
- Introduction
- EIP-7685 Specification
- What Does EIP-7685 Enable?
- Challenges and Considerations
- Conclusion
Introduction
Sometime long ago, there were no two blockchains forming Ethereum as we know it today, no Execution and Consensus layers running in parallel to each other. Only a single Proof-of-Work mining chain with the EVM. A bunch of node clients with Geth’s supermajority, and lots of GPU and ASIC implementations of Ethash mining algorithm. Times were different back then.
When Ethereum launched in 2015, it revolutionized the blockchain landscape by introducing a global, decentralized computer capable of executing arbitrary code through smart contracts. Like its granddad Bitcoin, Ethereum initially relied on Proof-of-Work consensus to secure the network and validate transactions. In the PoW model, miners competed to solve complex mathematical puzzles, with the winner earning the right to propose the next block and receive the associated block reward.
This consensus mechanism had several advantages, but high energy consumption, centralization risks, and scalability limits made the necessity in migrating apparent. No wonder—the Ethereum community began exploring alternatives to PoW as early as 2014! However, transitioning a live, high-value network from PoW to PoS was an unprecedented challenge. The solution? A phased approach that would eventually culminate in “The Merge.”
On December 1, 2020, the Ethereum community launched the Beacon Chain, better known as the Consensus Layer, marking the birth of the new era for Ethereum. This new chain introduced several critical components:
- Proof-of-Stake consensus: Validators could stake 32 ETH to participate in block production and validation.
- Epoch-based finality: The Casper FFG (Friendly Finality Gadget) provided stronger finality guarantees.
- Validator management: Systems for managing validator entries, exits, and slashing.
Importantly, the Beacon Chain operated alongside the original Ethereum PoW chain, without processing transactions or smart contract interactions. Its primary purpose was to build and test the PoS consensus mechanism in a live environment, along with forming a large enough stake to make PoS Ethereum as secure as the PoW one since day 0.
After years of development and testing, Ethereum executed “The Merge” on September 15, 2022. This historic event marked the fusion of the original Ethereum execution layer (EL) with the Beacon Chain consensus layer (CL). The Merge brought immediate benefits, including a dramatic reduction in energy consumption, decreased ETH issuance due to the removal of PoW mining rewards, and laid the groundwork for upcoming scaling solutions like danksharding.
While The Merge was undoubtedly a triumph, it also introduced a new architectural paradigm that the Ethereum ecosystem is still adapting to. The separation of concerns between the execution layer (handling state transitions and smart contract execution) and the consensus layer (managing validators and block production) brought new challenges and opportunities. This separation improved modularity, enhanced security through stronger finality guarantees, and provided flexibility for future upgrades. However, it also introduced new complexities, particularly in how the two layers communicate and coordinate.

From the technical perspective, the Paris upgrade, that included The Merge, simply delegated execution blockchain’s fork choice to the CL, making EL fully dependent to it, but not exactly vice versa. Specifically, while deposits to the CL existed even before the launch of CL, withdrawals of ETH from validators’ accounts were still not possible even after The Merge!
The rise of smart contract-controlled validators has created demand for more flexible, programmable interactions between the execution and consensus layers. This is where EIP-7685 enters the picture. By proposing a generalized framework for passing requests from the execution layer to the consensus layer, EIP-7685 aims to unlock new possibilities for cross-layer interactions.
EIP-7685 Specification
EIP-7685 introduces a generalized framework for the transmission and storage of Execution Layer (EL) initiated requests to the Consensus Layer (CL). This proposal aims to standardize cross-layer communication, enabling more flexible and programmable interactions between the two layers. The key components of this proposal are as follows:
Request Format
request = request_type ++ request_dataThe request_type is a single byte identifier, followed by an opaque byte array of request_data. The term “opaque” indicates that the validity of the byte array depends on its type. For instance, a request type of 0x00 would be validated according to the logic specific to that type. This approach makes the framework agnostic to the encoding and validation rules of specific request types, allowing for flexibility in implementation.
The single byte identifier permits up to 256 request types, which is likely sufficient for an extended period. If necessary, future iterations could replace the single byte identifier with LEB128 to further extend this limit.
 LEB128 (varint) integer encoding. I stole this picture from the internet.
LEB128 (varint) integer encoding. I stole this picture from the internet.
This request will then be read, and if correct, executed, by the CL. These requests are atomic and synchronous, which means that they’re processed in the order they were submitted. This differs from, for example, today’s validator deposit logic, where the actual deposit is only finalized when the Merkle proof of deposit is revealed on the CL, and may not be revealed in the order it was performed.
Block Body RLP Encoding
block_body_rlp = rlp([
field_0,
...,
field_n,
[request_0, ..., request_k],
])The list of requests is appended as the last field in the block body, similar to how the block body stores transactions and withdrawals in a list.

