead of incorporating contract code into the tree structure, Ethereum simply hashes the code and uses the resulting value as a node. Considering that the maximum size of a contract is 24 KB, this approach imposes a significant burden for achieving full verifiability.
Proof size is directly proportional to the branching factor. Reducing the branching factor decreases the proof size. To address these problems and improve worst-case scenarios, Ethereum could switch from Hexary Trees to Binary Merkle Trees and begin merklizing contract codes. If the branching factor in Ethereum is reduced from 16 to 2 and contract codes are also merklized, the maximum proof size could shrink to 10 MB. While this is a significant improvement, it’s important to note that this cost applies to verifying just one piece of data. Even a simple transaction accessing multiple pieces of data would require larger proofs. Given the number of transactions per block and Ethereum's continuously growing state, this solution, while better, is still not entirely feasible.
For these reasons, the Ethereum community has proposed two distinct solutions to address the issue:
- Verkle Trees
- STARK Proofs + Binary Merkle Trees
Verkle Trees & Vector Commitments

Verkle Trees, as the name suggests, are tree structures similar to Merkle Trees. However, the most significant difference lies in the efficiency they offer during verification processes. In Merkle Trees, if a branch contains 16 pieces of data and we want to verify just one of them, a hash chain covering the other 15 pieces must also be provided. This significantly increases the computational burden of verification and results in large proof sizes.
In contrast, Verkle Trees utilize a specialized structure known as "Elliptic Curve-based Vector Commitments", more specifically, an Inner Product Argument (IPA)-based Vector Commitment. A vector is essentially a list of data elements organized in a specific sequence. Ethereum’s state can be thought of as a vector: a structure where numerous data pieces are stored in a particular order, with each element being crucial. This state comprises various data components such as addresses, contract codes, and storage information, where the order of these elements plays a critical role in access and verification.
Vector Commitments are cryptographic methods used for proving and verifying data elements within a dataset. These methods allow verification of both the existence and order of each element in a dataset simultaneously. For example, Merkle Proofs, used in Merkle Trees, can also be considered a form of Vector Commitment. While Merkle Trees require all relevant hash chains to verify an element, the structure inherently proves that all elements of a vector are connected in a specific sequence.
Unlike Merkle Trees, Verkle Trees employ elliptic curve-based vector commitments that offer two key advantages:
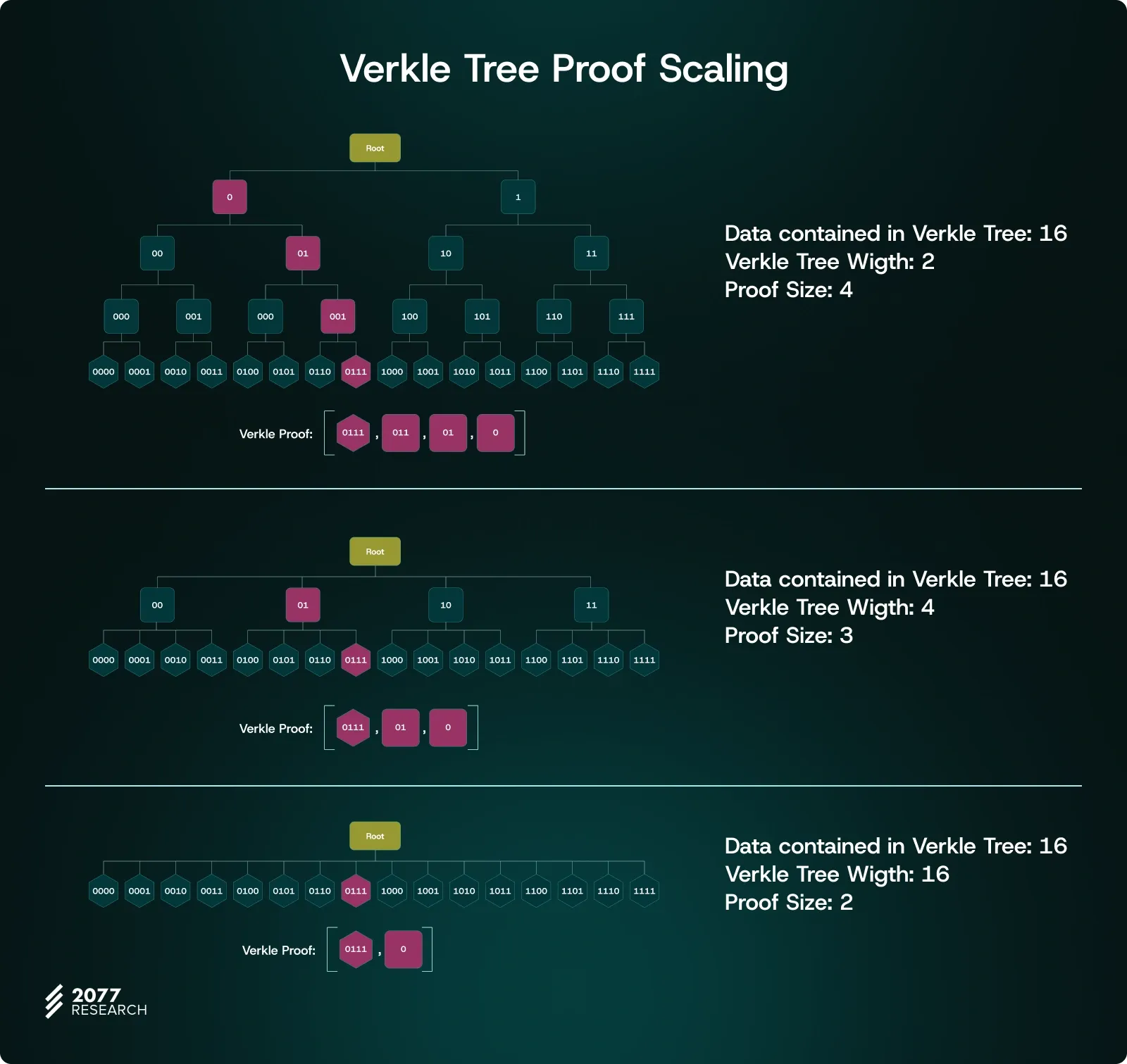
- Elliptic curve-based vector commitments eliminate the need for details of elements other than the data being verified. In Merkle Trees with a branching factor of 16, verifying a single branch requires providing the other 15 hashes. Given the vast size of Ethereum's state, which involves many branches, this creates a significant inefficiency. Elliptic curve-based vector commitments, however, remove this complexity, enabling verification with less data and computational effort.
- Through multi-proofs, the proofs generated by elliptic curve-based vector commitments can be compressed into a single, constant-size proof. Ethereum’s state is not only large but also continuously growing, meaning the number of branches that need verification to access the Merkle Root increases over time. However, with Verkle Trees, we can "compress" the proofs for each branch into a single constant-size proof using the method detailed in Dankrad Feist's article. This allows Verifiers to validate the entire tree with one small proof instead of verifying each branch individually. This also means that Verkle Trees are unaffected by the growth of Ethereum’s state.
These features of elliptic curve-based vector commitments significantly reduce the amount of data needed for verification, allowing Verkle Trees to produce small, constant-size proofs even in worst-case scenarios. This minimizes data overhead and verification times, improving the efficiency of large-scale networks like Ethereum. As a result, the use of elliptic curve-based vector commitments in Verkle Trees enables more manageable and efficient handling of Ethereum’s expanding state.