Requests Root Computation
def compute_trie_root_from_indexed_data(data):
trie \= Trie.from(\[(i, obj) for i, obj in enumerate(data)\])
return trie.root
block.header.requests*root \= compute_trie_root_from_indexed_data(block.body.requests)As opposed to the block body, block headers only store the _Merkle roots* of enumerated data, expressed as a Merkle tree. For example, instead of storing transactions and withdrawals, block headers contain “transactionsRoot” and “withdrawalsRoot” fields, 32 bytes (the size of a hash) each. Request array is not unique in this regard – its field in the block header is replaced with a Merkle root of the array expressed as a tree, “requestsRoot.”
A refresher on Merkle trees
Imagine you have a large array of data — transactions, withdrawals, requests, foot pics, whatever. For each new element in your array, you create a hash, which (as you must already know) is a unique fingerprint for digital information.
Now, picture taking pairs of these transaction hashes and combining them to create a new hash. You continue this process, pairing up hashes and creating new ones, until you end up with just one hash at the top. This structure resembles an upside-down tree, which is why it’s called a Merkle tree. The single hash at the very top of this tree structure is called the Merkle root. It’s special because it represents a summary of all the transactions in your big book.

This system is useful for two main reasons. First, it’s a quick way to check if anything in your array has been changed, as even a tiny alteration in any element in the array will change the Merkle root. Second, it allows you to prove that a specific transaction is in your book without showing the entire book.
A Merkle proof is like a trail of breadcrumbs from a specific element all the way up to the Merkle root. It includes just enough information to recreate the path up the tree without needing to see all the other elements, only the neighboring ones in every step of the tree. If someone wants to verify that an element is in your array, they only need the element itself, the Merkle proof (the trail of breadcrumbs), and the Merkle root. They can then follow the trail, recreating the hashes along the way, to see if they end up with the same Merkle root. If they do, it proves the element is in the book.

Blockchains utilize Merkle trees very often for this exact purpose.
Who Creates the Requests?
This is a very interesting part. As I’ve previously mentioned, EIP-7685 is a generalized framework. In the other words, it specifies no specific actions, such as deposits, withdrawals, etc. It only creates a bunch of structures and logic to efficiently process such requests in a way that doesn’t overcomplicate Ethereum’s codebase. Or, even simpler, it creates a convenient interface for other EIPs to create new types of requests.
Let’s take a look at two most popular EIPs powered by EIP-7685 — Deposit requests (EIP-6110), and withdrawal requests (EIP-7002). As the name suggests, they allow initiating deposits and withdrawals from the Execution Layer. You may even notice the “Requires: EIP-7685” line at the beginning of the page. However, they weren’t always using the request standard. Moreover, as can be noticed from their numbers, they were created even before EIP-7685!
Initially, EIP-6110 used the similar logic applied by requests. Deposit information has its own RLP format, block bodies store deposits, block headers contain deposit roots.
 Screenshot of an old version of EIP-6110 from late 2022
Screenshot of an old version of EIP-6110 from late 2022
So, instead of requests array and root and a unified logic for all requests, it only had logic for deposits. And… EIP-7002, implementing execution layer triggerable withdrawals, had the exact same logic, but in the separate fields.
 Screenshot of an old version of EIP-7002 from a year ago
Screenshot of an old version of EIP-7002 from a year ago
If these two were finalized and implemented in Ethereum, we’d have two separate fields in both block headers and bodies, and separate, but nearly identical logic in the codebase. Now imagine that we’d also want to implement validator aggregation logic as a part of EIP-7251, withdrawal credentials reconfiguration, or whatever we’d ever need to trigger from the EL for our applications. The structure of Ethereum blocks would become too large and unnecessarily complicated.
EIP-7685 proposes a universal approach. All EL-triggered requests are saved in the single array and referenced in the single requests root in the block header. All requests are read and executed synchronously by the CL. We can implement up to 256 (or however many, if we’re willing to replace type byte with Base-128 in the future) request types under a single interface, in respect to forward-compatibility.
Now, let’s see how these two most popular EIP-7685-based proposals utilize requests.
EIP-6110
Instead of allowing deposits from any smart contract with the code hash of the specified deposit contract, EIP-6110 hard-codes 0x00000000219ab540356cbb839cbe05303d7705fa (the most popular staking deposit contract) as the only canonical staking deposit contract. The code of the canonical deposit contract implements a “DepositEvent” with all the necessary information to process the deposit, except the Merkle proof.
 An example from a typical transaction to that contract
An example from a typical transaction to that contract
For every log emitted by that smart contract, there’s initiated a “deposit request” with a 0x00 type. They’re initiated in the order of logs, and as all requests are processed synchronously on the CL, all deposits become synchronous and atomic. Also, the lack of asynchronous deposit verification allows obsoleting the validator poll, currently taking ~12 hours, thus the only delay left to process deposits on the CL is an epoch finality, or about 13 minutes.

EIP-7002
Currently, the Ethereum validator is essentially operated by two keys — the active BLS key, used to attest to blocks, propose, and perform other validator duties, and the withdrawal credential, or EL address — the one where withdrawn ETH go. The active key cannot change the withdrawal credential, thus when it’s set, the ETH “owned” by the validator is actually owned by the one holding the keys for the withdrawal address.
This relationship makes a lot of sense when we want to separate the one providing capital for stake and the one who performs validator duties with this stake. That is, staking pools, Staking-as-a-Service, or, at the end of the day, your friend who’s willing to manage your validator because you constantly travel. However, the actual withdrawal cannot be initiated by the withdrawal address, only by the active key. This can lead to security risks. For example, the one holding the withdrawal keys can keep staked ETH hostage, say, in exchange for a large share of the stake. Or, if the active key is lost, the stake it operates is lost as well.
EIP-7002 proposes to change this by implementing a withdrawal request, under type 0x01, initiated by the withdrawal address. To create the request, the withdrawal address calls the 0x00A3ca265EBcb825B45F985A16CEFB49958cE017 smart contract with the validator public key and the asked withdrawal amount. The smart contract calculates a fee (used to rate-limit the withdrawals) and queues the withdrawal. At the end of the block, the system address initiates a call to the smart contract that collects all the withdrawals from the queue and transmits them to the CL off-chain.
Such logic is especially useful for decentralized staking pools that currently rely on the assumption that its validators will not hold their stake hostage and will correctly perform all withdrawals requested by the pool. After this upgrade, the smart contracts operating the pool will be able to withdraw the stake themselves in case of a misbehavior or poor performance of the validator.
Future EIPs that utilize EIP-7685’s requests might implement other logic that creates the actual requests. I’m guessing that we might see an EIP for validator aggregation requests to make post-7251 aggregation more convenient than lots of withdrawal->deposit actions, and more. Some might implement direct creation of requests in the EVM, some would prefer 7002’s system call approach, etc. This remains at the discretion of creators of the EIPs. What EIP-7685 proposes is rails to build CL-EL interoperability solutions with a convenient and minimalistic interface that doesn’t bring unnecessary complexity to the Ethereum’s codebase and adheres to the roadmap’s The Purge line.
What Does EIP-7685 Enable?
Let’s take a look at two most popular decentralized staking protocols — Lido and Rocket Pool — and speculate how their architectures can be upgraded using EIP-7685.
Lido: Now
Lido has established itself as a prominent decentralized liquid staking protocol on the Ethereum network. The protocol’s design aims to balance decentralization with efficient staking management, enabling users to participate in Ethereum staking without the need for direct validator operation. It supports multiple staking modules, but the first, and by far the most popular one, is a Curated Module, which we’ll cover.
At the heart of Lido’s operations is the Lido Decentralized Autonomous Organization (DAO), which plays a crucial role in the protocol’s governance and operational decisions. One of the DAO’s primary responsibilities is the selection and management of professional node operators. These operators are entrusted with the task of running validator nodes using ETH deposited by users. In return for their deposits, users receive stETH, Lido’s liquid staking token, which represents their staked ETH plus accrued rewards.
As of the time of writing, the Lido CM is under the stewardship of 39 node operators. This group includes several prominent entities in the Ethereum ecosystem, such as Everstake, Nethermind, and Figment. The inclusion of well-known and reputable operators adds a layer of trust and expertise to Lido’s operations, enhancing the protocol’s credibility within the wider Ethereum community.

The withdrawal process in Lido’s current implementation is initiated on-chain. When the system determines that a withdrawal is necessary, perhaps due to users wanting to unstake their ETH, it expresses this intent through on-chain mechanisms. Node operators, who are bound by the protocol’s “Validator Exits Policy,” are then expected to execute these withdrawal intents promptly using their validator keys.
However, it’s important to note that these withdrawals are not enforced through on-chain mechanisms. This limitation stems from the current inability to initiate Consensus Layer (CL) actions directly from Execution Layer (EL) smart contracts. As a result, the system relies heavily on the cooperation and compliance of node operators to process withdrawals in a timely manner.
In cases where an operator fails to comply with withdrawal intents, Lido has implemented a governance mechanism to address such situations. The DAO has the power to vote on the removal of non-compliant operators from the system. If such a vote passes, the operator in question is prevented from receiving new deposits, effectively limiting their role in the protocol. However, this mechanism has its limitations. Even if an operator is removed, the system cannot forcibly recover the operator’s existing funds until they voluntarily initiate the withdrawal or face slashing penalties on the Consensus Layer.
Lido’s smart contract receives information about validators balances, withdrawals, and their violations through an oracle system. Nine operators are elected to share data about CL’s state to the smart contracts on EL. Smart contracts consider the data valid after a 5/9 threshold. Therefore, the system relies on 5/9 trusted operators to operate. If they act maliciously, the DAO can override oracle’s output and re-elect the operators. Nevertheless, such an operation would require extensive coordination from the community and will likely result in a successful attack, in case there’s one.
Besides withdrawals, the lack of programmable deposit rules introduces a vulnerability that lets the node operator front-run the Lido’s deposits with 1 ETH deposit with withdrawal credentials different from those specified by Lido. Lido prevents this by introducing a “Deposit Security Committee,” members of which are authorized to allow or veto deposits if they detect a front-run attempt. This is because currently, deposits to the CL are handled from the CL and not the EL, making them asynchronous and thus allowing for front-running.