Like all innovations, Verkle Trees have their limitations. One of their main drawbacks is that they rely on elliptic curve cryptography, which is vulnerable to quantum computers. Quantum computers possess far greater computational power than classical methods, posing a significant threat to elliptic curve-based cryptographic protocols. Quantum algorithms could potentially break or weaken these cryptographic systems, raising concerns about the long-term security of Verkle Trees.
For this reason, while Verkle Trees offer a promising solution toward statelessness, they are not the ultimate fix. However, figures like Dankrad Feist have emphasized that, while careful consideration is needed when integrating quantum-resistant cryptography into Ethereum, it’s worth noting that the KZG commitments currently used for blobs in Ethereum are also not quantum-resistant. Thus, Verkle Trees can serve as an interim solution, providing the network with additional time to develop more robust alternatives.
STARK proofs + Binary Merkle Trees
Verkle Trees offer smaller proof sizes and efficient verification processes compared to Merkle Trees, making it easier to manage Ethereum's ever-growing state. Thanks to Elliptic Curve-Based Vector Commitments, large-scale proofs can be generated with significantly less data. However, despite their impressive advantages, Verkle Trees' vulnerability to quantum computers makes them only a temporary solution. While the Ethereum community sees Verkle Trees as a short-term tool to buy time, the long-term focus is on transitioning to quantum-resistant solutions. This is where STARK Proofs and Binary Merkle Trees present a strong alternative for building a more robust verifiability infrastructure for the future.
In Ethereum’s state verification process, the branching factor of Merkle Trees can be reduced (from 16 to 2) by using Binary Merkle Trees. This change is a critical step to reduce proof sizes and make verification processes more efficient. However, even in the worst-case scenario, proof sizes can still reach 10 MB, which is substantial. This is where STARK Proofs come into play, compressing these large Binary Merkle Proofs to just 100-300 kB.
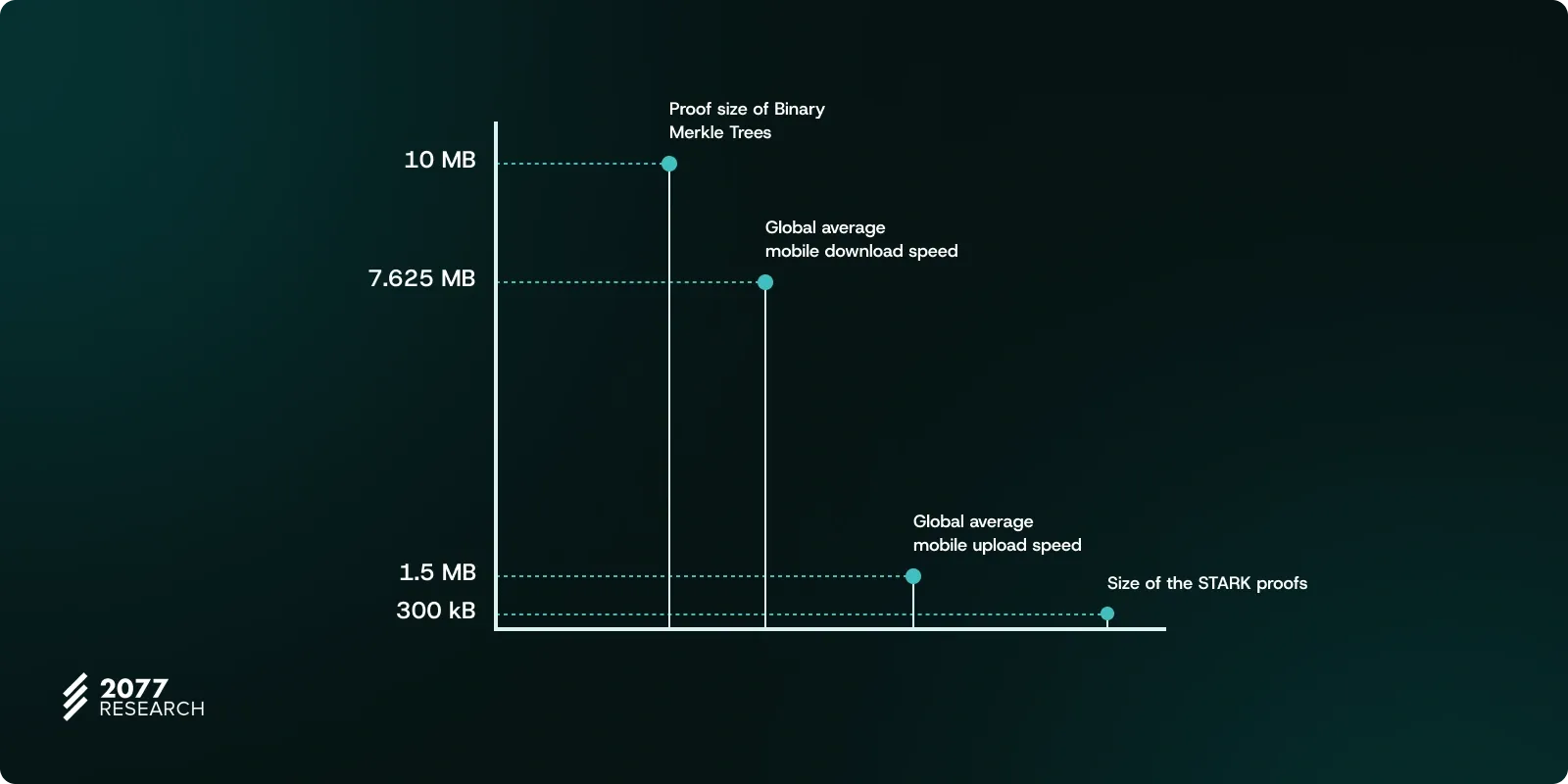
This optimization is particularly vital when considering the constraints of operating validators on light clients or devices with limited hardware, especially if you take into account that the average global mobile download and upload speeds are approximately 7.625 MB/s and 1.5 MB/s, respectively. Users can verify transactions with small, portable proofs without needing access to the full state, and validators can perform block verification tasks without storing the entire state.
This dual-benefit approach reduces both bandwidth and storage requirements for validators, while speeding up verification, three key improvements that directly support Ethereum's vision for scalability.
Key Challenges for STARK Proofs:
- High Computational Load for Provers:
The process of generating STARK proofs is computationally intensive, especially on the prover side, which can increase operational costs. - Inefficiency in Small Data Proofs:
While STARK proofs excel in handling large datasets, they are less efficient when proving small amounts of data, which can hinder their application in certain scenarios. When dealing with programs that involve smaller steps or datasets, the relatively large proof size of STARKs can make them less practical or cost-effective.
Quantum Security Comes at a Cost: Prover-Side Computational Load
A block’s Merkle Proof can include approximately 330,000 hashes, and in worst-case scenarios, this number can rise to 660,000. In such cases, a STARK proof would need to process around 200,000 hashes per second.
This is where zk-friendly hash functions like Poseidon come into play, specifically optimized for STARK proofs to reduce this load. Poseidon is designed to work more seamlessly with ZK-proofs compared to traditional hash algorithms like SHA256 and Keccak. The primary reason for this compatibility lies in how traditional hash algorithms operate: they process inputs as binary data (0s and 1s). On the other hand, ZK-proofs work with prime fields, mathematical structures that are fundamentally different. This situation is analogous to computers operating in binary while humans use a decimal system in everyday life. Translating bit-based data into ZK-compatible formats involves significant computational overhead. Poseidon solves this issue by natively operating within prime fields, dramatically accelerating its integration with ZK-proofs.