The current implementation of Lido, while innovative and largely successful, faces several challenges stemming from the limitations of Ethereum’s architecture. These challenges include the reliance on operator compliance for withdrawals, the potential vulnerabilities in the oracle system, and the need for additional security measures in the deposit process. However, the introduction of EIP-7685 and related proposals could potentially address many of these issues, paving the way for a more efficient and decentralized implementation of Lido.
Lido: Post-7685
The proposed implementation of EIP-7685, along with related Ethereum Improvement Proposals, has the potential to significantly enhance Lido’s architecture and operations. These changes could address many of the current limitations and vulnerabilities, leading to a more robust, efficient, and decentralized protocol.
One of the most significant improvements that EIP-7685 could bring to Lido is in the realm of withdrawals. EIP-7002, powered by EIP-7685, enables the initiation of withdrawals directly from validator-specified credentials. This capability would allow Lido’s smart contracts to automate the process of withdrawing ETH from staking, effectively eliminating the current reliance on node operators for this critical function.
The implications of this change are far-reaching. Currently, Lido’s withdrawal process can take up to 24 hours, as it depends on node operators executing withdrawal intents in compliance with the protocol’s policies. With the implementation of EIP-7685, these withdrawals could potentially be executed near-instantaneously. This dramatic reduction in withdrawal times could significantly enhance the liquidity of stETH, Lido’s liquid staking token, potentially improving its parity with ETH on secondary markets.
Furthermore, the automation of withdrawals addresses one of the key trust assumptions in Lido’s current model. By removing the need for operator intervention in the withdrawal process, the protocol reduces the risk of operators failing to comply with withdrawal requests, whether due to negligence or malicious intent. This change aligns perfectly with Lido’s goal of increasing decentralization and reducing reliance on trusted parties.

Another area where EIP-7685 and related proposals could bring substantial improvements is in the deposit process. EIP-6110, which is also facilitated by EIP-7685, introduces a synchronous deposit logic to Ethereum. This change has significant implications for Lido’s operations, particularly in terms of deposit security.
In the current asynchronous deposit model, there’s a risk of front-running Lido’s deposits. An attacker could potentially submit a 1 ETH deposit with different withdrawal credentials just before Lido’s deposit, effectively hijacking the pool’s funds. To prevent this, Lido currently relies on its Deposit Security Committee to veto and approve deposits.
With the introduction of synchronous deposits, this attack vector is effectively eliminated. Deposits would be processed in the order they’re submitted, making it impossible for an attacker to front-run Lido’s deposits. This change could potentially render the Deposit Security Committee obsolete, removing a centralized component from Lido’s architecture and further aligning the protocol with its decentralization goals.
The oracle system, another critical component of Lido’s current implementation, could also see significant improvements with the introduction of EIP-7685. The framework opens up new possibilities for fetching oracle information using requests initiated from the Execution Layer. This capability could potentially minimize or even eliminate the need for the current centralized oracle system.
Another significant improvement that could be enabled by EIP-7685 relates to validator management, particularly in light of the proposed EIP-7251. This proposal, which is projected to be implemented in the next Pectra upgrade alongside EIP-7685, aims to increase the maximum effective stake per validator entity to 2048 ETH. This change is designed to reduce the number of validator keys operated by large staking pools by up to 64 times, significantly decreasing the load on the Ethereum network and potentially paving the way for improvements like Single-Slot Finality in Ethereum’s consensus mechanism.
However, the migration to post-7251 validators presents a significant challenge for large staking pools like Lido. With its current count of approximately 306,000 active validators at the time of writing, Lido would face a monumental task in consolidating these validators to align with the new maximum stake limit. Under current Ethereum constraints, with a churn limit of 8 deposits and withdrawals per epoch, this consolidation process could take up to 190 days. Such a prolonged process would significantly impact Lido’s operational efficiency and could potentially disincentivize the protocol from undertaking the consolidation effort.