However, since Poseidon is a relatively new hash function, it requires more extensive security analysis to establish the same level of confidence as traditional hash functions like SHA256 and Keccak. To this end, initiatives like the Poseidon Cryptanalysis Initiative, launched by the Ethereum Foundation, invite experts to rigorously test and analyze Poseidon’s security, ensuring it can withstand adversarial scrutiny and become a robust standard for cryptographic applications. On the other hand, older functions like SHA256 and Keccak have already been extensively tested and have a proven security track record but are not ZK-friendly, resulting in performance drops when used with STARK proofs.

For example, STARK proofs using these traditional hash functions can currently process only 10,000 to 30,000 hashes. Fortunately, advancements in STARK technology suggest that this throughput could soon increase to 100,000 to 200,000 hashes, significantly improving their efficiency.
STARKs' inefficiency in proving small data
While STARK proofs excel at scalability and transparency for large datasets, they show limitations when working with small and numerous data elements. In these scenarios, the data being proved is often small, but the need for multiple proofs remains unchanged. Examples include:
- Post-AA transaction validation:
With Account Abstraction (AA), wallets can point to contract code, bypassing or customizing steps like nonce and signature verification, which are currently mandatory in Ethereum. However, this flexibility in validation requires checking the contract code or other associated data in the state to prove transaction validity. - Light client RPC calls:
Light clients query state data from the network (e.g., during an eth_call request) without running a full node. To guarantee the correctness of this state, proofs must support the queried data and confirm that it matches the current state of the network. - Inclusion lists:
Smaller validators can use inclusion list mechanisms to ensure transactions are included in the next block, limiting the influence of powerful block producers. However, validating the inclusion of these transactions requires verifying their correctness.
In such use cases, STARK proofs provide little advantage. STARKs, emphasizing scalability (as highlighted by the "S" in their name), perform well for large datasets but struggle with small data scenarios. By contrast, SNARKs, designed for succinctness (as emphasized by the "S" in their name), focus on minimizing proof size, offering clear advantages in environments with bandwidth or storage constraints.
STARK proofs are typically 40–50 KB in size, which is about 175 times larger than SNARK proofs, which are only 288 bytes. This size difference increases both verification time and network costs. The primary reason for STARKs’ larger proofs is their reliance on transparency and polynomial commitments to ensure scalability, which introduces performance costs in small-data scenarios. In such cases, faster and more space-efficient methods like Merkle Proofs might be more practical. Merkle Proofs offer low computational costs and rapid updates, making them suitable for these situations.
Nevertheless, STARK proofs remain crucial for Ethereum’s stateless future due to their quantum security.
Algorithm | Proof Size | Security Assumptions | Worst-case Prover latency |
Verkle Trees | ~100 - 2,000 kB | Elliptic curve (not quantum-resistant) | < 1s |
STARK + Conservative hash functions | ~100 - 300 kB | Conservative hash functions | > 10s |
STARK + Relatively new hash functions | ~100 - 300 kB | Relatively new and less-tested hash functions | 1-2s |
Lattice-based Merkle Trees | Verkle Trees > x > STARKs | Ring Short-Integer-Solution (RSIS) problem | - |
As summarized in the table, Ethereum has four potential paths to choose from:
- Verkle Trees
- Verkle Trees have received broad support from the Ethereum community, with biweekly meetings held to facilitate their development. Thanks to this consistent work and testing, Verkle Trees stand out as the most mature and well-researched solution among current alternatives. Moreover, their additively homomorphic properties eliminate the need to recompute every branch to update the state root, unlike Merkle Trees, making Verkle Trees a more efficient option. Compared to other solutions, Verkle Trees emphasize simplicity, adhering to engineering principles like “keep it simple” or “simple is the best.” This simplicity facilitates both integration into Ethereum and security analysis.
- However, Verkle Trees are not quantum secure, which prevents them from being a long-term solution. If integrated into Ethereum, this technology would likely need to be replaced in the future when quantum-resistant solutions are required. Even Vitalik views Verkle Trees as a temporary measure to buy time for STARKs and other technologies to mature. Additionally, the elliptic curve-based vector commitments used in Verkle Trees impose a higher computational load compared to simple hash functions. Hash-based approaches may offer faster synchronization times for full nodes. Furthermore, the reliance on numerous 256-bit operations makes Verkle Trees harder to prove using SNARKs within modern proving systems, complicating future efforts to reduce proof sizes.
Nonetheless, it’s important to note that Verkle Trees, due to their non-reliance on hashing, are significantly more provable than Merkle Trees.
- STARKs + Conservative Hash Functions
- Combining STARKs with well-established conservative hash functions like SHA256 or BLAKE provides a robust solution that strengthens Ethereum’s security infrastructure. These hash functions have been widely used and extensively tested in both academic and practical domains. Additionally, their quantum resistance enhances Ethereum’s resilience against future threats posed by quantum computers. For security-critical scenarios, this combination offers a reliable foundation.
- However, the use of conservative hash functions in STARK systems introduces significant performance limitations. The computational requirements of these hash functions result in high prover latency, with proof generation taking over 10 seconds. This is a major disadvantage, especially in scenarios like block validation that demand low latency. While efforts like multidimensional gas proposals attempt to align worst-case and average-case latency, the results are limited. Additionally, although hash-based approaches can facilitate faster synchronization times, their efficiency might not align with STARKs’ broader scalability goals. The long computation times of traditional hash functions reduce practical efficiency and limit their applicability.
- STARKs + Relatively New Hash Functions
- STARKs combined with new-generation STARK-friendly hash functions (e.g., Poseidon) significantly improve the performance of this technology. These hash functions are designed to integrate seamlessly with STARK systems and drastically reduce prover latency. Unlike traditional hash functions, they enable proof generation in as little as 1–2 seconds. Their efficiency and low computational overhead enhance the scalability potential of STARKs, making them highly effective for handling large datasets. This capability makes them particularly appealing for applications requiring high performance.
- However, the relative novelty of these hash functions necessitates extensive security analysis and testing. The lack of comprehensive testing introduces risks when considering their implementation in critical ecosystems like Ethereum. Additionally, since these hash functions are not yet widely adopted, the required testing and validation processes could delay Ethereum’s verifiability goals. The time needed to fully ensure their security might make this option less attractive in the short term, potentially postponing Ethereum’s scalability and verifiability ambitions.
- Lattice-based Merkle Trees
- Lattice-based Merkle Trees offer a forward-thinking solution that combines quantum security with the update efficiency of Verkle Trees. These structures address the weaknesses of both Verkle Trees and STARKs and are considered a promising long-term option. With their lattice-based design, they provide strong resistance to quantum computing threats, aligning with Ethereum’s focus on future-proofing its ecosystem. Moreover, by retaining the updatability advantages of Verkle Trees, they aim to deliver enhanced security without sacrificing efficiency.
- However, research on lattice-based Merkle Trees is still in its early stages and largely theoretical. This creates significant uncertainty about their practical implementation and performance. Integrating such a solution into Ethereum would require extensive research and development, as well as rigorous testing to validate its potential benefits. These uncertainties and infrastructural complexities make lattice-based Merkle Trees unlikely to be a feasible choice for Ethereum in the near future, potentially delaying progress toward the network’s verifiability objectives.
What about execution: Validity proofs of EVM execution
Everything we’ve discussed so far revolves around removing the need for validators to store the previous state, which they use to transition from one state to the next. The goal is to create a more decentralized environment where validators can perform their duties without maintaining terabytes of state data. Even with the solutions we’ve mentioned, validators wouldn’t need to store the entire state, as they would receive all the data required for execution through witnesses included with the block. However, to transition to the next state—and thereby verify the stateRoot on top of the block—validators must still execute the STF themselves. This requirement, in turn, poses another challenge to Ethereum’s permissionless nature and decentralization.
Initially, The Verge was envisioned as a milestone that focused solely on transitioning Ethereum’s state tree from Merkle Trees to Verkle Trees to improve state verifiability. Over time, however, it has evolved into a broader initiative aimed at enhancing the verifiability of state transitions and consensus. In a world where the trio of State, Execution, and Consensus is fully verifiable, Ethereum validators could operate on virtually any device with an internet connection that can be categorized as a Light Client. This would bring Ethereum closer to achieving its vision of “true decentralization.”
What is the problem definition?
As we mentioned earlier, validators execute a function called STF (State Transition Function) every 12 seconds. This function takes the previous state and a block as inputs and produces the next state as output. Validators must execute this function every time a new block is proposed and verify that the hash representing the state on top of the block—commonly referred to as the state root—is correct.
The high system requirements for becoming a validator primarily stem from the need to perform this process efficiently.

If you want to turn a smart refrigerator—yes, even a refrigerator—into an Ethereum validator with the help of some installed software, you face two major obstacles:
- Your refrigerator most likely won’t have sufficiently fast internet, which means it won’t be able to download the data and proofs needed for execution even with the state verifiability solutions we’ve discussed so far.
- Even if it had access to the necessary data for STF, it won’t have the computational power required to perform execution from start to finish or to build a new state tree.
To solve the issues caused by Light Clients not having access to either the previous state or the entirety of the last block, The Verge proposes that the proposer should perform the execution and then attach a proof to the block. This proof would include the transition from the previous state root to the next state root as well as the block’s hash. With this, Light Clients can validate the state transition using just three 32-byte hashes, without needing a zk-proof.
However, since this proof works through hashes, it would be incorrect to say it only validates the state transition. On the contrary, the proof attached to the block must validate multiple things simultaneously:
State root in the previous block = S, State root in the next block = S + 1,
Block hash = H
- The block itself must be valid, and the state proof inside it—whether a Verkle Proof or STARKs—must accurately verify the data accompanying the block.
In short: Validation of the block and the accompanying state proof. - When the STF is executed using the data required for execution and included in the block corresponding to H, the data that should change in the state must be updated correctly.
In short: Validation of the state transition. - When a new state tree is rebuilt with the correctly updated data, its root value must match S + 1.
In short: Validation of the tree construction process.
In the Prover-Verifier analogy we referenced earlier, it is generally fair to say that there is usually a computational balance between the two actors. While the ability of proofs required to make the STF verifiable to validate multiple things simultaneously offers significant advantages for the Verifier, it also indicates that generating such proofs to ensure the correctness of execution will be relatively challenging for the Prover. With Ethereum's current speed, an Ethereum block needs to be proven in under 4 seconds. However, even the fastest EVM Prover we have today can only prove an average block in approximately 15 seconds.[1]
That being said, there are three distinct paths we can take to overcome this major challenge:
- Parallelization in Proving & Aggregation: One of the significant advantages of ZK-proofs is their ability to be aggregated. The capability to combine multiple proofs into a single, compact proof provides substantial efficiency in terms of processing time. This not only reduces the load on the network but also accelerates verification processes in a decentralized manner. For a large network like Ethereum, it enables the more efficient generation of proofs for each block.
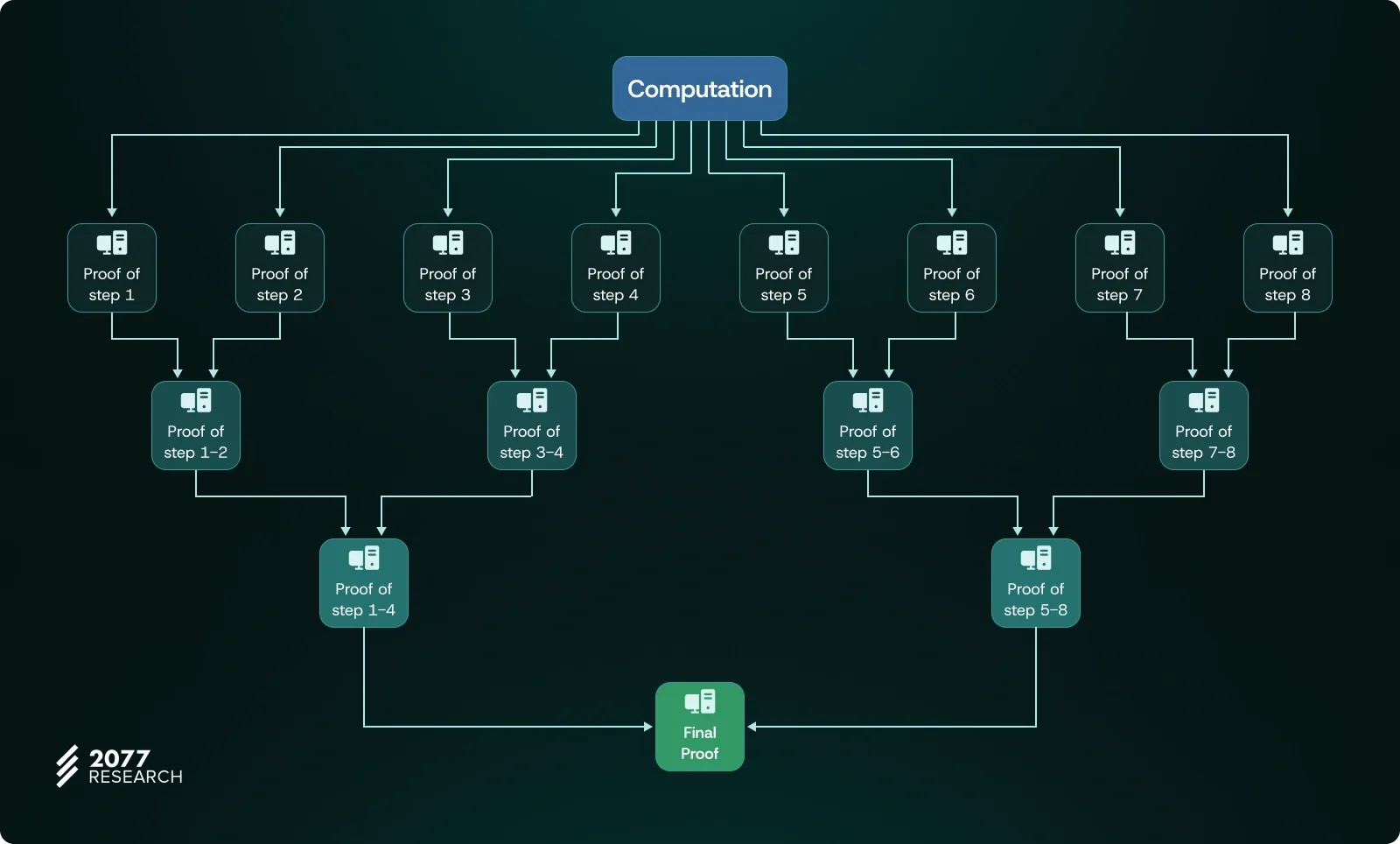
During proof generation, every small piece of the execution process (e.g., computation steps or data access) can be proven individually, and these proofs can later be aggregated into a single structure. With the correct mechanism, this approach allows a block’s proofs to be generated quickly and in a decentralized manner by many different sources (e.g., hundreds of GPUs). This boosts performance while also contributing to the decentralization goal by engaging a broader pool of participants.