This is where the capabilities introduced by EIP-7685 could prove invaluable. The proposal could enable the implementation of a new type of request specifically designed for validator consolidation. This consolidation request would allow for the automatic and synchronous combination of validators without the delays currently incurred by the withdrawal and subsequent deposit process.
The introduction of such a consolidation request would dramatically streamline the process of adapting to the new validator stake limits proposed in EIP-7251. Instead of a months-long process of withdrawals and deposits, Lido could potentially consolidate its validators much more quickly and efficiently. This would not only ease the transition to the new validator stake limits but also allow Lido to more quickly realize the benefits of operating fewer, larger validators, such as reduced operational complexity.
It’s worth noting that while the consolidation request enabled by EIP-7685 might be primarily useful during the transition period following the implementation of EIP-7251, its inclusion in the Ethereum protocol could prove valuable for future upgrades as well. If, for instance, the maximum effective balance (MaxEB) for validators is increased further in the future, having an established mechanism for efficient validator consolidation would greatly ease the transition process for large staking pools like Lido.

By enabling automated withdrawals, Lido could significantly enhance the liquidity and efficiency of its staking operations. The introduction of synchronous deposits could eliminate the need for centralized deposit security measures, aligning the protocol more closely with its decentralization goals. Improvements to the oracle system could reduce reliance on trusted parties for critical state information. Finally, the ability to efficiently consolidate validators would allow Lido to adapt more easily to changes in Ethereum’s validator specifications, ensuring the protocol’s continued efficiency and competitiveness in the evolving landscape of Ethereum staking.
Rocket Pool: Now
Rocket Pool has established itself as a pioneering force in the realm of decentralized Ethereum staking protocols. The protocol’s primary objective is to democratize participation in Ethereum’s Proof of Stake consensus mechanism by significantly lowering the entry barriers for individual stakers. Simultaneously, Rocket Pool aims to offer a more decentralized alternative to the centralized staking services that have become prevalent in the ecosystem.
At the heart of Rocket Pool’s innovation is its unique approach to node operation. The protocol allows individuals to become node operators with just 8 ETH, significantly less than the standard 32 ETH requirement. This reduced capital requirement is made possible through Rocket Pool’s novel system where the remaining 24 ETH is provided by the protocol from a pool of user deposits. This mechanism not only lowers the barrier to entry for node operators but also creates a symbiotic relationship between node operators and ETH depositors, aligning their interests in the protocol’s success.
For users who prefer not to run a node themselves, Rocket Pool offers a seamless staking experience. These users can deposit any amount of ETH (with a minimum of 0.01 ETH) and receive rETH in return. rETH is Rocket Pool’s liquid staking token, representing the user’s staked ETH plus any accrued rewards. This liquid staking token allows users to maintain liquidity while participating in Ethereum staking, as rETH can be traded or used in various DeFi applications.
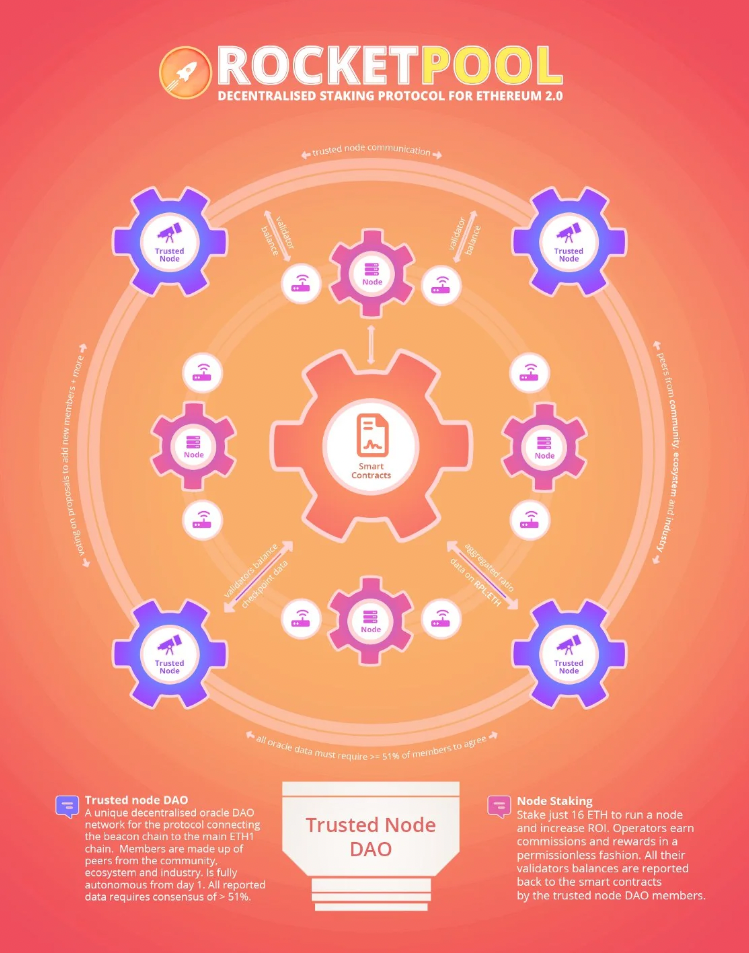
To ensure the accuracy and reliability of staking data, Rocket Pool employs a decentralized oracle network. Unlike some other staking protocols that use permissioned oracles, Rocket Pool’s oracle nodes operate on a permissionless basis. Anyone can run an oracle node by staking a sufficient amount of RPL, Rocket Pool’s native governance token. This approach to oracle operation aligns with Rocket Pool’s commitment to decentralization, as it removes any central authority from the critical function of reporting staking rewards and other protocol operations.
The protocol uses data from these oracle nodes to manage several crucial functions. First and foremost, the oracle data is used to redistribute staking rewards accurately among participants. Additionally, this data plays a vital role in identifying and penalizing any misbehavior within the network. By leveraging a decentralized network of oracles, Rocket Pool aims to ensure that these critical functions are performed in a transparent and trustless manner.
However, like many staking protocols in the current Ethereum landscape, Rocket Pool faces certain limitations when it comes to managing validator exits and withdrawals. In its current implementation, Rocket Pool cannot automatically withdraw stake from validators. Instead, the protocol relies on voluntary exits initiated by node operators or on slashing events triggered by the Ethereum network in cases of validator misbehavior.
To mitigate the risks associated with this reliance on voluntary exits, Rocket Pool implements a system of RPL bonds. Node operators are required to stake RPL as collateral, which serves as a form of insurance for the protocol and its users. In the event of slashing or other penalties, these RPL bonds can be used to cover losses. Currently, the RPL bonds are designed to cover up to approximately 10% of the stake lost in case of misbehavior by validators.
This bonding mechanism provides a layer of security for the protocol, particularly in cases of slashing. Under normal circumstances, the maximum slashing amount is 1 ETH, while the typical RPL bond is around 2.4 ETH in value. This over-collateralization ensures that the protocol and its users are protected against standard slashing events.
However, it’s important to note that this bonding mechanism has its limitations. While it provides robust protection against slashing events, it offers limited coverage in scenarios where a node operator might attempt to withhold the entire stake by never initiating a withdrawal. In such extreme cases, the RPL bond would only cover about 10% of the total stake at risk.