- Using Optimized Proof Systems: New-generation proof systems have the potential to make Ethereum's computational processes faster and more efficient. Advanced systems like Orion, Binius, and GKR can significantly reduce prover time for general-purpose computations. These systems aim to overcome the limitations of current technologies, increasing processing speed while consuming fewer resources. For a scalability- and efficiency-focused network like Ethereum, such optimizations provide a significant advantage. However, the full implementation of these new systems requires comprehensive testing and compatibility efforts within the ecosystem.
- Gas Cost Changes: Historically, gas costs for operations on the Ethereum Virtual Machine (EVM) were typically determined based on their computational costs. However, today, another metric has gained prominence: prover complexity. While some operations are relatively easy to prove, others have a more complex structure and take longer to verify. Adjusting gas costs not only based on computational effort but also on the difficulty of proving operations is critical for enhancing both the network's security and efficiency.
This approach can minimize the gap between worst-case and average-case scenarios, enabling more consistent performance. For instance, operations that are harder to prove could have higher gas costs, while those that are easier to prove could have lower costs. Additionally, replacing Ethereum’s data structures (such as the state tree or transaction list) with STARK-friendly alternatives could further accelerate proof processes. Such changes would help Ethereum achieve its scalability and security goals while making its verifiability vision more realistic.
Ethereum’s efforts to enable execution proofs represent a significant opportunity to achieve its verifiability goals. However, reaching this goal requires not only technical innovations but also increased engineering efforts and critical decisions within the community. Making execution processes verifiable on Layer 1 must strike a balance between being accessible to a broad user base while preserving decentralization and aligning with the existing infrastructure. Establishing this balance increases the complexity of methods used to prove operations during execution, highlighting the need for advancements such as parallel proof generation. Additionally, the infrastructural requirements of these technologies (e.g., lookup tables) must be implemented and operationalized, which still demands substantial research and development.
On the other hand, specialized circuits (e.g., ASICs, FPGAs, GPUs) designed specifically for certain tasks hold significant potential for accelerating the proof generation process. These solutions provide much higher efficiency compared to traditional hardware and can speed up execution processes. However, Ethereum’s decentralization goals at the Layer 1 level prevent such hardware from being accessible to only a select group of actors. As a result, these solutions are expected to see more extensive use in Layer 2 systems. Nevertheless, the community must also reach a consensus on the hardware requirements for proof generation. A key design question emerges: should proof generation work on consumer-grade hardware like high-end laptops, or require industrial infrastructure? The answer shapes Ethereum's entire architecture – allowing aggressive optimization for Layer 2 solutions while demanding more conservative approaches for Layer 1.
Finally, the implementation of execution proofs is directly tied to Ethereum’s other roadmap objectives. The introduction of validity proofs would not only support concepts like statelessness but also enhance Ethereum’s decentralization by making areas such as solo staking more accessible. The goal is to enable staking on even the most low-spec devices. Additionally, restructuring gas costs on the EVM based on computational difficulty and provability could minimize the gap between average-case and worst-case scenarios. However, such changes could break backward compatibility with the current system and force developers to rewrite their code. For this reason, the implementation of execution proofs is not just a technical challenge—it is a journey that must be designed to uphold Ethereum’s long-term values.
Last step for the true full-verifiability: Consensus
Ethereum's consensus mechanism strives to establish a unique balance that preserves decentralization and accessibility while achieving verifiability goals. In this framework, probabilistic and deterministic consensus methods offer distinct advantages and challenges.
Probabilistic consensus is built on a gossiping communication model. In this model, instead of directly communicating with all nodes representing the network, a node shares information with a randomly selected set of 64 or 128 nodes. A node's chain selection is based on this limited information, which introduces the possibility of error. However, over time, as the blockchain progresses, these selections are expected to converge toward the correct chain with a 0% error rate.
One advantage of the probabilistic structure is that each node does not broadcast its chain view as a separate message, reducing communication overhead. Consequently, such a structure can operate with far more permissionless, decentralized nodes with lower system requirements. In contrast, deterministic consensus operates through a one-to-all communication model. Here, a node sends its chain view as a vote to all other nodes. This approach generates higher message intensity, and as the number of nodes grows, the system may eventually reach its limits. However, the greatest advantage of deterministic consensus is the availability of concrete votes, allowing you to know exactly which node voted for which fork. This ensures fast and definitive chain finality, guaranteeing that blocks cannot have their order changed and making them verifiable.
To provide a verifiable consensus mechanism while preserving decentralization and a permissionless structure, Ethereum has struck a balance between slots and epochs. Slots, which represent 12-second intervals, are the basic units where a validator is responsible for producing a block. Although the probabilistic consensus used at the slot level allows the chain to operate more flexibly and in a decentralized manner, it has limitations in terms of definitive ordering and verifiability.
Epochs, which encompass 32 slots, introduce deterministic consensus. At this level, validators vote to finalize the chain’s order, ensuring certainty and making the chain verifiable. However, while this deterministic structure provides verifiability through concrete votes at the epoch level, it cannot offer full verifiability within the epochs themselves due to the probabilistic structure. To address this gap and strengthen the probabilistic structure within epochs, Ethereum has developed a solution known as the Sync Committee.
Altair’s Light Client Protocol: Sync Committee
The Sync Committee is a mechanism introduced with the Altair upgrade to overcome the limitations of Ethereum's probabilistic consensus and improve the verifiability of the chain for light clients. The committee consists of 512 randomly selected validators who serve for 256 epochs (~27 hours). These validators produce a signature representing the head of the chain, allowing light clients to verify the chain's validity without needing to download historical chain data. The operation of the Sync Committee can be summarized as follows:
- Formation of the Committee:
512 validators are randomly selected from all validators in the network. This selection is regularly refreshed to maintain decentralization and prevent reliance on a specific group. - Signature Generation:
Committee members produce a signature that represents the latest state of the chain. This signature is a collective BLS signature created by the members and is used to verify the chain's validity. - Light Client Verification:
Light clients can verify the chain's correctness by simply checking the signature from the Sync Committee. This allows them to securely track the chain without downloading past chain data.
However, the Sync Committee has been subject to criticism in some areas. Notably, the protocol lacks a mechanism to slash validators for malicious behavior, even if the selected validators act intentionally against the protocol. As a result, many consider the Sync Committee to be a security risk and refrain from fully classifying it as a Light Client Protocol. Nevertheless, the security of the Sync Committee has been mathematically proven, and further details can be found in this article on Sync Committee Slashings.
The absence of a slashing mechanism in the protocol is not a design choice but a necessity arising from the nature of probabilistic consensus. Probabilistic consensus does not provide absolute guarantees about what a validator observes. Even if the majority of validators report a particular fork as the heavier one, there can still be exceptional validators observing a different fork as heavier. This uncertainty makes it challenging to prove malicious intent and, thus, impossible to penalize misbehavior.