Rocket Pool: Post-7685
The proposed implementation of EIP-7685, along with related Ethereum Improvement Proposals, has the potential to significantly enhance Rocket Pool’s architecture and operations. These changes could address several of the current limitations and further strengthen the protocol’s commitment to decentralization and security.
Currently, Rocket Pool, like Lido and all the other staking protocols, cannot force honest withdrawals from its validators. The protocol relies on the assumption that the collateral provided by validators in the form of RPL bonds will be sufficient to cover potential losses from misbehavior. While this system provides reasonable protection against slashing events, it faces limitations when confronted with more extreme scenarios.
As we’ve calculated earlier, in the current model, if a node operator were to attempt to attack the pool by never withdrawing the stake, the RPL bond would only cover at most 10% of the total validators’ stake. This scenario, while unlikely, represents a potential vulnerability in the system that could, in theory, be exploited by malicious actors.
The implementation of EIP-7685 could fundamentally change this dynamic. With the new capabilities introduced by this proposal, Rocket Pool’s smart contracts would gain the ability to initiate withdrawals themselves, without relying on the cooperation of node operators. This change would effectively eliminate the risk of node operators holding stakes hostage or refusing to process withdrawals.
Moreover, this change could potentially allow Rocket Pool to reconsider its collateral requirements. Currently, the protocol requires node operators to provide substantial RPL bonds as a security measure. These bonds serve as insurance against potential misbehavior, including failure to process withdrawals. However, with the ability to automate withdrawals at the smart contract level, the risk profile of node operation changes significantly.
In light of these changes, Rocket Pool’s decentralized autonomous organization (DAO) might consider reducing the minimum stake required from node operators. The current requirement of 8 ETH plus a substantial RPL bond (typically around 2.4 ETH in value) could potentially be lowered to as little as 1 ETH - the minimum amount needed to cover potential slashing penalties.