In this context, rather than labeling the Sync Committee as insecure, it would be more accurate to describe it as an inefficient solution. The issue does not stem from the Sync Committee's mechanical design or operation but from the inherent nature of probabilistic consensus. Since probabilistic consensus cannot offer definitive guarantees about what nodes observe, the Sync Committee is one of the best solutions that can be designed within such a model. However, this does not eliminate the weaknesses of probabilistic consensus in guaranteeing chain finality. The problem lies not with the mechanism but within Ethereum's current consensus structure.
Due to these limitations, there are ongoing efforts in the Ethereum ecosystem to redesign the consensus mechanism and implement solutions that provide deterministic finality in shorter periods. Proposals like Orbit-SSF and 3SF aim to reshape Ethereum’s consensus structure from the ground up, creating a more effective system to replace probabilistic consensus. Such approaches seek not only to shorten the chain's finality time but also to deliver a more efficient and verifiable network structure. The Ethereum community continues to actively develop and prepare these proposals for future implementation.
Snarkification of Consensus
The Verge aims to enhance Ethereum’s current and future consensus mechanisms by making them more verifiable through zk-proof technology, rather than replacing them entirely. This approach seeks to modernize Ethereum's consensus processes while preserving its core principles of decentralization and security. Optimizing all historical and current consensus processes of the chain with zk technologies plays a critical role in achieving Ethereum’s long-term scalability and efficiency goals. The fundamental operations used in Ethereum’s consensus layer are of great importance in this technological transformation. Let’s take a closer look at these operations and the challenges they face.
- ECADDs:
- Purpose: This operation is used to aggregate validators' public keys and is vital for ensuring the accuracy and efficiency of the chain. Thanks to the aggregateable nature of BLS signatures, multiple signatures can be combined into a single structure. This reduces communication overhead and makes verification processes on the chain more efficient. Ensuring synchronization among large validator groups more effectively makes this operation critical.
- Challenges: As previously mentioned, Ethereum’s validators vote on the chain’s order during epochs. Today, Ethereum is a network with approximately 1.1 million validators. If all validators tried to propagate their votes simultaneously, it would create significant strain on the network. To avoid this, Ethereum allows validators to vote on a slot basis during an epoch, where only 1/32 of all validators vote per slot. While this mechanism reduces network communication overhead and makes consensus more efficient, given today’s validator count, about 34,000 validators vote in each slot. This translates to approximately 34,000 ECADD operations per slot.
- Pairings:
- Purpose: Pairing operations are used for verifying BLS signatures, ensuring the validity of epochs on the chain. This operation allows for batch verification of signatures. However, it is not zk-friendly, making it extremely costly to prove using zk-proof technology. This presents a major challenge in creating an integrated verification process with zero-knowledge technologies.
- Challenges: Pairing operations in Ethereum are limited to a maximum of 128 attestations (aggregated signatures) per slot, resulting in fewer pairing operations compared to ECADDs. However, the lack of zk-friendliness in these operations poses a significant challenge. Proving a pairing operation with zk-proofs is thousands of times more expensive than proving an ECADD operation [2]. This makes adapting pairing operations for zero-knowledge technologies one of the greatest obstacles in Ethereum’s consensus verification processes.
- SHA256 Hashes:
- Purpose: SHA256 hash functions are used to read and update the chain’s state, ensuring the integrity of the chain’s data. However, their lack of zk-friendliness leads to inefficiencies in zk-proof-based verification processes, posing a major obstacle to Ethereum’s future verifiability goals.
- Challenges: SHA256 hash functions are frequently used for reading and updating the chain’s state. However, their zk-unfriendliness conflicts with Ethereum’s zk-proof-based verification goals. For example, between two epochs, each validator runs Ethereum’s Consensus Layer’s STF to update the state with rewards and penalties based on validator performance during the epoch. This process heavily relies on SHA256 hash functions, significantly increasing costs in zk-proof-based systems. This creates a substantial barrier to aligning Ethereum’s consensus mechanism with zk technologies.
The ECADD, Pairing, and SHA256 operations used in the current consensus layer play a critical role in Ethereum’s verifiability goals. However, their lack of zk-friendliness poses significant challenges on the path to achieving these objectives. ECADD operations create a costly burden due to the high volume of validator votes, while Pairing operations, despite being fewer in number, are thousands of times more expensive to prove with zk-proofs. Additionally, the zk-unfriendliness of SHA256 hash functions makes proving the beacon chain's state transition extremely challenging. These issues highlight the need for a comprehensive transformation to align Ethereum’s existing infrastructure with zero-knowledge technologies.
Solution “Beam Chain”: Reimagining Ethereum’s Consensus Layer
On November 12, 2024, during his presentation at Devcon, Justin Drake introduced a proposal called "Beam Chain" aimed at fundamentally and comprehensively transforming Ethereum’s Consensus Layer. The Beacon Chain has been at the core of Ethereum’s network for nearly five years. However, during this period, there have been no major structural changes to the Beacon Chain. In contrast, technological advancements have progressed rapidly, far surpassing the static nature of the Beacon Chain.
In his presentation, Justin Drake emphasized that Ethereum has learned significant lessons over these five years in critical areas such as MEV understanding, breakthroughs in SNARK technologies, and retrospective awareness of technological mistakes. The designs informed by these new learnings are categorized into three main pillars: Block Production, Staking, and Cryptography. The following visual summarizes these designs and the proposed roadmap:
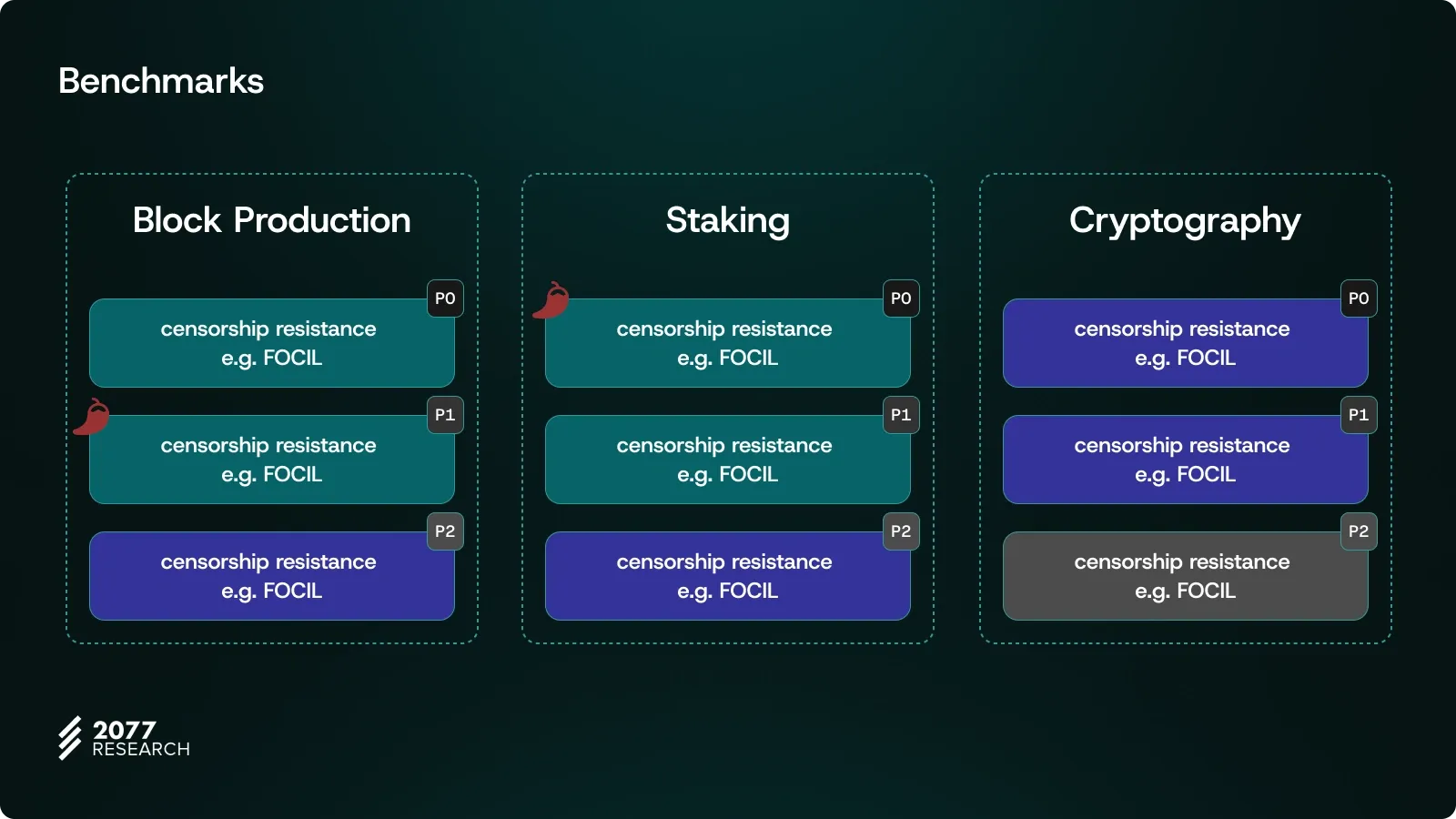
- Green and gray boxes represent incremental developments that can be implemented one by one each year. These types of improvements, much like previous upgrades, can be integrated step by step without disrupting Ethereum’s existing architecture.