Such a reduction in the minimum stake would have profound implications for the accessibility and decentralization of the protocol. By lowering the capital requirements for node operators, Rocket Pool could attract a larger and more diverse set of participants to run nodes. This increased accessibility could lead to a more decentralized and robust network of node operators, further enhancing the protocol’s resilience and decentralization.
The potential to lower the entry barrier for node operators aligns perfectly with Rocket Pool’s mission to democratize access to Ethereum staking. Just as the protocol has made staking accessible to users with as little as 0.01 ETH, these changes could make node operation accessible to a much broader range of participants. This could potentially lead to a significant increase in the number of independent node operators in the Rocket Pool ecosystem, enhancing the protocol’s decentralization and potentially increasing its share of the overall Ethereum staking market.
Concept: ZK Staking Pool
The Dencun upgrade that took place in March 2024 included EIP-4788. It enabled an EVM smart contract that stores canonical Consensus Layer’s block roots. Block roots in the CL are Merkle roots. This means that it’s possible to create a Merkle proof that certain data exists in the block without revealing all the other data. Specifically, block roots “contain” information about attestations, slashings, proposals, etc.
 Specification of the beacon root smart contract
Specification of the beacon root smart contract
We can utilize this to automatically fetch information about efficiency of the validators in our imaginary decentralized staking pool. Let’s do some lowkey napkin math. To perform that, we’d need to reveal state root from the block root (~2000 gas) and do a Merkle proof verification against the CL state root to get the validator’s account (2*log2 1_000_000 = 40; 40*(60+12*(64/32))+40*32*16 = ~23840 gas). This is ~$0.78 at ETH price of $3000 and 10 gwei gas price. We’ll need to do this every period we want to update the state for our pool, ideally every block. Considering one validator earns ~$0.02-0.05 per an attestation, this becomes unviable.
However, it’s not yet over. We can use zero-knowledge proofs to perform offchain verifiable computations over the entire dataset of the CL state to find balances and other useful information about all our validators no matter how many there are, at the cost of one proof or even less. Generally speaking, I expect you, the reader, to already have at least a basic understanding of what ZK proofs are, as otherwise you’d unlikely get to such a complicated EIP deep dive. Nevertheless, let’s do a quick recap on them:
Imagine you’re trying to prove something about a massive jigsaw puzzle without showing the entire puzzle. With traditional methods, as the puzzle gets bigger, it becomes more time-consuming and difficult to verify. Zero-knowledge proofs, however, allow you to prove properties about the whole puzzle while only showing a small, constant-sized piece of evidence. This is incredibly useful in systems that deal with large amounts of data, like blockchains or big databases.
ZK coprocessing, which is technically what we’re going to utilize here, is like having a specialized helper that can perform complex calculations quickly and efficiently. In our everyday computers, we have graphics cards that are really good at handling visual tasks, separate from the main CPU. Similarly, in some systems using zero-knowledge proofs, there are some tasks that can be offloaded to these coprocessors without overloading the main part of the system.

As the Execution Layer has access to these roots, it’s possible to generate ZK proofs of validators’ attestations and slashings and verify them using these roots. We can use this to efficiently calculate the efficiency of certain validators and detect if they were slashed. As I mentioned, it’s possible to verify Merkle proofs of CL data without ZK, but at our scale and required frequency that would be too gas-expensive on the Ethereum L1, which is not the case with ZK. Then, we accumulate ETH in the smart contract, distribute it to professional bonded node operators, and decentralized staking pool is done.
Modern ZK proof systems such as Plonky3 allow performing large computations over lots of data relatively fast. By utilizing them, we can greatly reduce the onchain costs and thus make fully onchain processing of validator information viable. Moreover, we can adopt proof aggregation systems that aggregate ZK proofs in a single cheap-to-verify proof, such as Nebra UPA, which would reduce the costs even further, up to less than the ZK-less gas costs per 1 validator we mentioned earlier.

However, even though we fully eliminated the need for oracles, we still have to trust those operators to correctly process withdrawals. This is where EIP-7685 comes into play. By utilizing requests, we can manage operators’ validators from the same smart contracts we dump their information into. If a validator has poor efficiency or got slashed, withdraw their funds, and calculate their penalty in accordance with the CL data, with no oracles or trusted points.
This can be improved further by distributing validator entities to multiple operators using Distributed Key Generation (DKG). This way, validator downtime and efficiency problems are minimized, and the stakers of the pool can get the maximum possible yield with no risk of losing their funds to dishonest actors. Node operators, in turn, would be able to manage validators with as little as 0.1 ETH and even less. The practice of running validator entities with multiple operators is not new. It’s called Decentralized Validator Technology (DVT), and projects such as Obol and SSV are already rolling out their DVT solutions.