- Red boxes, on the other hand, signify high-synergy, large-scale, and foundational changes that must be implemented together. According to Drake, these changes aim to advance Ethereum’s capacity and verifiability in one major leap.
In this section, we have examined The Verge’s Consensus, State, and Execution steps in detail, and one of the most prominent issues highlighted during this process is the use of the SHA256 hashing function in Ethereum’s Beacon Chain. While SHA256 plays a central role in ensuring the network's security and processing transactions, its lack of zk-friendliness poses a significant obstacle to achieving Ethereum’s verifiability goals. Its high computational cost and incompatibility with zk technologies make it a critical issue that must be addressed in Ethereum’s future developments.
Justin Drake’s roadmap, presented during his Devcon talk, envisions replacing SHA256 in the Beacon Chain with zk-friendly hash functions such as Poseidon. This proposal aims to modernize Ethereum’s consensus layer, making it more verifiable, efficient, and aligned with zk-proof technologies.
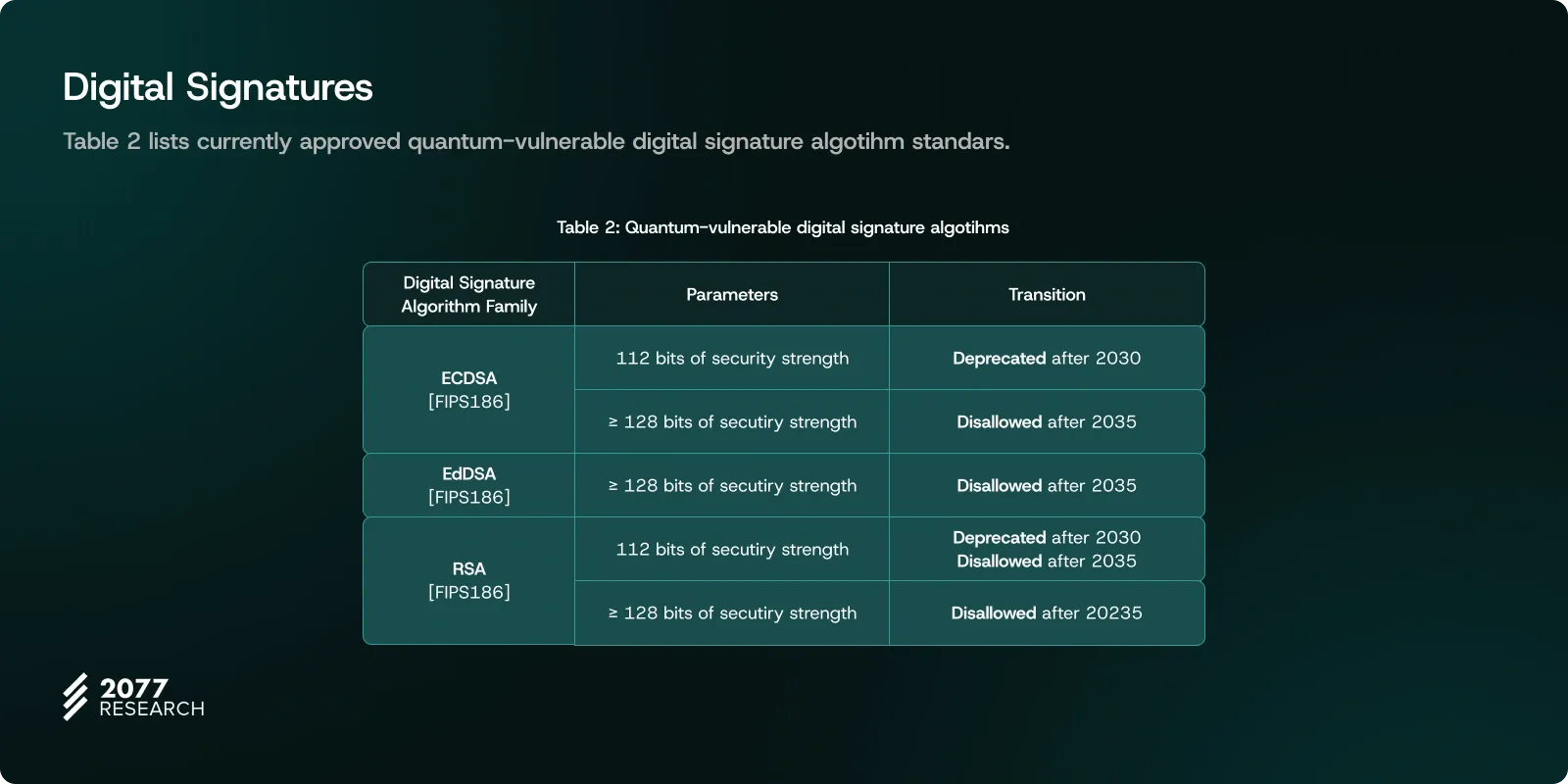
In this context, we see that Ethereum not only faces challenges with zk-unfriendly hash functions but also needs to reevaluate the digital signatures used in its consensus layer for long-term security. With the advancement of quantum computing, digital signature algorithms like ECDSA currently in use could face significant threats. As noted in the guidelines published by NIST, variants of ECDSA with a 112-bit security level will be deprecated by 2030 and completely banned by 2035. This necessitates a transition for Ethereum and similar networks toward more resilient alternatives such as quantum-secure signatures in the future.
At this point, hash-based signatures emerge as quantum-resistant solutions that could play a critical role in supporting the network’s security and verifiability goals. Addressing this need also removes the second major obstacle to making the Beacon Chain verifiable: BLS Signatures. One of the most significant steps Ethereum can take toward ensuring quantum security is adopting post-quantum solutions like hash-based signatures and hash-based SNARKs.
As Justin Drake emphasized in his Devcon presentation, hash functions are inherently resistant to quantum computers due to their reliance on pre-image resistance, making them one of the fundamental building blocks of modern cryptography. This property ensures that even quantum computers cannot efficiently reverse-engineer the original input from a given hash, preserving their security. Hash-based signature systems allow validators and attestors to generate signatures entirely based on hash functions, ensuring post-quantum security while also providing a higher level of verifiability across the network—especially if a SNARK-friendly hash function is used. This approach not only enhances the network’s security but also makes Ethereum’s long-term security infrastructure more robust and future-proof.
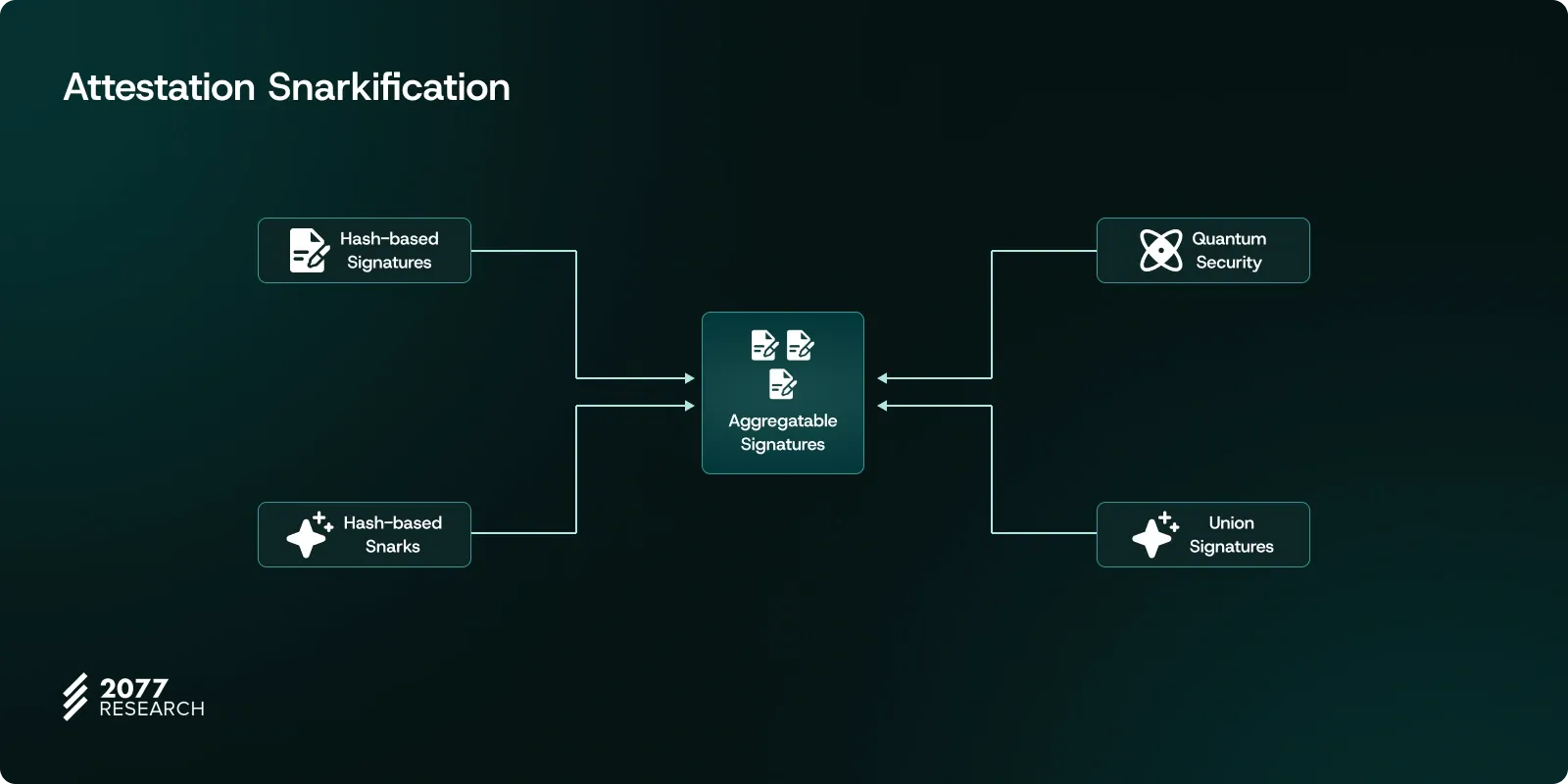
This system relies on combining hash-based signatures and hash-based SNARKs (STARK-like proofs) to create aggregatable signature schemes. Aggregatable signatures compress thousands of signatures into a single structure, reducing it to just a few hundred kilobytes of proof. This compression significantly decreases the data load on the network while greatly accelerating verification processes. For instance, the thousands of validator signatures produced for a single slot on Ethereum can be represented by a single aggregate signature, saving both storage space and computational power.
However, the most remarkable feature of this scheme is its infinitely recursive aggregation. That is, one group of signatures can be further combined under another group, and this process can continue across the chain. With this mechanism and considering future technological advancements, it’s fair to say that this opens the door to possibilities currently unachievable with BLS.
Final Thoughts and Conclusion
Ethereum's path to verifiability represents a fundamental shift in blockchain technology. The Verge initiative addresses core inefficiencies through Verkle Trees for state verification and STARK proofs for scalable transitions.
One of the most ambitious proposals is the Beam Chain, a comprehensive redesign of Ethereum's consensus layer. By addressing the limitations of the Beacon Chain and incorporating zk-friendly alternatives, this approach aims to enhance Ethereum's scalability while preserving its core principles of decentralization and accessibility. However, the transition also highlights the challenges Ethereum faces in balancing computational demands with its goal of maintaining a permissionless, inclusive network.
With NIST planning to phase out current elliptic curve cryptography by 2035, Ethereum must adopt quantum-resistant solutions like hash-based signatures and Poseidon. These solutions present their own efficiency trade-offs.
The use of STARKs in Ethereum's roadmap further emphasizes scalability and verifiability. While they excel in providing transparent and quantum-resistant proofs, their integration introduces challenges related to prover-side computational costs and small-data inefficiencies. These hurdles must be addressed to fully realize Ethereum's vision of statelessness and efficient block verification, ensuring the network remains robust in the face of increasing demand.
Despite these advancements, key challenges remain. Ethereum must navigate issues of zk-friendliness, consensus scalability, and the complexities of integrating quantum-resistant cryptography. Moreover, the backward compatibility of existing infrastructure poses practical hurdles that require careful engineering solutions to prevent disruptions to developers and users alike.
What sets Ethereum apart is not just its technical innovations but its iterative approach to solving some of the hardest problems in blockchain. The path forward—whether through technologies like Beam Chain, Verkle Trees, or STARK proofs—depends on a collaborative effort by developers, researchers, and the broader community. These advancements aren’t about achieving perfection overnight but about creating a foundation for a transparent, decentralized, and verifiable internet.
Ethereum’s evolution underscores its role as a critical player in shaping the Web3 era. By tackling today’s challenges with practical solutions, Ethereum moves closer to a future where verifiability, quantum resistance, and scalability become the standard, not the exception.