To summarize, EIP-7685 is a last piece of the puzzle for fully decentralized and trustless staking protocols, which, in their perfect state, could potentially allow people to run their own validator nodes with a tiny stake and perfect efficiency.
Challenges and Considerations
Request Processing
One of the primary challenges lies in the realm of request processing, stemming from the fundamental differences between the Execution Layer (EL) and Consensus Layer (CL). These two layers, forming the backbone of Ethereum’s current architecture, were developed at different times and with distinct design philosophies.
For example, the EL, evolving from Ethereum’s original architecture, uses Keccak256 as its primary hash function and Recursive Length Prefix (RLP) encoding for data serialization. In contrast, the CL employs SHA256 for hashing and Simple Serialize (SSZ) for data encoding. Such differences present a significant challenge for facilitating seamless communication between the two layers. The divergence in design choices reflects the evolving understanding of blockchain architecture and the specific requirements of each layer. The EL, focusing on smart contract execution and state management, benefits from the efficiency of Keccak256 and RLP. The CL, prioritizing fast block processing and efficient light client proofs, leverages the strengths of SHA256 and SSZ, and so on.
Bridging these two worlds efficiently and in a forward-compatible manner has been an ongoing challenge in Ethereum’s development. EIP-7685, with its proposal for a generalized framework for cross-layer requests, steps directly into this complex landscape. The challenge lies not just in enabling communication between these disparate systems, but in doing so in a way that preserves the strengths and security properties of both layers.
However, the designers of EIP-7685 have been mindful of these challenges. The proposal aims to create a flexible framework that can accommodate the differences between the layers. For instance, it allows for the use of different serialization formats for different request types, potentially enabling the use of SSZ and other encodings for request data when appropriate.
Backward Compatibility
Another significant consideration in the implementation of EIP-7685 is backward compatibility. While Ethereum’s upgrade process typically relies on hard forks, which allow for breaking changes to the protocol, the impact of these changes on existing infrastructure and applications cannot be overlooked.
Decentralized staking pools, for instance, have built complex systems around the current limitations of cross-layer communication in Ethereum. They rely on mechanisms like oracle networks, bonded node operators, and sophisticated governance systems to manage the gap between the Execution and Consensus layers. The introduction of EIP-7685 and its derivatives could render many of these systems obsolete or inefficient.
For a decentralized staking pool to fully leverage the capabilities introduced by EIP-7685, it may need to undertake a significant redesign of its core architecture. This could involve rewriting smart contracts, redesigning governance mechanisms, and reconsidering economic models. Such changes would require extensive development effort, rigorous auditing, and careful testing to ensure they don’t introduce new vulnerabilities or inefficiencies.
The transition to new architectures leveraging EIP-7685 capabilities may not be straightforward. Many of these protocols are governed by decentralized autonomous organizations (DAOs), which may be hesitant to approve radical changes to tried-and-tested systems. The conservative nature of many DAOs, while generally beneficial for protocol security, could slow down the adoption of new capabilities introduced by EIP-7685.
EIP-6110
Specific challenges lie in the proposals on top of EIP-7685 as well—for example, the implementation of deposit requests as described in EIP-6110. This proposal, as we’ve previously mentioned, aims to change how deposits to the Consensus Layer are processed. However, its current specification raises some potential concerns about backward compatibility and ecosystem impact.
EIP-6110 proposes to specify a single, canonical smart contract address for processing deposits, rather than allowing deposits from any contract deployment with the canonical deposit contract code, as it is today. While this approach greatly simplifies the implementation of the proposal, it could have unintended consequences for projects that have built systems around alternative deposit contracts.
If the old Merkle proof-based deposit mechanism were to be deprecated following the implementation of deposit requests, projects using non-standard deposit contracts could face difficulties. They would need to rewrite their codebase to use the new, canonical deposit contract, or risk the loss of funds, as their current deposit mechanism would otherwise cease to work.
One potential mitigation strategy would be to maintain the old deposit logic in parallel with the new request-based system, at least for a transitional period. This would allow projects time to adapt to the new system while ensuring that existing applications continue to function. However, maintaining dual systems introduces its own challenges, including increased protocol complexity and potential confusion among users and developers.
Conclusion
EIP-7685 represents a significant step forward in the evolution of Ethereum’s architecture, particularly in bridging the gap between the Execution and Consensus layers. By introducing a generalized framework for cross-layer requests, this proposal has the potential to revolutionize how decentralized staking protocols operate, enhancing their efficiency, security, and trustlessness.
However, the implementation of EIP-7685 is not without challenges. The technical hurdles of bridging the disparate architectures of the Execution and Consensus layers, ensuring backward compatibility, and managing the transition for existing protocols and users are significant considerations. These challenges will require careful planning, extensive testing, and community-wide collaboration to overcome.
Despite these hurdles, the potential benefits of EIP-7685 make it a compelling development for Ethereum. As the ecosystem continues to evolve, proposals like EIP-7685 play a crucial role in realizing Ethereum’s vision of a more scalable, secure, and decentralized blockchain platform. The success of such initiatives will depend on the continued innovation, collaboration, and dedication of the Ethereum community.
Thank you for reading.